程序的“听诊器”——性能监视工具( 二 )
程序P4
int root(int n)265{return (int) sqrt((float) n); }int prime(int n){int i, bound;999if (n % 2 == 0)500return 0;499if (n % 3 == 0)167return 0;332if (n % 5 == 0)67return 0;265bound = root(n);265for (i = 7; i <= bound; i = i+2)1530if (n % i == 0)100return 0;165return 1;}main(){int i, n;1n = 1000;1for (i = 2; i <= n; i++)999if (prime(i))165printf("%d\n", i);}先前的程序找到168个素数 , 而程序P4只找到165个 。 丢失的3个素数在哪里?对了 , 我把3个数作为特殊情形 , 每个数都引入了一处错误:prime报告2不是素数 , 因为它被2整除 。 对于3和5 , 存在类似的错误 。 正确的检验是
if (n % 2 == 0)return (n == 2);依此类推 。 如果n被2整除 , 如果n是2就返回1 , 否则返回0 。 对于n=1000、10 000和100 000 , 程序P4的过程时间性能监视结果总结在下表中 。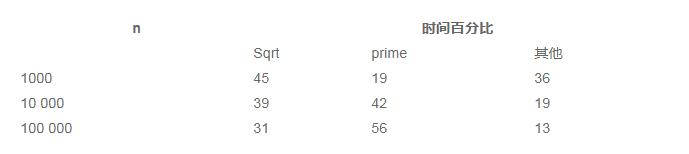 文章插图
文章插图
程序P5比程序P4快 , 并且有个好处:正确 。 它把费时的开方运算换成了乘法 , 如以下程序片段所示 。
程序P5的片段
265for (i = 7; i*i <= n; i = i+2)1530if (n % i == 0)100return 0;165return 1;它还加入了对被2、3、5整除的正确检验 。 程序P5总的加速大约有20% 。
最后的程序只对已被判定为素数的整数检验整除性;程序P6在1.4节 , 用Awk语言写成 。 C实现的过程时间性能监视结果表明 , 在n=1 000时 , 49%的运行时间花在prime和main上(其余是输入/输出);而当n=100 000时 , 88%的运行时间花在这两个过程上 。
下面这个表总结了我们已经看到的这几个程序 。 表中还包含另外两个程序作为测试基准 。 程序Q1用习题答案2中的埃氏筛法程序计算素数 。 程序Q2测量输入/输出开销 。 对于n=1 000 , 它打印整数1, 2,…, 168;对于一般的n , 它打印整数1, 2,…, P(n) , 其中P(n)是比n小的素数的个数 。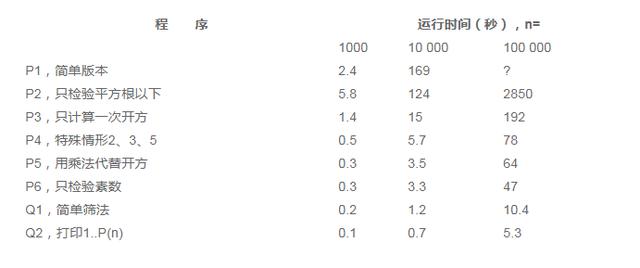 文章插图
文章插图
以上集中讲述了性能监视的一种用途:当你调优单个子过程或函数的性能时 , 性能监视工具能告诉你运行时间都花在了哪里 。
2 使用性能监视工具对于小程序来说 , 性能监视很容易实现 , 因此性能监视工具是可有可无的;但是对于开发大软件来说 , 性能监视工具则是不可或缺的 。 Brian Kernighan曾经使用行计数性能监视工具 , 研究了一个用于解释Awk语言程序的4000行的C程序 。 那时这个Awk解释程序已广泛使用了多年 。 扫描该程序75页长的程序清单就会发现 , 大多数计数都是成百上千的 , 有些甚至上万 。 一段晦涩的初始化代码 , 计数接近百万 。 Kernighan对一个6行的循环做了几处修改 , 程序速度就提高了一倍 。 他自己可能永远也猜不出程序的问题源头所在 , 但是性能监视工具引导他找到了 。
Kernighan的这一经历是相当典型的 。 “一个程序中不到4%的语句通常占用了一半以上的运行时间 。 ”对许多语言和系统的大量研究表明 , 对于不处理I/O密集型的大多数程序 , 大部分的运行时间花在了很小一部分代码上 。 这种模式是下述经验的基础:
Knuth在论文中描述了用行计数性能监视工具进行自我分析的结果 。 性能监视结果表明 , 一半的运行时间花在了两个循环上 。 结果花了不到一小时修改了几行代码 , 就让这个性能监视工具的速度提高了一倍 。
性能监视结果说明 , 一个1000行的程序把80%的时间花在一个5行的子程序上 。 把这个子程序改写成十几行 , 就让程序的速度提高了一倍 。
1984年贝尔实验室的Tom Szymanski打算给一个大系统提速 , 结果却使该系统慢了10% 。 他删除了修改的部分 , 然后多打开了一些性能监视选项以查明失败原因 。 他发现占用的存储空间增加到了原来的20倍 , 行计数显示存储空间的分配次数远多于释放次数 。 接下来用一条指令就纠正了错误 , 正确的实现让系统加速了一倍 。
【程序的“听诊器”——性能监视工具】性能监视表明 , 操作系统一半的时间花在一个只有少数几条指令的循环上 。 改写微代码中的这个循环带来一个量级的提速 , 但是系统的吞吐量不变:性能组已经优化了系统的空闲循环!
这些经历引出了上一节粗略提到过的一个问题:应当在什么输入上监视程序的性能?查找素数的程序只有一个输入n , 该输入强烈影响到时间性能监视:对于小的n , 输入/输出占大头;对于大的n , 计算占大头 。 有的程序的性能监视结果对输入数据非常不敏感 。 我猜想大多数计算薪水的程序都有相当一致的性能监视结果 , 至少从2月到11月如此 。 但有的程序的性能监视结果会随输入不同有巨大变化 。 难道你从没有察觉到 , 你的系统被调整得在制造商的基准数据上运行起来风驰电掣 , 而处理起你的重要任务时却慢如蜗牛?仔细挑选你的输入数据吧 。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 空调|让格力、海尔都担忧,中国取暖“新潮物”强势来袭,空调将成闲置品?
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 同比|亚马逊公布“剁手节”创纪录战绩:第三方卖家全球销售额超48亿美元 同比大增60%
- 行业|现在行业内客服托管费用是怎么算的
- 闲鱼|电诉宝:“闲鱼”网络欺诈成用户投诉热点 Q3获“不建议下单”评级
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 产业|前瞻生鲜电商产业全球周报第67期:发力社区团购!京东内部筹划“京东优选”
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 程序|2020全景生态流量秋季大报告:TOP100APP超半数布局小程序,全景流量重塑行业竞争新格局