记一次讲故事机器人的开发-我有故事,让机器人来读
最近工作较忙 , 回家闲下来只想闭目休息 , 一分钟屏幕都不想再看 , 然而我又想追更之前看的小说 , 于是 , 需求来了——我需要一个给我讲故事的机器人!
浏览器或者阅读器App里其实也有朗读功能 , 但是比较僵硬 , 总是将引人入胜的情节念成流水账 , 分分钟让人弃坑 , 所以我考虑自己使用爬虫定时下载更新的章节 , 而后将文字合成存储到音频文件 , 这样不仅可以选择一个靠谱的语音合成工具来处理文字 , 而且保存下来的音频还能反复收听 , 一举两得 。
文本整合容易 , 但是如何将其快速转换成音频呢?难道要自己训练模型“炼丹”解决?no no, 费力不讨好 , 毕竟自己手头这点算法知识非常浅显 , 而且硬件条件也不允许 , 本着“能用就行”的原则 , 我决定先使用市面上开放平台的产品来解决 。 经过对比 , 发现有道智云的语音合成还不错(此处可体验) , 决定使用有道智云的语音合成API进行开发 。
效果先睹为快:我拿来朱自清先生的《荷塘月色》的其中两段作为实验素材 , 开发了简单的demo , 走通了从加载文本到生成音频文件的逻辑 , 下面我来详细介绍开发过程 。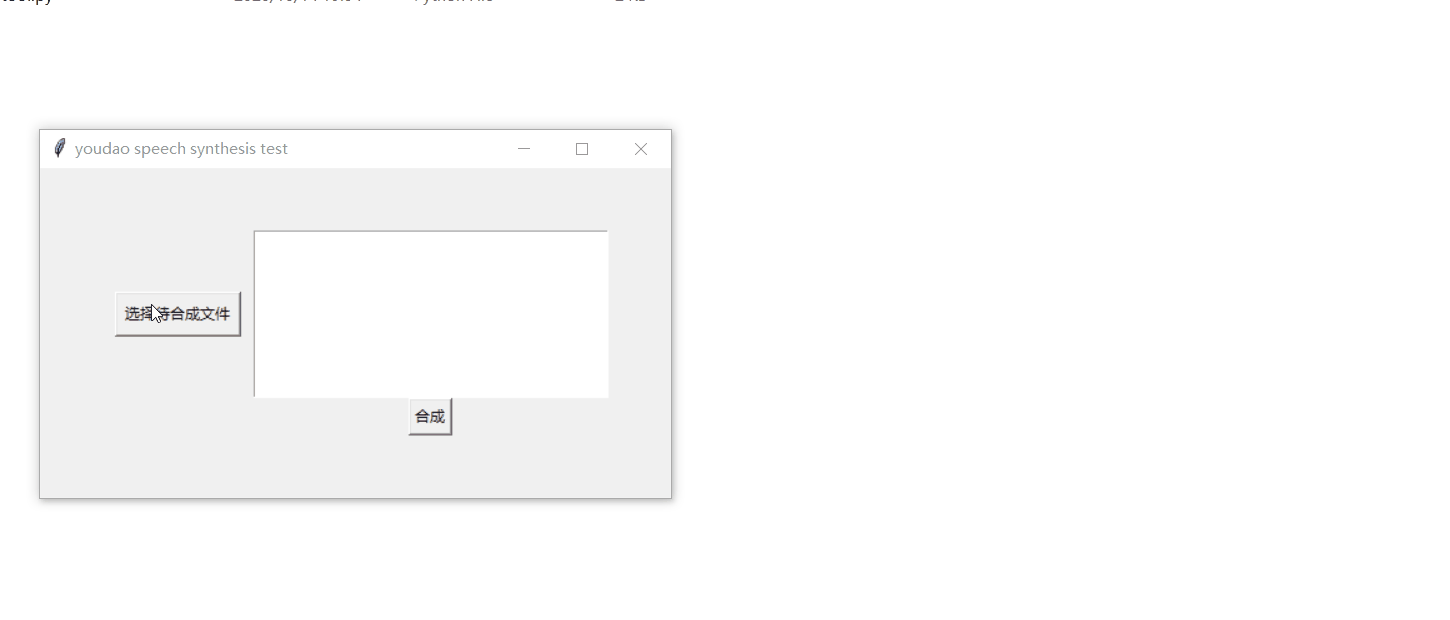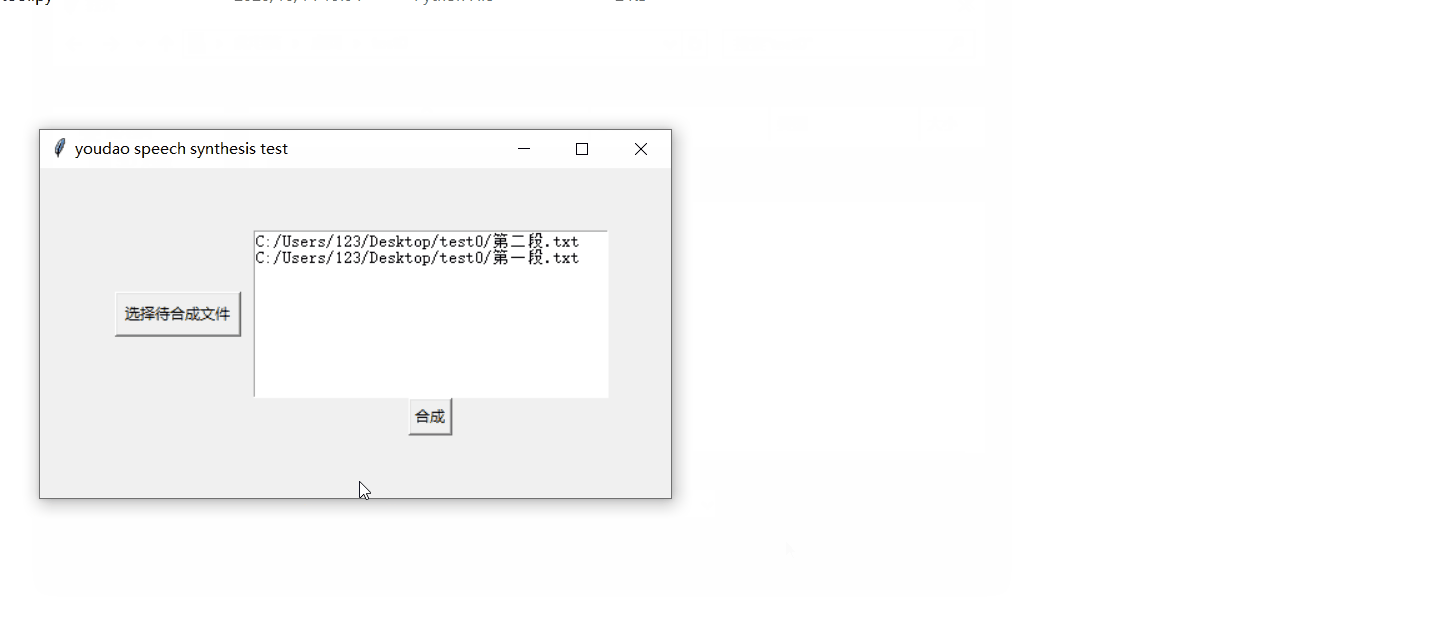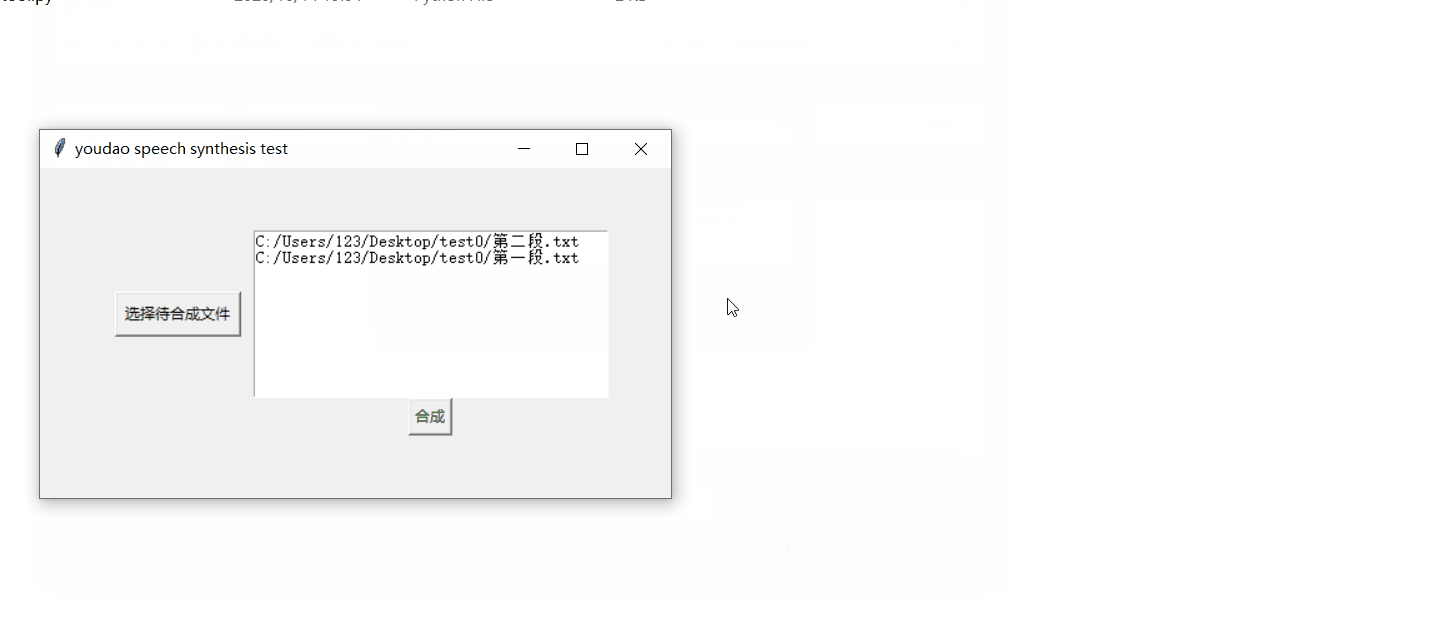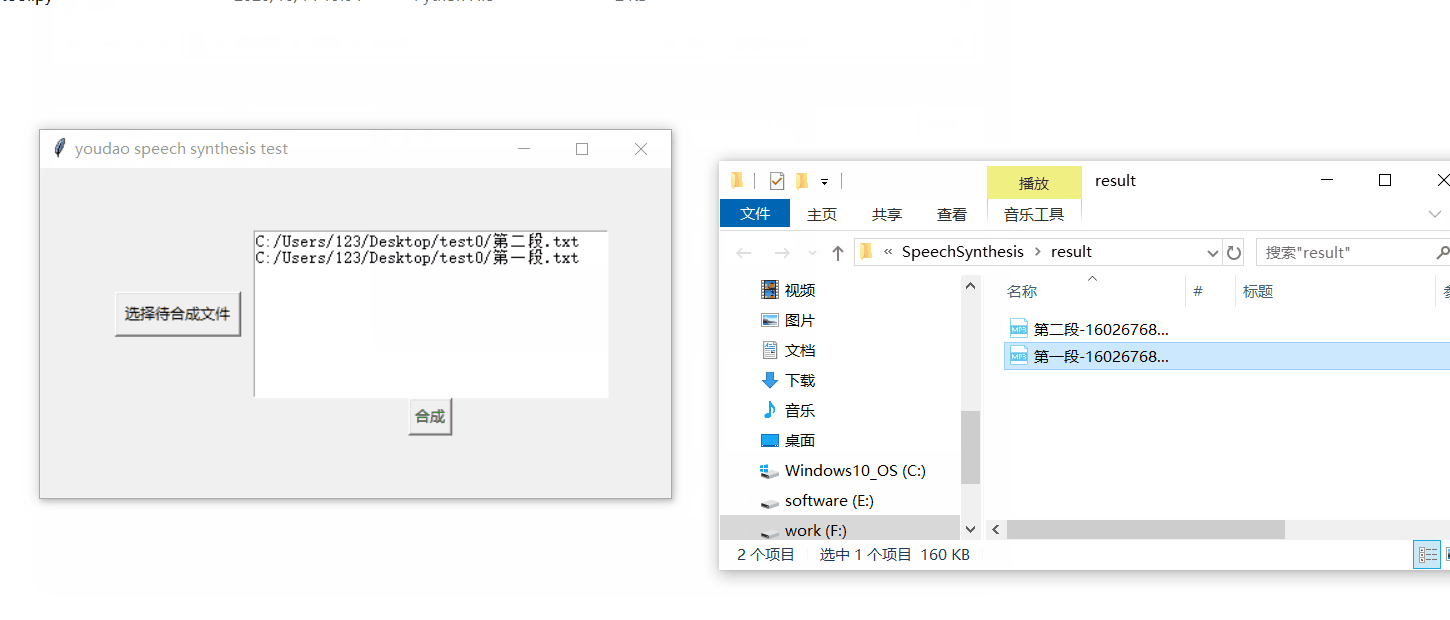 文章插图
文章插图
需要语音合成的文本: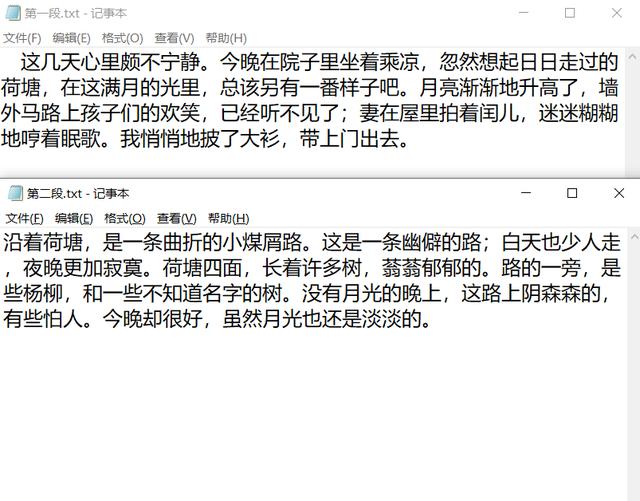 文章插图
文章插图
