关于分类数据编码所需了解的所有信息(使用Python代码)( 二 )
 文章插图
文章插图
# 调整和转换数据data_encoded = encoder.fit_transform(data)data_encoded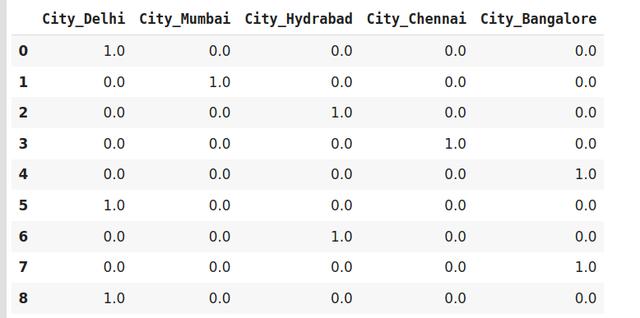 文章插图
文章插图
现在 , 让我们转到另一种非常有趣且广泛使用的编码技术 , 即虚拟编码 。
虚拟编码虚拟编码方案类似于独热编码 。 这种分类数据编码方法将分类变量转换为一组二进制变量(也称为虚拟变量) 。 在独热编码的情况下 , 对于变量中的N个类别 , 它使用N个二进制变量 。 虚拟编码是对独热编码的一个小改进 。 虚拟编码使用N-1个特征来表示N个标签/类别 。
为了更好地理解这一点 , 让我们看下面的图片 。 在这里 , 我们使用独热编码和虚拟编码技术对相同的数据进行编码 。 独热编码使用3个变量表示数据 , 而虚拟编码使用2个变量编码3个类别 。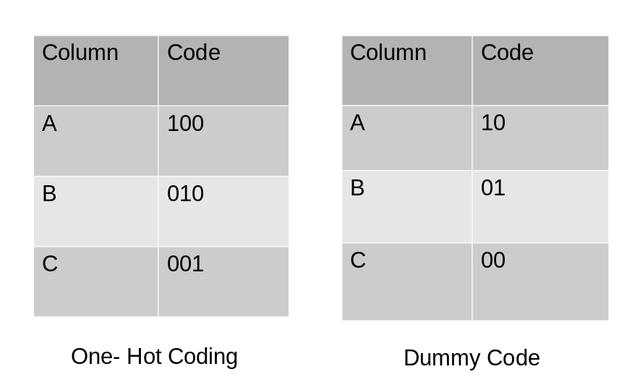 文章插图
文章插图
让我们在python中实现它 。
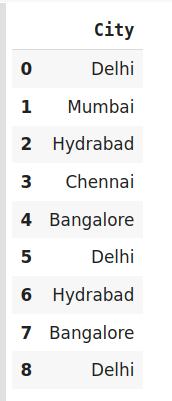
import category_encoders as ceimport pandas as pddata=http://kandian.youth.cn/index/pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi,'Hyderabad']})# 原始数据data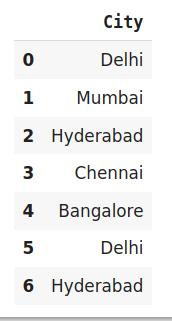 文章插图
文章插图
#编码数据data_encoded=pd.get_dummies(data=http://kandian.youth.cn/index/data,drop_first=True)data_encoded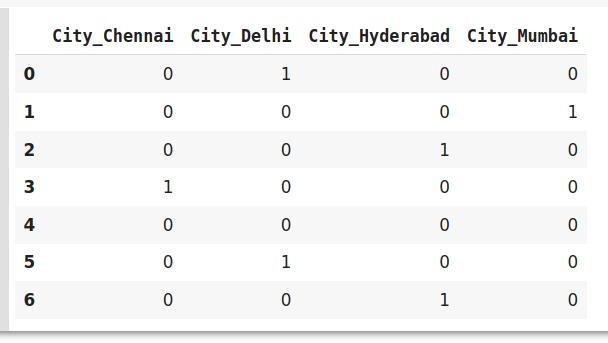 文章插图
文章插图
在这里 , 使用drop_first参数 , 我们使用0表示第一个标签Bangalore 。
独热和虚拟编码的缺点独热编码器和虚拟编码器是两种功能强大且有效的编码方案 。 它们在数据科学家中也很受欢迎 , 但在以下这些情况下可能不那么有效:
- 数据中存在大量级别 。 在这种情况下 , 如果一个特征变量中有多个类别 , 则我们需要相似数量的虚拟变量来对数据进行编码 。 例如 , 具有30个不同值的列将需要30个新变量进行编码 。
- 如果我们在数据集中具有多个分类特征 , 则将发生类似的情况 , 并且我们最终会有几个二进制特征 , 每一个都代表分类特征和它们的多个类别 , 例如一个包含10个或更多分类列的数据集 。
此外 , 它们可能会导致虚拟变量陷阱 。 这是特征高度相关的现象 。 这意味着使用其他变量 , 我们可以轻松预测变量的值 。
