关于分类数据编码所需了解的所有信息(使用Python代码)( 三 )
默认情况下 , 哈希编码器使用md5哈希算法 , 但用户可以传递他选择的任何算法 。
import category_encoders as ceimport pandas as pd#Create the dataframedata=http://kandian.youth.cn/index/pd.DataFrame({'Month':['January','April','March','April','Februay','June','July','June','September']})#Create object for hash encoderencoder=ce.HashingEncoder(cols='Month',n_components=6)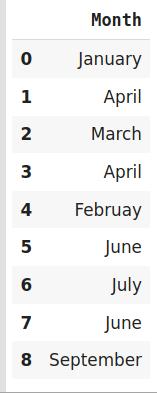 文章插图
文章插图
# 调整和转换数据encoder.fit_transform(data)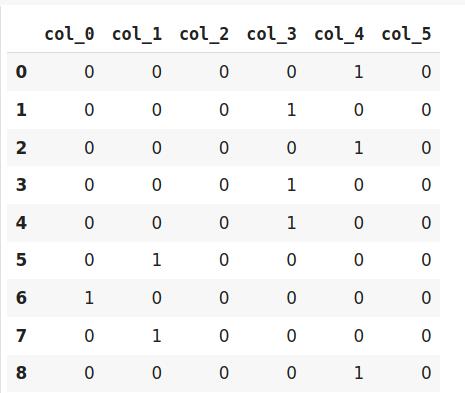 文章插图
文章插图
由于哈希将数据转换为较小的维度 , 因此可能导致信息丢失 。 哈希编码器面临的另一个问题是冲突 。 由于此处将大量特征描绘成较小的尺寸 , 因此可以用相同的哈希值表示多个值 , 这称为冲突 。
此外 , 哈希编码器在某些Kaggle比赛中非常成功 。 最好尝试一下数据集是否具有高基数特征 。
二进制编码二进制编码是哈希编码和独热编码的组合 。 在这种编码方案中 , 首先使用有序编码器将分类特征转换为数值 。 然后将数字转换为二进制数 。 之后 , 该二进制值将拆分为不同的列 。
当类别很多时 , 二进制编码的效果很好 。 例如 , 公司提供产品的国家/地区的城市 。
#Import the librariesimport category_encoders as ceimport pandas as pd#Create the Dataframedata=http://kandian.youth.cn/index/pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi','Hyderabad','Mumbai','Agra']})#Create object for binary encodingencoder= ce.BinaryEncoder(cols=['city'],return_df=True)# 原始数据data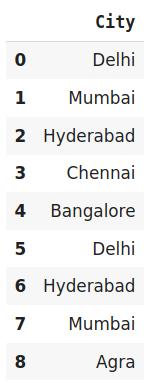 文章插图
文章插图
# 调整和转换数据 data_encoded=encoder.fit_transform(data) data_encoded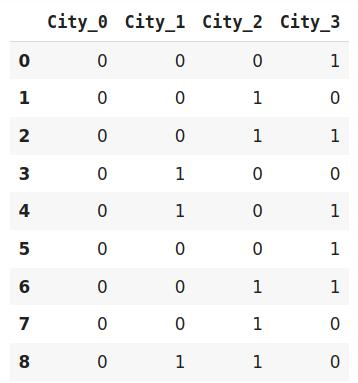 文章插图
文章插图
二进制编码是一种节省内存的编码方案 , 因为它比独热编码使用更少的特性 。 此外 , 它还减少了高基数数据的维数灾难 。
BaseN编码在开始使用BaseN编码之前 , 我们首先尝试了解什么是Base 。
在数字系统中 , “底数”或“基数”是数字的数目或用于表示数字的数字和字母的组合 。 我们一生中最常用的基数是10或十进制 , 因为在这里我们使用10个唯一数字 , 即0到9来代表所有数字 。 另一个广泛使用的系统是二进制 , 即基数为2 。 它使用0和1 , 即2位数字来表示所有数字 。
对于二进制编码 , 基数为2 , 这意味着它将类别的数值转换为其各自的二进制形式 。 如果要更改基本编码方案 , 则可以使用BaseN编码器 。 如果类别更多 , 而二进制编码无法处理维数 , 则可以使用更大的底数 , 例如4或8 。
#Import the librariesimport category_encoders as ceimport pandas as pd#Create the dataframedata=http://kandian.youth.cn/index/pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi','Hyderabad','Mumbai','Agra']})#Create an object for Base N Encodingencoder= ce.BaseNEncoder(cols=['city'],return_df=True,base=5)# 原始数据data文章插图
# 调整和转换数据data_encoded=encoder.fit_transform(data)data_encoded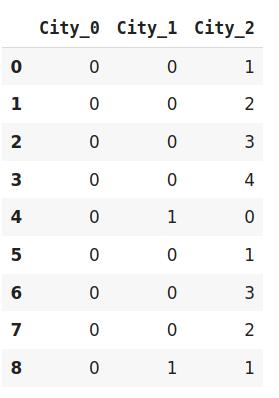 文章插图
文章插图
在上面的例子中 , 我使用了base5 , 也就是所谓的五元体系 。 它类似于二进制编码的例子 。 二进制编码用4个新特性表示相同的数据 , 而BaseN编码只使用3个新变量 。
因此 , BaseN编码技术进一步减少了有效表示数据和提高内存使用率所需的特征数量 。 基数N的默认基数是2 , 这相当于二进制编码 。
目标编码目标编码是一种贝叶斯编码技术 。
贝叶斯编码器使用来自相关/目标变量的信息对分类数据进行编码 。
在目标编码中 , 我们计算每个类别的目标变量的平均值 , 并用平均值替换类别变量 。 在分类目标变量的情况下 , 目标的后验概率代替每个类别 。
#import the librariesimport pandas as pdimport category_encoders as ce#创建数据框data=http://kandian.youth.cn/index/pd.DataFrame({'class':['A,','B','C','B','C','A','A','A'],'Marks':[50,30,70,80,45,97,80,68]})#创建目标编码对象encoder=ce.TargetEncoder(cols='class') # 原始数据Data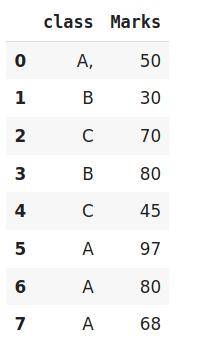 文章插图
文章插图
# 调整并转换数据encoder.fit_transform(data['class'],data['Marks'])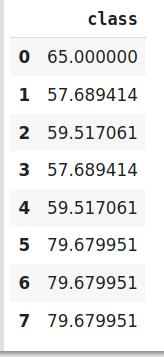 文章插图
文章插图
- 查询|数据太多容易搞混?掌握这几个Excel小技巧,办公思路更清晰
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- V2X|V2X:确保未来道路交通数据交换的安全性
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?
- 权属|从数据悖论到权属确认,数据共享进路所在
- 统计|多久才能换一次手机?统计机构数据有点意外
- 发展|大数据解读世界互联网大会·互联网发展论坛!
- 网购|黑色星期五及网购星期一大数据出炉 全球第三方卖家销售额超48亿美元
- Veeam|Veeam让企业数据拥有“第二次生命”