【记一次讲故事机器人的开发-我有故事,让机器人来读】合成结果(第一段):
对应音频链接为:
合成结果(第二段):
对应音频链接为:
调用API接口的准备工作首先 , 是需要在有道智云的个人页面上创建实例、创建应用、绑定应用和实例 , 获取到应用的id和密钥 。 具体个人注册的过程和应用创建过程详见文章分享一次批量文件翻译的开发过程 。 文章插图
文章插图
开发过程详细介绍下面介绍具体的代码开发过程 。
首先根据文档分析有道智云的API输入输出规范 。 语音合成API调用十分简单 , 该API采用https方式通信 , 所需参数如下表:
字段名类型含义必填备注qtext待合成音频文件的文本字符串True比如:您好langTypetext合成文本的语言类型True支持语言appKeytext应用 IDTrue可在 应用管理 查看salttextUUIDTrueUUIDsigntext签TrueMD5(应用ID+q+salt+应用密钥)voicetext翻译结果发音选择 , 0为女声 , 1为男声 , 默认为女声false0formattext目标音频格式 , 支持mp3falsemp3speedtext合成音频的语速false比如:"1"为正常速度volumetext合成音频的音量false正常为"1.00",最大为"5.00",最小为"0.50"
简单概括 , 组织好自己的语言(utf-8编码文本) , 辅以签名等必要参数 , 并告诉API所需要的音频特征 , 即可得到一份令人满意的合成音频 。
接口输出中 , 如果合成成功 , 正常返回为二进制语音文件 , 具体header信息 Content-type: audio/mp3 , 如果合成出现错误 , 则会返回json结果 , 具体header信息为:Content-type: application/json , 可据此判断运行情况 。
