连环触发!MongoDB核心集群雪崩故障背后竟是……( 三 )
2) 业务如何恢复
第一次突发流量引起的抖动问题后 , 我们扩容所有的代理到8个 , 同时通知业务把所有业务接口配置上所有代理 。 由于业务接口众多 , 最终B机房的业务没有配置全部代理 , 只配置了原先的两个处于同一台物理机的代理(4.4.4.4:1111,4.4.4.4:2222) , 最终触发MongoDB的一个性能瓶颈(详见后面分析) , 引起了整个MongoDB集群”雪崩”
最终 , 业务通过重启服务 , 同时把B机房的8个代理同时配置上 , 问题得以解决 。
3) mongos代理实例监控分析
分析该时间段代理日志 , 可以看出和上述第一点同样的现象 , 大量的新键连接 , 同时新连接在几十ms、一百多ms后又关闭连接 。 整个现象和之前分析一致 , 这里不在统计分析对应日志 。
此外 , 分析当时的代理QPS监控 , 正常query读请求的QPS访问曲线如下 , 故障时间段QPS几乎跌零雪崩了: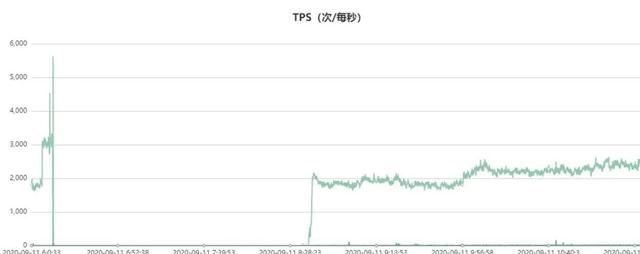 文章插图
文章插图
Command统计监控曲线如下: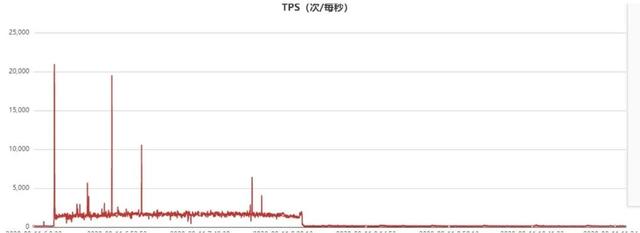 文章插图
文章插图
从上面的统计可以看出 , 当该代理节点的流量故障时间点有一波尖刺 , 同时该时间点的command统计瞬间飙涨到22000(实际可能更高 , 因为我们监控采样周期30s,这里只是平均值) , 也就是瞬间有2.2万个连接瞬间进来了 。 Command统计实际上是db.ismaster统计 , 客户端connect服务端成功后的第一个报文就是ismaster报文 , 服务端执行db.ismaster后应答客户端 , 客户端收到后开始正式的sasl认证流程 。
正常客户端访问流程如下:
- 客户端发起与mongos的链接;
- mongos服务端accept接收链接后 , 链接建立成功;
- 客户端发送db.isMaster命令给服务端;
- 服务端应答isMaster给客户端;
- 客户端发起与mongos代理的sasl认证(多次和mongos交互);
- 客户端发起正常的find流程 。
此外 , 通过提前部署的脚本,该脚本在系统负载高的时候自动抓包 , 从抓包分析结果如下图所示:
 文章插图
文章插图上图时序分析如下:
- 11:21:59.506174 链接建立成功
- 11:21:59.506254 客户端发送db.IsMaster到服务端
- 11:21:59.656479 客户端发送FIN断链请求
- 11:21:59.674717 服务端发送db.IsMaster应答给客户端
- 11:21:59.675480 客户端直接RST
总结:通过抓包和mongos日志分析 , 可以确定链接建立后快速断开的原因是:客户端访问代理的第一个请求db.isMaster超时了 , 因此引起客户端重连 。 重连后又开始获取db.isMaster请求 , 由于负载CPU 100%, 很高 , 每次重连后的请求都会超时 。 其中配置超时时间为500ms的客户端 , 由于db.isMaster不会超时 , 因此后续会走sasl认证流程 。
因此可以看出 , 系统负载高和反复的建链断链有关 , 某一时刻客户端大量建立链接(2.2W)引起负载高 , 又因为客户端超时时间配置不一 , 超时时间配置得比较大得客户端最终会进入sasl流程 , 从内核态获取随机数 , 引起sy%负载高 , sy%负载高又引起客户端超时 , 这样整个访问过程就成为一个“死循环” , 最终引起mongos代理雪崩 。
3、线下模拟故障
到这里 , 我们已经大概确定了问题原因 , 但是为什么故障突发时间点那一瞬间2万个请求就会引起sy%负载100%呢 , 理论上一秒钟几万个链接不会引起如此严重的问题 , 毕竟我们机器有40个CPU 。 因此 , 分析反复建链断链为何引起系统sy%负载100%就成为了本故障的关键点 。
1)模拟故障过程
模拟频繁建链断链故障步骤如下:
- 修改mongos内核代码 , 所有请求全部延时600ms
- 同一台机器起两个同样的mongos , 通过端口区分
- 京东双11提前?连环折扣“王炸”开场,10.21爆品来了
- MongoDB提供多云集群,AWS、微软和谷歌都在列
- 由热靴移至机侧 尼康发布全新闪灯触发器
- 标签|iOS 14在Safari中长按不同按钮会触发的各种功能
- HBase Compaction作用和触发条件
- 没人说|iPhone12遭遇连环差评,华为也曾“绿屏”,但基本没人说
- Python操作三大数据库 - MongoDB
- 要来|【国元资讯早班车】惊魂!千亿国企债券违约连环爆!5G杀手级应用要来了!
- 不用读的说明书,为何每个产品中都有它的身影,连环保的苹果也不例外
- 连环套|「网络安全」刷单要看“进度条”那是骗子“连环套”!