连环触发!MongoDB核心集群雪崩故障背后竟是……( 二 )
每个流量徒增时间点 , 对应业务监控都有一波超时或者抖动 , 如下: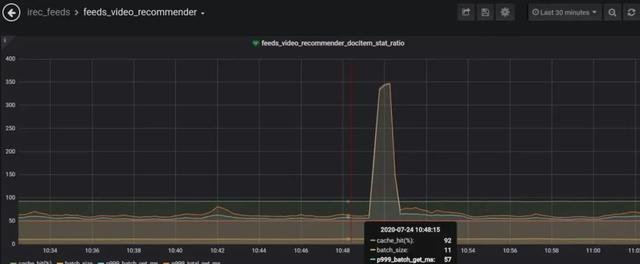 文章插图
文章插图
分析对应代理mongos日志 , 发现如下现象:抖动时间点mongos.log日志有大量的建链接和断链接的过程 , 如下图所示: 文章插图
文章插图
从上图可以看出 , 一秒钟内有几千个链接建立 , 同时有几千个链接断开 , 此外抓包发现很多链接短期内即断开链接 , 现象如下(断链时间-建链时间=51ms, 部分100多ms断开): 文章插图
文章插图
对应抓包如下: 文章插图
文章插图
此外 , 该机器代理上客户端链接低峰期都很高 , 甚至超过正常的QPS值 , QPS大约7000-8000 , 但是conn链接缺高达13000 , mongostat获取到监控信息如下: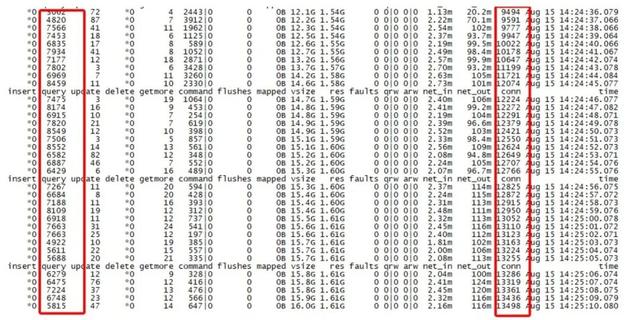 文章插图
文章插图
3)代理机器负载分析
每次突发流量的时候 , 代理负载很高 , 通过部署脚本定期采样 , 抖动时间点对应监控图如下图所示: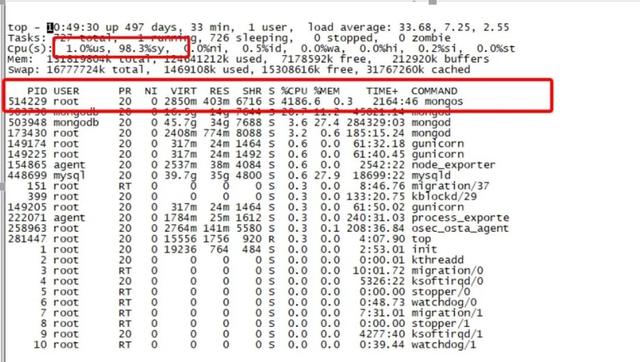 文章插图
文章插图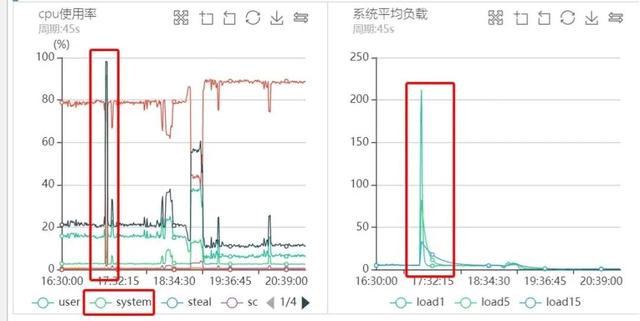 文章插图
文章插图
从上图可以看出 , 每次流量高峰的时候CPU负载都非常的高 , 而且是sy%负载 , us%负载很低 , 同时Load甚至高达好几百 , 偶尔甚至过千 。
4) 抖动分析总结
