Mysql不止CRUD,聊聊索引( 六 )
explain select * from foundation_item.item where store_id > 332604504249736122 and store_id < 332604504249736201; 文章插图
文章插图
如上:MRR优化关闭后没有启动了
2.8、Index Condition Pushdown(ICP)优化MySQL数据库会在取出索引的同时 , 判断是否可以进行WHERE条件的过滤 , 也就是将WHERE的部分过滤操作放在了存储引擎层 。 在某些查询下 , 可以大大减少上层SQL层对记录的索取(fetch) , 从而提高数据库的整体性能 , 优化支持range、ref、eq_ref、ref_or_null类型的查询 , 选择Index Condition Pushdown优化时 , 可在执行计划的列Extra看到Using index condition提示 。
实验:数据来源于2.1生成的数据:
首先我们创建一个组合索引:create index idx_email_id_address_state on foundation_commons.email (state,address,email_id);
explain SELECT * from foundation_commons.email where state =0 and address like '%D%' and email_id >='332604504249734136' ; 文章插图
文章插图
以上实验只是为了显示这样的现象
1、当sql需要全表访问时 , ICP的优化策略可用于range, ref, eq_ref, ref_or_null类型的访问数据方法。 2. 支持InnoDB和MyISAM表 。 3. ICP只能用于二级索引 , 不能用于主索引 。 4. 并非全部where条件都可以用ICP筛选 , 如果where条件的字段不在索引列中 , 还是要读取整表的记录到server端做where过滤 。
回到顶部
三、索引实现的原理innodb存储的索引是基于B+树实现的 , 从1.1节中的表格可以看出 , 不支持hash的实现方式 。 首先来了解下B+树的特点;
B+树的特征:
- 有k个子树的中间节点包含有k个元素(B树中是k-1个元素) , 每个元素不保存数据 , 只用来索引 , 所有数据都保存在叶子节点 。
- 所有的叶子结点中包含了全部元素的信息 , 即指向含这些元素记录的指针 , 且叶子结点本身依关键字的大小自小而大顺序链接 。
- 所有的中间节点元素都同时存在于子节点 , 在子节点元素中是最大(或最小)元素 。
- 单一节点存储更多的元素 , 使得查询的IO次数更少 。
- 所有查询都要查找到叶子节点 , 查询性能稳定 。
- 所有叶子节点形成有序链表 , 便于范围查询 。
 文章插图
文章插图索引的设计思考:
- 索引是一种存储方式 , 最相关的硬件就是磁盘 , 索引磁盘的性能会直接影响到数据库的查询效率
- 磁盘的性能和读写的顺序有关 , 普通磁盘顺序读写比随机读写快很多 , 所以尽量避免随机读写 。
- 数据都是以行为单位一行一行的存储的 , 每一行都包括了所有的列 , 多行可以连续存储 。
- 每一行数据中 , 一般都有一个键 , 其他的列可以称为值 , 可以理解为键值对 。 innodb必须有唯一非空的主键 , 就是默认的键 。
- 在键值对中 , 键值可以排序 , 还可以组合键值 。
- 磁盘空间会划分为许多个大小相等的块或者页 , 一个页中可以存储多行数据 , 这样就可以符合磁盘的顺序读写 , 这样一次IO就可以读取很多数据到内存 , 可以减少磁盘IO 。
- 在一个页内 , 所有的数据可能会经常变动 , 并且大小也是相对固定的 , 所以内部通过链表或者数组管理 。
- 每个键值可以排序 , 所以在一个块内的所有数据也可以是有序的 , 这样通过二分法查找可以很快的在一个页内找到指定键对应的数据
- 一个页设计好之后 , 可以把页作为B+树的节点 , 通过页来承载数据 , 通过B+数来组织不同页之间的关系
- B+树的特点是在内节点存储键来提高搜索的性能 , 所以很自然的 , 内节点用来存储数据行的键 , 叶子节点存储所有数据行 , 可以很好的提升性能
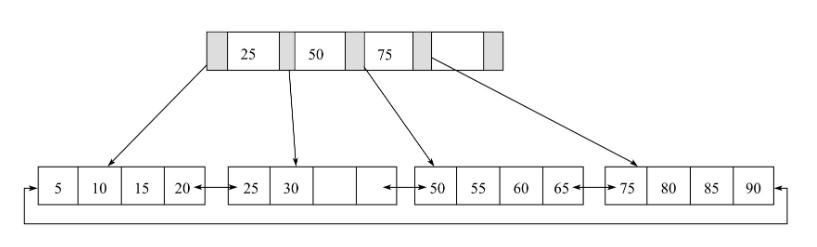
表中数据按照主键顺序存放 。 而聚集索引(clustered index)就是按照每张表的主键构造一棵B+树 , 同时叶子节点中存放的即为整张表的行记录数据 , 也将聚集索引的叶子节点称为数据页 。 聚集索引的这个特性决定了索引组织表中数据也是索引的一部分 。 同B+树数据结构一样 , 每个数据页都通过一个双向链表来进行链接 。 如下图所示:
- 手机|用手机镜头展示丛林秘境,vivo S7带来的不止是高清
- Note9|Redmi Note9 Pro首发体验,原来不止“差评”
- Reno5|通过HDR10+认证!OPPO Reno5惊喜果然不止这几点
- pymysql 连接 MySQL 实现简单登录
- GET|有赞教育负责人胡冰:做教育招生“新基建”不止于工具
- mysql 8.0.21 安装配置方法图文教程
- SpringBoot+MyBatis+MySQL读写分离实现
- 真正福利果粉时刻!iPhone12不止定价合理,续航提升明显
- 详解mysql执行计划
- 什么是MySQL的执行计划(Explain关键字)?