python特征选择SelectKBest实战:期货相关特征
最近写了个代码 。
首先来说一下需求:
我得到了一堆数据 , 这些数据是各种你想到的和想不到的、与豆粕期货相关的和无关的数据 , 比如天气、世界各地牲畜产量等 。
这些数据大概有500多列(也就是500+个特征) , 我要找出与期货相关的特征 , 以便后续使用sklearn相关方法来预测期货价格的趋势 。
这里的“找出与期货相关的特征”就是我们所说的特征工程了 。
是整个数据挖掘过程中最烦人、最头疼 , 却也最重要的一个环节 。
往往你预测的结果正不正确 , 就跟你选取的特征有很大关系 。
同一组数据 , 选择不同的特征 , 或者赋予的权重不同 , 得到的结果有可能就差别巨大 。
这里我选择使用SelectKBest的方法来做 。
这个过程中的前提工作包括了填补缺失值、移除低方差特征 , 这些我在下面代码中都有做到 。
还有个比较绕的技巧 , 就是sklearn的所有方法中 , fit_transform得到的都是numpy的array , 是不带index和columns的 , 而我的要求是要看到选出来的特征 , 要保留index(日期)和columns(特征名 , 比如我想知道天气这个特征是否被保留下来) , 我的解决方法也在我后面相关的代码中 。
好了 , 废话不多说了 , 上代码(录视频真的很浪费时间 , 以后有时间再慢慢把视频补上)
- 引入包
import pandas as pdimport numpy as npfrom sklearn.impute import KNNImputerfrom sklearn.feature_selection import VarianceThresholdimport matplotlib.pyplot as pltfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.model_selection import cross_val_score- 让图表正常显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']# 用来正常显示中文标签plt.rcParams['axes.unicode_minus'] = False# 用来正常显示负号- 导入数据
file_path=r"D:\刘\收\每日收盘价Y.csv"data=http://kandian.youth.cn/index/pd.read_csv(file_path)data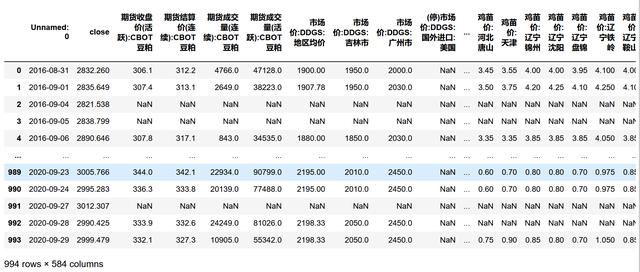 文章插图
文章插图说明原始共有584个特征
- 划分X , y
X=data.iloc[:,2:]X.index=data.iloc[:,0]#原始数据中index为0,1,2这类型的 , 要把index更改为原始数据中日期那一列 , 即第0列y=data.iloc[:,1]y.index=data.iloc[:,0]#同上- 填补缺失值
X=X.fillna(method='bfill',limit=1000)X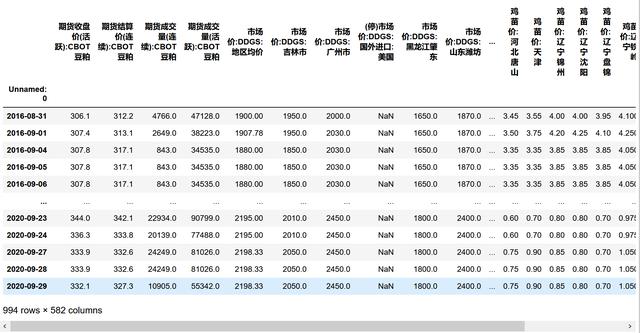 文章插图
文章插图- 删除无法填补的列(一列里缺失值太多 , 填补不了 , 只能删除)
X=X.dropna(axis = 1)print(X.shape)(994,424)说明删掉了160个特征
将处理好缺失值的数据保存
X_=pd.concat((X,y),axis=1)X_.to_csv(r"D:\刘\预测\处理缺失值3.csv")- 移除低方差特征 , 找出最合适的方差
