mysql优化篇(基于索引)( 六 )
 文章插图
文章插图
inner join下的一个坑点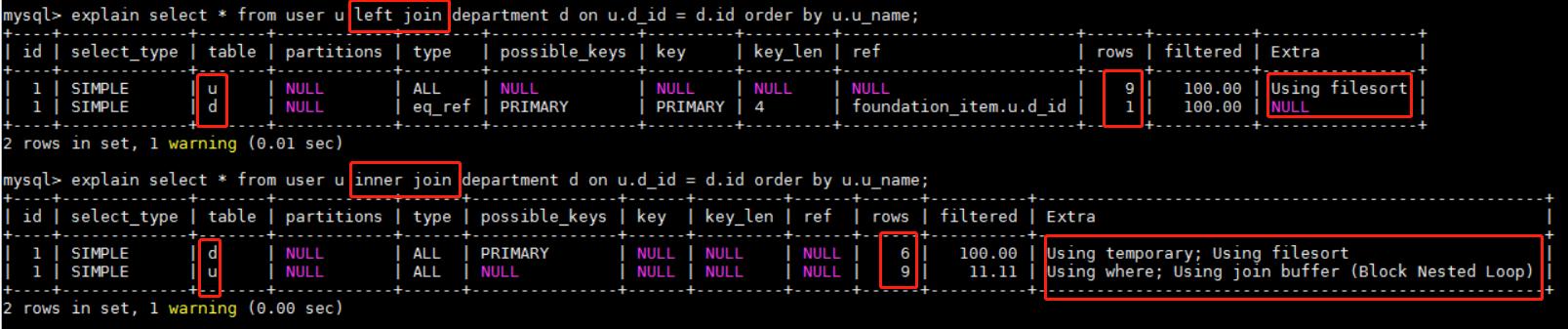 文章插图
文章插图
面对如上情况的问题 , 可以使用如下的方式试试(执行计划差不多 , 有点区别 , 数据量很大的情况下可以试试 , 我也不确定速度会怎样 , 可能会好些 , 可以过滤掉一些数据 , 在不同的业务场景下可以尝试对比) 文章插图
文章插图
有时候filesort是无法避免的 , 但是还是可以做一些优化的:
- 对于使用filesort的慢查询 , 增大一些max_length_for_sort_data来使用单路排序
- 增加sort_buffer_size的大小 , 如果大量的查询较小的话 , 这个很好 , 就缓存中就搞定了
- 增加read_rnd_buffer_size大小 , 可以一次性多读到内存中
- 列的长度尽量小些(去掉不必要的返回字段)
- 改变tmpdir , 使其指向多个物理盘(不是分区)的目录 , 这将机会循环使用做为临时文件区
由于group by实际上也同样会进行排序操作 , 而且与group by相比 , group by 主要只是多了排序之后的分组操作 。 当然 , 如果在分组的时候还使用了其他的一些聚合函数 , 那么还需要一些聚合函数的计算 。 所以 , 在group by 的实现过程中 , 与 group by一样也可以利用到索引 。
由于group by无非就是用到索引和用不到索引的情况 , 用到索引的时候走索引速度快 , 用不到的情况用临时文件 , 所以会慢一些 , 其实就是在排序后分组 , 既然不能走索引的话就可以根据order by不能走索引 , 使用filesort的优化策略一样就好了 , 走索引的情况就要符合索引的最左前缀原则 , 这里不再深入的讨论group by的原理 , 有兴趣的可以自行去理解 , 反正我认为回了order by的优化就基本根据套路来优化group by 。
还有就是能在where中过滤掉的就不要等到hiving过滤 。
3.5、索引失效情况优化很多时候明明创建了索引 , 就是使用的过程中不走索引 , 所以有时候也会很苦恼 , 我们就来看看哪些情况不走索引(注意:如下的任何优化方式都是通过explain做理论支撑的 , 没有在实际的生成环境中跑过 , 所以有时候速度快不快也要看表的设计 , 索引的设计 , 数据量的大小等)
1、使用 like '%%' #使用like的时候要注意%在最左边的时候是不会走索引的 , 其他的方式会走索引
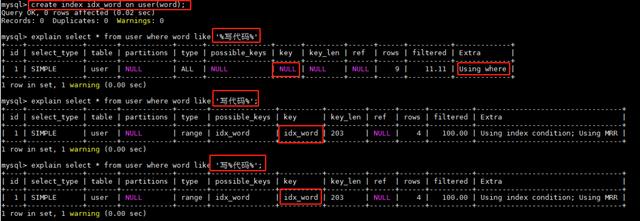 文章插图
文章插图如上方式可以修改成: explain select * from (select id from user where word like '%写代码1%') a inner join user u on a.id = u.id; 其中id为主键索引 。 源于《深入浅出mysql:数据开发、优化与管理维护(第二版)》 , 我也不知道这个会不会有速度提升 , 毕竟type是index , 建立索引后的word列的type是range , 接下来我们把word上的索引去掉看看 。
 文章插图
文章插图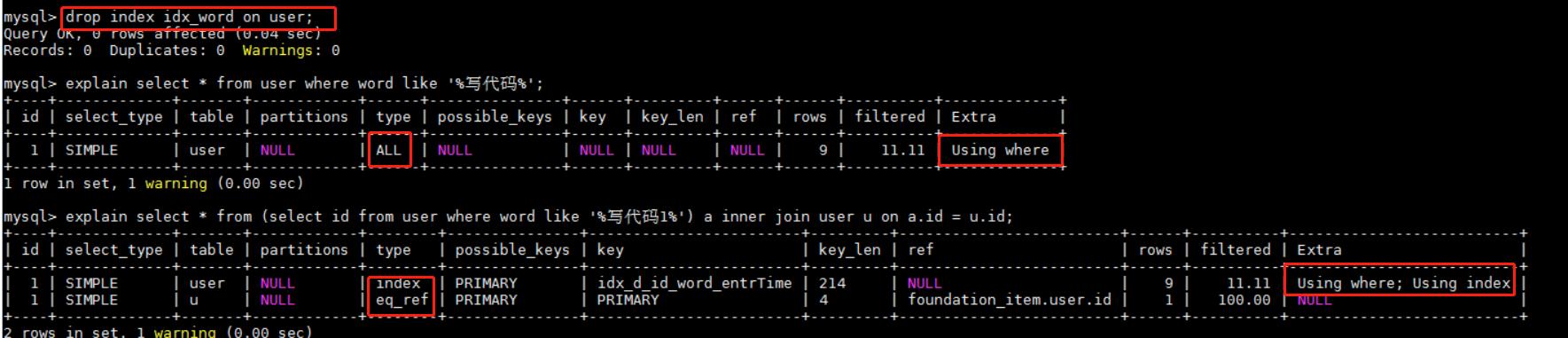 文章插图