由于数据集的大量增加 , 编码使模型的学习变慢 , 并且整体性能下降 , 最终使模型的计算昂贵 。 此外 , 在使用基于树的模型时 , 这些编码不是最佳选择 。
效果编码(Effect Encoding)这种编码技术也称为偏差编码(Deviation Encoding)或求和编码(Sum Encoding) 。 效果编码几乎与虚拟编码类似 , 只是有一点点差异 。 在虚拟编码中 , 我们使用0和1表示数据 , 但在效果编码中 , 我们使用三个值 , 即1,0和-1 。
在虚拟编码中仅包含0的行在效果编码中被编码为-1 。 在虚拟编码示例中 , 索引为4的班加罗尔城市被编码为0000 。 而在效果编码中 , 它是由-1-1-1-1表示的 。
让我们看看我们如何在python中实现它
import category_encoders as ceimport pandas as pddata=http://kandian.youth.cn/index/pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi,'Hyderabad']}) encoder=ce.sum_coding.SumEncoder(cols='City',verbose=False,)# 原始数据data文章插图encoder.fit_transform(data)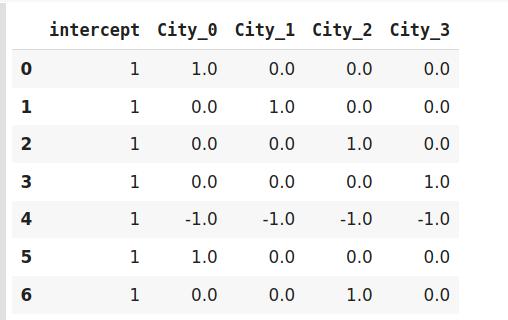 文章插图
文章插图哈希编码器要理解哈希编码 , 就必须了解哈希 。 哈希是以固定大小值的形式对任意大小的输入进行的转换 。 我们使用哈希算法来执行哈希操作 , 即生成输入的哈希值 。
此外 , 哈希是一个单向过程 , 换句话说 , 不能从哈希表示生成原始输入 。
散列有几个应用 , 如数据检索、检查数据损坏以及数据加密 。 我们有多个哈希函数可用 , 例如消息摘要(MD、MD2、MD5)、安全哈希函数(SHA0、SHA1、SHA2)等等 。
就像独热编码一样 , 哈希编码器使用新的维度来表示分类特性 。 在这里 , 用户可以使用n_component参数来确定转换后的维度数量 。 这就是我的意思——一个有5个类别的特征可以用N个新特征来表示 。 同样 , 一个有100个类别的特征也可以用N个新特征来转换 。 听起来不错吧?
- 查询|数据太多容易搞混?掌握这几个Excel小技巧,办公思路更清晰
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 健身房|乐刻韩伟:产业互联网中只做单环节很难让数据发挥大作用
- V2X|V2X:确保未来道路交通数据交换的安全性
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?
- 权属|从数据悖论到权属确认,数据共享进路所在
- 统计|多久才能换一次手机?统计机构数据有点意外
- 发展|大数据解读世界互联网大会·互联网发展论坛!
- 网购|黑色星期五及网购星期一大数据出炉 全球第三方卖家销售额超48亿美元
- Veeam|Veeam让企业数据拥有“第二次生命”