var=np.arange(0.1,1,0.05)X_shape_list=[]for i in var:vt=VarianceThreshold(threshold=i)X_seleted=vt.fit_transform(X)X_shape_list.append(X_seleted.shape[1])print(X_shape_list)plt.plot(var,X_shape_list)plt.xlabel("var")plt.ylabel("X_shape")plt.xticks(np.arange(0.1,1,0.1))plt.show()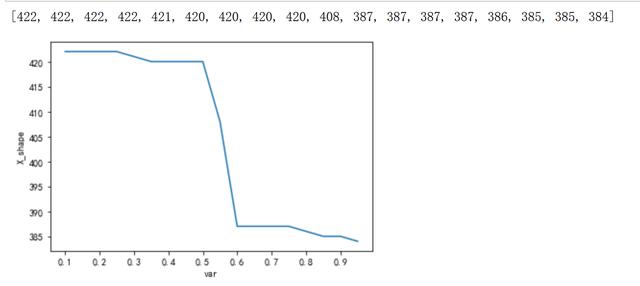 文章插图
文章插图- 取var=0.7 , 移除低方差特征
vt=VarianceThreshold(threshold=0.7)X_seleted=vt.fit(X)X_transformed=vt.fit_transform(X)X_transformed.shape(994,378)说明又移除掉了几十个特征
- 查看移除低方差特征后 , 剩下的特征及所在的列
X_seleted_index=X_seleted.get_support(indices=True)#使用移除低方差特征后 , 留下的特征分别是第几个X_transformed_1=pd.DataFrame(X_transformed,columns=X.columns[X_seleted_index],index=data.iloc[:,0])#因为fit_transform得到的是numpy的array , #是没有index和columns的 , 所以我要手动给它添加回去!!!X_transformed_1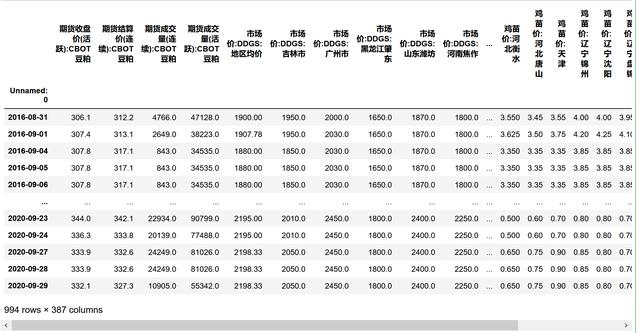 文章插图
文章插图- 使用SelectKBest , 查看每个特征与y的相关性
SKB=SelectKBest(mutual_info_regression,k=387)X_SKB=SKB.fit(X_transformed_1,y)X_SKB_transformed=SKB.fit_transform(X_transformed_1,y)X_SKB_scores=X_SKB.scores_X_SKB_scores_0=pd.DataFrame({"scores":X_SKB_scores},index=X_transformed_1.columns)X_SKB_scores_0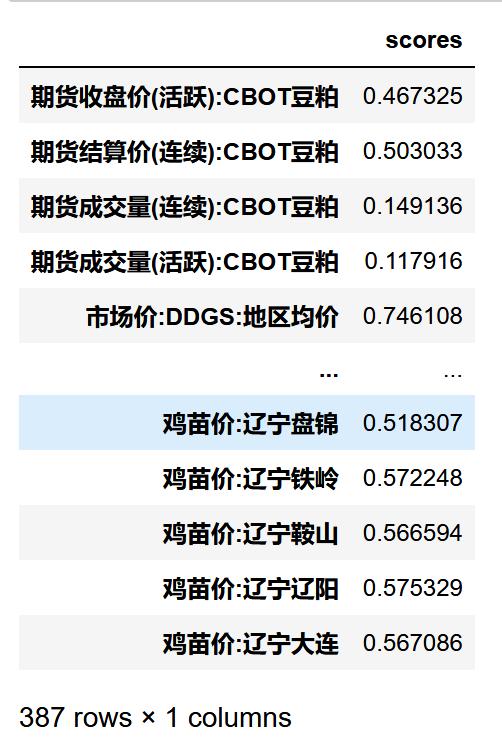 文章插图
文章插图排序
X_SKB_scores_sort=X_SKB_scores_0.sort_values(ascending=False,by="scores")X_SKB_scores_sort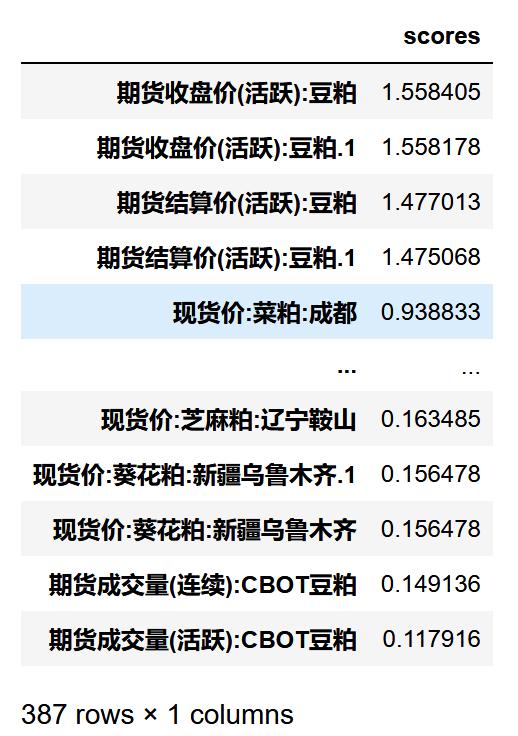 文章插图
文章插图查看相关性曲线
- 系列|Redmi Note9系列三剑客来袭,差别到底有多大?该如何选择?
- 替代|Firefox仍是市面上替代Chromium浏览器的唯一先进选择
- 购机|购机指南 2款5G千元机都有索尼6400万四摄 该如何选择?
- 上市公司|数字化新外贸成为企业巨头新选择 近百家上市公司入驻阿里国际站
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 端游玩家实惠不失性能的选择,雷蛇灵刃15标准版体验
- 解决多版本的python冲突问题