c/c++后台开发必知堆与栈的区别( 二 )
从以上可以看到 , 堆和栈相比 , 由于大量malloc()/free()或new/delete的使用 , 容易造成大量的内存碎片 , 并且可能引发用户态和核心态的切换 , 效率较低 。 栈相比于堆 , 在程序中应用较为广泛 , 最常见的是函数的调用过程由栈来实现 , 函数返回地址、EBP、实参和局部变量都采用栈的方式存放 。 虽然栈有众多的好处 , 但是由于和堆相比不是那么灵活 , 有时候分配大量的内存空间 , 主要还是用堆 。
无论是堆还是栈 , 在内存使用时都要防止非法越界 , 越界导致的非法内存访问可能会摧毁程序的堆、栈数据 , 轻则导致程序运行处于不确定状态 , 获取不到预期结果 , 重则导致程序异常崩溃 , 这些都是我们编程时与内存打交道时应该注意的问题 。
需要C/C++ Linux高级服务器架构师学习资料后台私信“资料”(包括C/C++ , Linux , golang技术 , Nginx , ZeroMQ , MySQL , Redis , fastdfs , MongoDB , ZK , 流媒体 , CDN , P2P , K8S , Docker , TCP/IP , 协程 , DPDK , ffmpeg等) 文章插图
文章插图
2.数据结构中的堆与栈数据结构中 , 堆与栈是两个常见的数据结构 , 理解二者的定义、用法与区别 , 能够利用堆与栈解决很多实际问题 。
2.1 栈简介【c/c++后台开发必知堆与栈的区别】栈是一种运算受限的线性表 , 其限制是指只仅允许在表的一端进行插入和删除操作 , 这一端被称为栈顶(Top) , 相对地 , 把另一端称为栈底(Bottom) 。 把新元素放到栈顶元素的上面 , 使之成为新的栈顶元素称作进栈、入栈或压栈(Push);把栈顶元素删除 , 使其相邻的元素成为新的栈顶元素称作出栈或退栈(Pop) 。 这种受限的运算使栈拥有“先进后出”的特性(First In Last Out) , 简称FILO 。
栈分顺序栈和链式栈两种 。 栈是一种线性结构 , 所以可以使用数组或链表(单向链表、双向链表或循环链表)作为底层数据结构 。 使用数组实现的栈叫做顺序栈 , 使用链表实现的栈叫做链式栈 , 二者的区别是顺序栈中的元素地址连续 , 链式栈中的元素地址不连续 。
栈的结构如下图所示: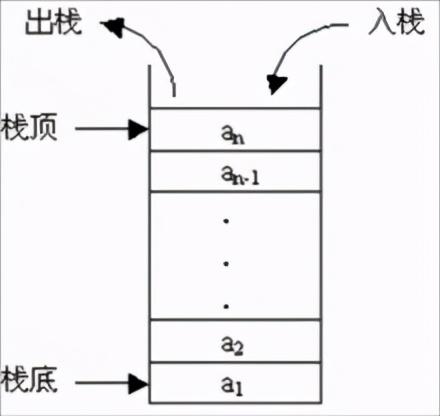 文章插图
文章插图
栈的基本操作包括初始化、判断栈是否为空、入栈、出栈以及获取栈顶元素等 。 下面以顺序栈为例 , 使用 C++ 给出一个简单的实现 。
#include#include运行上面的程序 , 输出结果:
当前栈中的元素:754top element is 7pop top element is 72.2 堆简介2.2.1 堆的性质堆是一种常用的树形结构 , 是一种特殊的完全二叉树 , 当且仅当满足所有节点的值总是不大于或不小于其父节点的值的完全二叉树被称之为堆 。 堆的这一特性称之为堆序性 。 因此 , 在一个堆中 , 根节点是最大(或最小)节点 。 如果根节点最小 , 称之为小顶堆(或小根堆) , 如果根节点最大 , 称之为大顶堆(或大根堆) 。 堆的左右孩子没有大小的顺序 。 下面是一个小顶堆示例: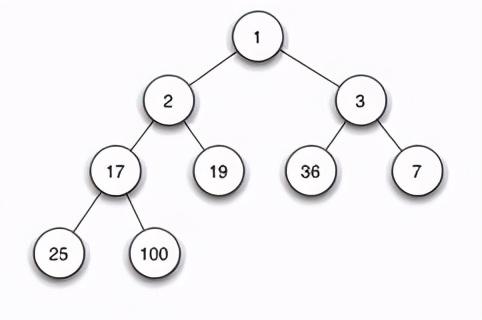 文章插图
文章插图
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 开发自|不妥协不追随 Member’s Mark升级背后的“山姆哲学”
- 确认|三星确认正在开发“轻薄轻巧”的可折叠手机
- 推广|Josh Elman加盟苹果 负责开发者关系与软件推广工作
- 微信广告|小程序开发者看过来 流量变现倍增的秘籍来了!
- 移植|开发者将移植ARM Mac的Linux系统 但需要得到资金支持
- GNOME|[图]GNOME启动Circle项目:进一步扩大开发者规模
- 检查|填补软件开发市场空白,飞算全自动软件工程平台瞄准全自动后端微服务开发
- 格式化|利用好这3个隐藏技巧,Power BI 开发体验更丝滑
- 开发|三七数字产业平台率先在全国开发应用