深度学习算法完整简介( 二 )
在RNN中定义计算的公式如下:
- x_t-在时间步t输入 。 例如 , x_1可以是与句子的第二个单词相对应的one-hot向量 。
- s_t是步骤t中的隐藏状态 。 这是网络的“内存” 。 s_t作为函数取决于先前的状态和当前输入x_t:s_t = f(Ux_t + Ws_ {t-1}) 。 函数f通常是非线性的 , 例如tanh或ReLU 。 计算第一个隐藏状态所需的s _ {-1}通常初始化为零(零向量) 。
- o_t-在步骤t退出 。 例如 , 如果我们要预测句子中的单词 , 则输出可能是字典中的概率向量 。 o_t = softmax(Vs_t)
与卷积神经网络一起 , RNN被用作模型的一部分 , 以生成未标记图像的描述 。 组合模型将生成的单词与图像中的特征相结合:
 文章插图
文章插图最常用的RNN类型是LSTM , 它比RNN更好地捕获(存储)长期依赖关系 。 LSTM与RNN本质上相同 , 只是它们具有不同的计算隐藏状态的方式 。
LSTM中的memory称为cells , 您可以将其视为接受先前状态h_ {t-1}和当前输入参数x_t作为输入的黑盒 。 在内部 , 这些cells决定保存和删除哪些memory 。 然后 , 它们将先前的状态 , 当前memory和输入参数组合在一起 。
这些类型的单元在捕获(存储)长期依赖关系方面非常有效 。
#5递归神经网络
递归神经网络是循环网络的另一种形式 , 不同之处在于它们是树形结构 。 因此 , 它们可以在训练数据集中建模层次结构 。
由于其与二叉树、上下文和基于自然语言的解析器的关系 , 它们通常用于音频到文本转录和情绪分析等NLP应用程序中 。 然而 , 它们往往比递归网络慢得多
#6自编码器
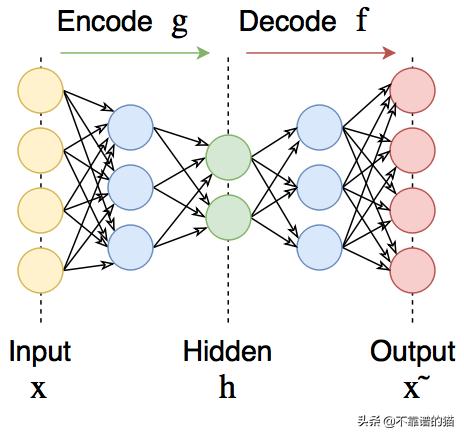
自编码器可在输出处恢复输入信号 。 它们内部有一个隐藏层 。 自编码器设计为无法将输入准确复制到输出 , 但是为了使误差最小化 , 网络被迫学习选择最重要的特征 。
 文章插图
文章插图自编码器可用于预训练 , 例如 , 当有分类任务且标记对太少时 。 或降低数据中的维度以供以后可视化 。 或者 , 当您只需要学习区分输入信号的有用属性时 。
#7深度信念网络和受限玻尔兹曼机器
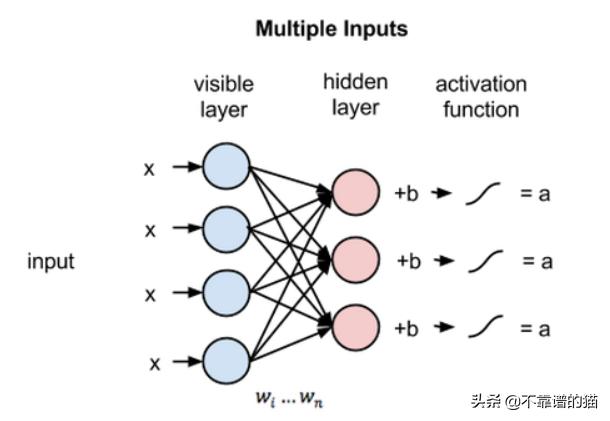
受限玻尔兹曼机是一个随机神经网络(神经网络 , 意味着我们有类似神经元的单元 , 其binary激活取决于它们所连接的相邻单元;随机意味着这些激活具有概率性元素) , 它包括:
- 可见单元层
- 隐藏单元层
- 偏差单元
 文章插图
文章插图为了使学习更容易 , 我们对网络进行了限制 , 使任何可见单元都不连接到任何其他可见单元 , 任何隐藏单元都不连接到任何其他隐藏单元 。
多个RBM可以叠加形成一个深度信念网络 。 它们看起来完全像全连接层 , 但但是它们的训练方式不同 。
#8生成对抗网络(GAN)
GAN正在成为一种流行的在线零售机器学习模型 , 因为它们能够以越来越高的准确度理解和重建视觉内容 。 用例包括:
- 从轮廓填充图像 。
- 从文本生成逼真的图像 。
- 制作产品原型的真实感描述 。
- 将黑白图像转换为彩色图像 。
- 在框架内模拟人类行为和运动的模式 。
- 预测后续的视频帧 。
- 创建deepfake
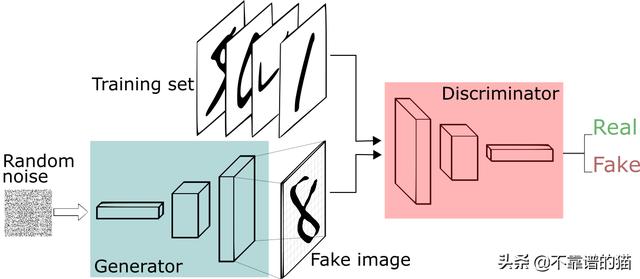
- 生成器学习生成可信的数据 。 生成的实例成为判别器的负面训练实例 。
- 判别器学会从数据中分辨出生成器的假数据 。 判别器对产生不可信结果的发生器进行惩罚 。
 文章插图
文章插图然后 , 将生成的图像与原始概念的实际数据点一起馈入判别器 。 判别器对信息进行过滤 , 并返回0到1之间的概率来表示每个图像的真实性(1与真相关 , 0与假相关) 。 然后检查这些值是否成功 , 并不断重复 , 直到达到预期的结果 。
#9Transformers
- 逛逛|淘宝内容化再升级:“买家秀”变身“逛逛”试图冲破算法局限
- 深度|iPhone12到底值得买吗 深度体验一周我发现了这些
- 算法|【远见】个人信息保护法将出台 揭开数据算法的神秘“面纱”
- 采用|iPhone12mini和iPhone7深度对比:值得升级吗
- 设计|未来创意拒绝被垄断:欧拉共创成果深度解读!
- X50|vivo X50 Pro+深度测评:全能影像机皇登场
- 广度|华住创始人季琦:深度重要于广度
- 用于|用于半监督学习的图随机神经网络
- NeurIPS 2020论文分享第一期|深度图高斯过程 | 深度图
- iPhone12 mini|从华为P30换成iPhone12mini,深度体验一周,优缺点很明显