Mysql不止CRUD,聊聊索引( 七 )
 文章插图
文章插图
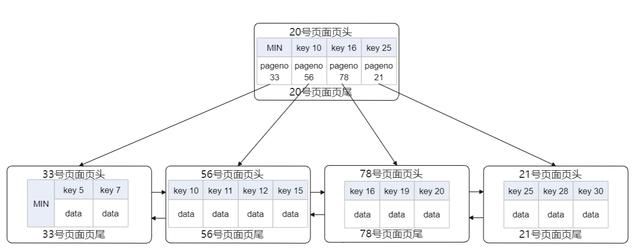
上图所示的是一个深度为2的B+树 , 也是我们所称的索引 , 这里假设页有随机唯一的编号 , 根页号为20 。 这里只有一个内节点(根节点) , 其他的都是叶子节点 , 也是数据节点 , 对于内节点来说 , 存有key和pageno的指针信息 , 对于叶子节点来说 , 只存有完整的数据 。 对于聚集索引 , data部分存有除主键外的其他列的组合 , 如果是二级索引 , 则这里存放就是这行记录对应主键的组合 , 用于回表 。
最左边的MIN为了很好的组织树形结构的指针 , 和其他的内节点一样 , 主要用来标记它是最小记录Min , 还有就是一个pageno指针指向下层最左边的Min记录 , 其他节点的Min记录用于判断搜索是否到了边界 。 每个页都有页头页尾用来管理和标记页面的状态 , 页面中的数据是如何存储 , 有没有空闲的空间 , 以什么样的顺序存储等 。
上图中所有的叶子节点从左到右都是从小到大的顺序以双向链表的方式存储的 , 所以当我们需要遍历全部的数据 , 只需要通过B+树找到最小的位置 , 然后通过遍历链表则可以查询到所有的数据 , 还有就是10,16,25这三条记录在内节点和叶子节点均存在 , 这既是B+数的特点 , 叶子节点会存有所有的key和值 。 而内节点只存储了key , 不存储其他的数据 , 只有用来索引 。 叶子节点除了第一条记录会有上一层重复的存储 , 其他数据不会有这样的现象 , 所以浪费的空间也不大 , 由于每一个页的大小是固定的(16k) , 在内节点上只存储key , 不存储其他数据 , 一个页就可以存储更多的key , 这样检索也能减少磁盘的IO , 由于页存储Key增多 , 这样就可以使得B+树的深度减少 , 这样也可以减少磁盘的IO , 提高查询性能 。
例如一个三层的B+数 , 每一个页能存1000个key , 所以第二层就有1000*(1+1000)个key , 第三层就可以有1000*1001*1001=1002001000(十亿级别) , 一个简单的三层B+数据就可以存十亿级别的数据 , 很强大 。
上面说到的“回表”其实就是在使用二级索引进行搜索时 , 因为二级索引只保存了部分列的数据 , 如果需要获取键值不包括的列的数据时 , 需要通过二级索引的指针(书签:用于指向聚集索引的指针)来找到聚集索引的全部数据 , 然后返回需要查询的列的值 。 如果使用二级索引不能找到需要的值(需要回表) , 称为非覆盖索引 , 否则为2.6节介绍的覆盖索引 。 非覆盖索引需要回表 , 增加IO , 所以性能会差一些 。 所以可以根据业务需求创建组合索引来避免回表 。 但是也要权衡索引带来的利是否大于弊 。 所以在统计行总数的时候可以通过二级索引来统计 , 这样速度会快一些 。 大概图形如下: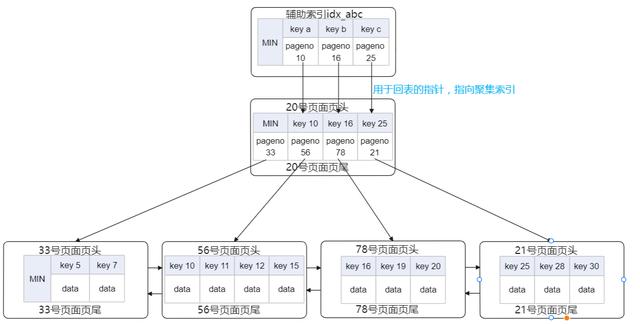 文章插图
文章插图
这里附带的说一些不能走索引的情况 , 但是不多说 , 因为优化这个东西太多 , 后期准备写一两篇优化的文章 , 所以这里只是提一下 , 走索引的强大;虽然可能创建了很多索引 , 很多情况都不走索引 , 比如:like '%query_name%', where端使用or条件连接 , where端使用函数等 , 在group by和order by使用的时候要注意组合索引的最左前缀原则 。
原文链接:
【Mysql不止CRUD,聊聊索引】如果觉得本文对你有帮助 , 可以转发关注支持一下
- 手机|用手机镜头展示丛林秘境,vivo S7带来的不止是高清
- Note9|Redmi Note9 Pro首发体验,原来不止“差评”
- Reno5|通过HDR10+认证!OPPO Reno5惊喜果然不止这几点
- pymysql 连接 MySQL 实现简单登录
- GET|有赞教育负责人胡冰:做教育招生“新基建”不止于工具
- mysql 8.0.21 安装配置方法图文教程
- SpringBoot+MyBatis+MySQL读写分离实现
- 真正福利果粉时刻!iPhone12不止定价合理,续航提升明显
- 详解mysql执行计划
- 什么是MySQL的执行计划(Explain关键字)?