从上面的分析可以看出 , 某些时间点业务有突发流量引起系统负载很高 。 根因真的是因为突发流量吗?其实不然 , 请看后续分析 , 这其实是一个错误结论 。 没过几天 , 同一个集群雪崩了 。
于是业务梳理突发流量对应接口 , 梳理出来后下掉了该接口 , QPS监控曲线如下: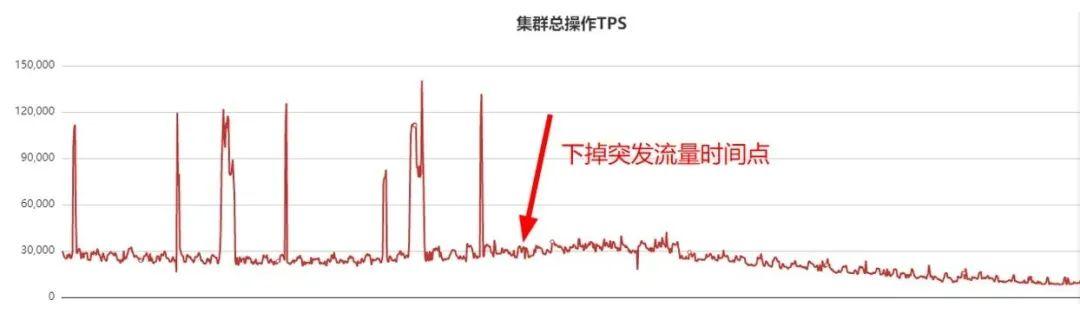 文章插图
文章插图
为了减少业务抖动 , 因此下掉了突发流量接口 , 此后几个小时业务不再抖动 。 当下掉突发流量接口后 , 我们还做了如下几件事情:
- 由于没找到mongos负载100%真正原因 , 于是每个机房扩容mongs代理 , 保持每个机房4个代理 , 同时保证所有代理在不同服务器 , 通过分流来尽量减少代理负载 。
- 通知A机房和B机房的业务配置上所有的8个代理 , 不再是每个机房只配置对应机房的代理(因为第一次业务抖动后 , 我们分析MongoDB的java sdk , 确定sdk均衡策略会自动剔除请求时延高的代理 , 下次如果某个代理再出问题 , 也会被自动剔除) 。
- 通知业务把所有客户端超时时间提高到500ms 。
- 存储节点4个 , 代理节点5个 , 存储节点无任何抖动, 反而七层转发的代理负载高?
- 为何抓包发现很多新连接几十ms或者一百多ms后就断开连接了?频繁建链断链?
- 为何代理QPS只有几万 , 这时代理CPU消耗就非常高 , 而且全是sy%系统负载?以我多年中间件代理研发经验 , 代理消耗的资源很少才对 , 而且CPU只会消耗us% , 而不是sy%消耗 。
好景不长 , 业务下掉突发流量的接口没过几天 , 更严重的故障出现了 , 机房B的业务流量在某一时刻直接跌0了 , 不是简单的抖动问题 , 而是业务直接流量跌0 , 系统sy%负载100% , 业务几乎100%超时重连 。