Demo开发:这个demo使用python3开发 , 包括maindow.py , synthesis.py , synthesistool.py三个文件 , 分别为demo的界面、界面逻辑处理和语音合成接口调用工具封装 。
- 界面部分:界面部分代码如下 , 比较简单 。 root=tk.Tk() root.title("youdao speech synthesis test") frm = tk.Frame(root) frm.grid(padx='50', pady='50') # 文件选取按钮 btn_get_file = tk.Button(frm, text='选择待合成文件', command=get_files) btn_get_file.grid(row=0, column=0, ipadx='3', ipady='3', padx='10', pady='20') # 所选文件列表展示框 text1 = tk.Text(frm, width='40', height='10') text1.grid(row=0, column=1) # 启动按钮 btn_sure=tk.Button(frm,text="合成",command=synthesis_files) btn_sure.grid(row=1,column=1) 其中启动按钮btn_sure的绑定事件synthesis_files()来收集带所有的文本文件 , 启动合成 , 并打印运行结果:def synthesis_files(): if syn_m.file_paths: message=syn_m.get_synthesis_result() tk.messagebox.showinfo("提示", message) os.system('start' + '.\\result') else : tk.messagebox.showinfo("提示","无文件")
- synthesis.py这里主要是配合界面实现一些文本读取和请求接口处理返回值的逻辑 。 首先定义一个Synthesis_modelclass Synthesis_model(): def __init__(self,file_paths,result_root_path,syn_type): self.file_paths=file_paths # 待合成文件路径 self.result_root_path=result_root_path # 结果路径 self.syn_type=syn_type # 合成类型 get_synthesis_result()方法实现了批量读取文件并调用合成方法、处理返回信息的逻辑: def get_synthesis_result(self): syn_result="" for file_path in self.file_paths: # 读取文件 file_name=os.path.basename(file_path).split('.')[0] file_content=open(file_path,encoding='utf-8').read() # 调用合成方法 result=self.synthesis_use_netease(file_name,file_content) # 处理返回消息 if result=="1": syn_result=syn_result+file_path+" ok !