mysql优化篇(基于索引)( 四 )
- 频繁更新的字段
- where条件用不到的字段
- 表记录太少
- 经常增删改的表
- 数据重复且分布平均的表字段
 文章插图
文章插图View Code
MySQL内部采用了一种叫做 nested loop join的算法 。 Nested Loop Join 实际上就是通过驱动表的结果集作为循环基础数据 , 然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据 , 然后合并结果 。 如果还有第三个参与 Join , 则再通过前两个表的 Join 结果集作为循环基础数据 , 再一次通过循环查询条件到第三个表中查询数据 , 如此往复 , 基本上MySQL采用的是最容易理解的算法来实现join 。 (一定要用小表驱动大表)
看看这些表的索引情况:
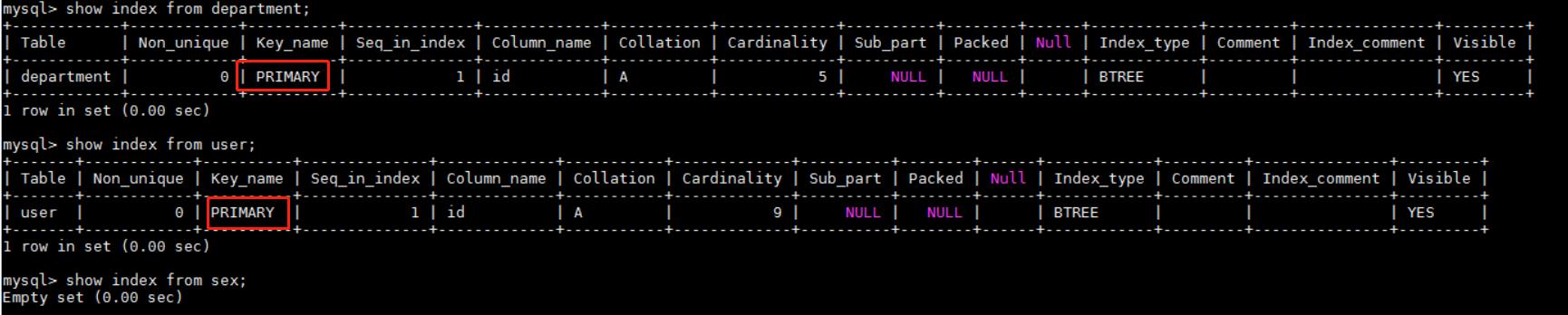 文章插图
文章插图除了两个表的主键自动创建的主键索引外 , 没有其他的任何索引 。
explain select * from department d left join user u on u.d_id = d.id;
 文章插图
文章插图两个表都是全表扫描呢 , 命名department表在id上有主键索引呢 , 但是作为左连接 , department需要保留全部的数据 , 所以建立索引是没什么影响的 , 接下来我们在user表上建立d_id的索引idx_d_id: create index idx_d_id on user (d_id);
 文章插图
文章插图看结果可以得出user表使用了索引 , 减少了数据的读取 , 可以得出left join主要的优化在于右表的索引的创建 , 那right join也是一样在于左表的索引的情况 , 对于inner join呢?我们看看 。
在user表没有建立idx_d_id索引前:
 文章插图
文章插图在user表没有建立idx_d_id索引后:
 文章插图
文章插图好像优化器会选择把小的表来驱动大的表 , 全表扫描小的表 , 大的表走索引 。
这是两个表的lefter join和right join的情况 , 那三个表的呢?还是上面的原则 , 有一个表会全保留 , 其他的走索引就好了 。 所以就是小表用来做驱动 , 大表用来走索引 , 这样就可以提高left join和right join的速度了 。 当然索引也要合适 。。
3.4、order by和group by优化1、order by
order by:就是排序 , 我们都知道InnoDB存储引擎的存储是根据主键按照顺序存储的 , 所以这些都是已经排好序的 , 但是我们又不仅仅是根据主键排序 , 还要更加其他列进行排序 , 这样又怎么弄呢 , 当然我们可以在这些列上建立索引呀(单列 , 或者组合索引 , 推荐组合) , 索引就是有序的 , 这样就不用额外的排序了 , 但是不可能每个列都创建好索引吧 , 还有就是默认的是asc排序 , 那desc排序呢 , 又当如何呢 , 这就会造成filesort , 虽然可以排序 , 但是效率真的低 , 所以尽量不要使用 。 既然order by有两种排序 , 一种是通过索引的默认排序这样的速度好 , 还有就是filesort , 但是filesort如何去优化下呢?
在MySQL中filesort 的实现算法实际上是有两种:
- 双路排序:是首先根据相应的条件取出相应的排序字段和可以直接定位行数据的行指针信息 , 然后在sort buffer 中进行排序 。
- 单路排序:是一次性取出满足条件行的所有字段 , 然后在sort buffer中进行排序 。
MySQL主要通过比较我们所设定的系统参数 max_length_for_sort_data的大小和Query 语句所取出的字段类型大小总和来判定需要使用哪一种排序算法 。 如果 max_length_for_sort_data更大 , 则使用第二种优化后的算法 , 反之使用第一种算法 。 所以如果希望 ORDER BY 操作的效率尽可能的高 , 一定要注意max_length_for_sort_data 参数的设置 。
是有filesort的情况(说白了就是不走索引):
- where语句与order by语句 , 使用了不同的索引
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- 优化|微软亚洲研究院发布开源平台“群策 MARO” 用于多智能体资源调度优化
- 一图看懂!数字日照、新型智慧城市这样建(上篇)|政策解读 | 新型
- 人工智能|人工智能只会“优化”,而人类可以“进化”
- 工艺|食用油你懂了吗?篇二谈谈加工工艺
- 腔体|发烧音频速报 篇七十二:五百元价位标杆产品,Whizzer威泽Kylin HE01双腔体动圈耳机
- pymysql 连接 MySQL 实现简单登录
- 极致优化 IDEA 启动速度(本文内容过于硬核)
- 使用百度资源平台数据可以挖掘出哪些适合优化的有价值的关键
- D3学习手记 - 02 - 数据绑定