1)机器系统监控分析
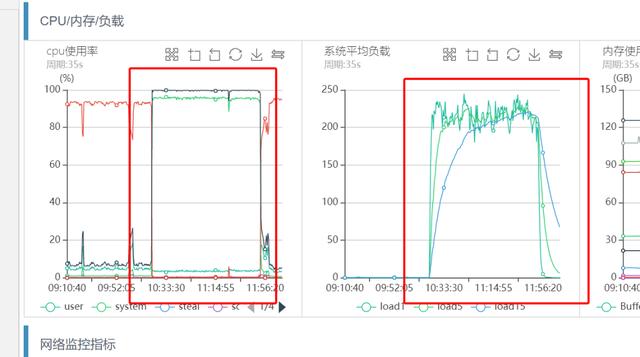
机器CPU和系统负载监控如下:
 文章插图
文章插图从上图可以看出 , 几乎和前面的突发流量引起的系统负载过高现象一致 , 业务CPU sy%负载100% , load很高 。 登陆机器获取top信息 , 现象和监控一致 。
 文章插图
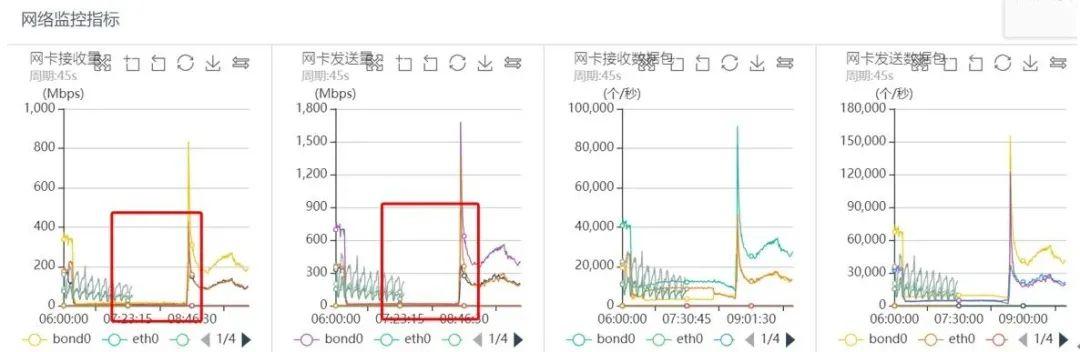
文章插图同一时刻对应网络监控如下:
 文章插图
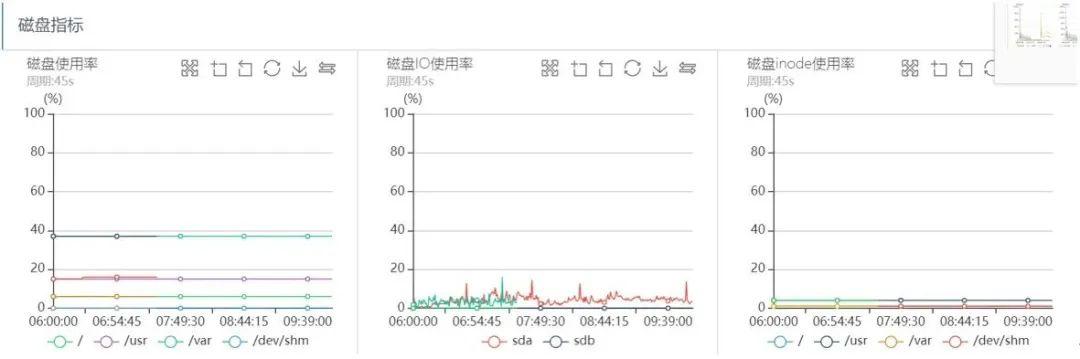
文章插图磁盘IO监控如下:
 文章插图
文章插图 文章插图
文章插图从上面的系统监控分析可以看出 , 出问题的时间段 , 系统CPU sy%、load负载都很高 , 网络读写流量几乎跌0 , 磁盘IO一切正常 , 可以看出整个过程几乎和之前突发流量引起的抖动问题完全一致 。
- 京东双11提前?连环折扣“王炸”开场,10.21爆品来了
- MongoDB提供多云集群,AWS、微软和谷歌都在列
- 由热靴移至机侧 尼康发布全新闪灯触发器
- 标签|iOS 14在Safari中长按不同按钮会触发的各种功能
- HBase Compaction作用和触发条件
- 没人说|iPhone12遭遇连环差评,华为也曾“绿屏”,但基本没人说
- Python操作三大数据库 - MongoDB
- 要来|【国元资讯早班车】惊魂!千亿国企债券违约连环爆!5G杀手级应用要来了!
- 不用读的说明书,为何每个产品中都有它的身影,连环保的苹果也不例外
- 连环套|「网络安全」刷单要看“进度条”那是骗子“连环套”!