\n" else: syn_result=syn_result+file_path+result return syn_result 单独定义了方法synthesis_use_netease()具体实现调用API的方法 , 这样增加了demo的扩展性 , 实现了一种合成模块可插拔的松耦合形式:def synthesis_use_netease(self,file_name,text): result=connect(text,'zh-CHS') print(result) if result.headers['Content-Type']=="audio/mp3": millis = int(round(time.time() * 1000)) filePath = "./result/" + file_name+"-"+str(millis) + ".mp3" fo = open(filePath, 'wb') fo.write(result.content) fo.close() return "1" else: return "error:"+result.content
- 公式|?有人把 5G 讲得这么简单明了
- 不坑|库克不讲“性价比”!一台iPhone12至少赚4千,网友:不坑穷人
- 死亡|这届年轻人不讲武德,旧消费主义社会性死亡
- 迁徙|网红迁徙记:哪里才是奶与蜜之地?
- 简单|密码太难记不住,太简单不安全,怎么办?
- 截图|笔记本截图快捷键是什么
- 统计|多久才能换一次手机?统计机构数据有点意外
- 电池容量|Windows 自带功能查看笔记本电脑电池使用情况,你的容量还好吗?
- 手机壳里头|为什么要在手机壳里面夹钱?10个有9个不懂,我才知道大有讲究
- 出行|哈啰出行的“纵横术”