文章插图可以细细体会下如上的过程 , 在没有建立索引的情况下使用join这个写法速度快没问题 , 但是在建立索引的情况下 , 估计没得快(这里有条件的话可以去测试一下) , 所以对于like '%%'这种写法 , 在不能创建索引的情况下就使用join , 可以创建索引的情况下就添加索引 。
2、在where中使用函数 , 计算 , 类型转换等不会走索引 。
文章插图mysql> create index d_word on user(word); #创建索引Query OK, 0 rows affected (0.02 sec)Records: 0Duplicates: 0Warnings: 0mysql> explain select * from user where word= 'c写代码2'; #使用等值查询 , 使用到了索引+----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+| id | select_type | table | partitions | type | possible_keys | key| key_len | ref| rows | filtered | Extra |+----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+|1 | SIMPLE| user| NULL| ref| d_word| d_word | 203| const |1 |100.00 | NULL|+----+-------------+-------+------------+------+---------------+--------+---------+-------+------+----------+-------+1 row in set, 1 warning (0.00 sec)mysql> explain select * from user where left(word,1)= 'c'; #在where中使用了函数或者计算 , 全表扫描没有使用到索引+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key| key_len | ref| rows | filtered | Extra|+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+|1 | SIMPLE| user| NULL| ALL| NULL| NULL | NULL| NULL |9 |100.00 | Using where |+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+1 row in set, 1 warning (0.00 sec)
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- 优化|微软亚洲研究院发布开源平台“群策 MARO” 用于多智能体资源调度优化
- 一图看懂!数字日照、新型智慧城市这样建(上篇)|政策解读 | 新型
- 人工智能|人工智能只会“优化”,而人类可以“进化”
- 工艺|食用油你懂了吗?篇二谈谈加工工艺
- 腔体|发烧音频速报 篇七十二:五百元价位标杆产品,Whizzer威泽Kylin HE01双腔体动圈耳机
- pymysql 连接 MySQL 实现简单登录
- 极致优化 IDEA 启动速度(本文内容过于硬核)
- 使用百度资源平台数据可以挖掘出哪些适合优化的有价值的关键
- D3学习手记 - 02 - 数据绑定