Lyft 基于 Flink 的大规模准实时数据分析平台( 二 )
 文章插图
文章插图
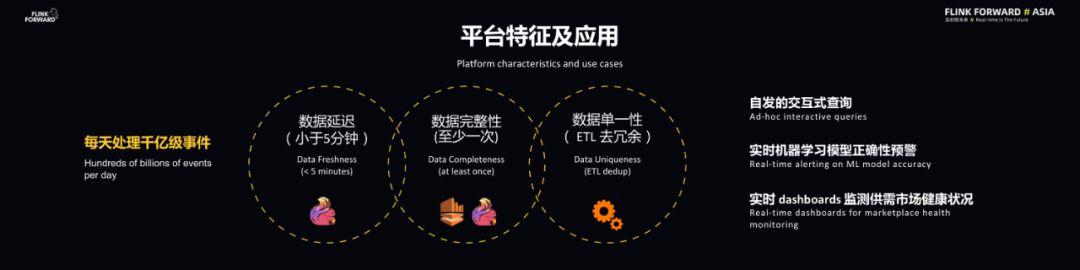
数据科学家和数据工程师在建模时会需要进行自发的交互式查询 , 此外 , 平台也会提供实时机器学习模型正确性预警 , 以及实时数据面板来监控供需市场健康状况 。
4. 基于 Flink 的准实时数据导入
下图可以看到当事件到达 Kinesis 之后就会被存储成为 EventBatch 。 通过 Flink-Kinesis 连接器可以将事件提取出来并送到 FlatMap 和 Record Counter 上面 , FlatMap 将事件打撒并送到下游的 Global Record Aggregator 和 Tagging Partitioning 上面 , 每当做 CheckPoint 时会关闭文件并做一个持久化操作 , 针对于 StreamingFileSink 的特征 , 平台设置了每三分钟做一次 CheckPoint 操作 , 这样可以保证当事件进入 Kinesis 连接器之后在三分钟之内就能够持久化 。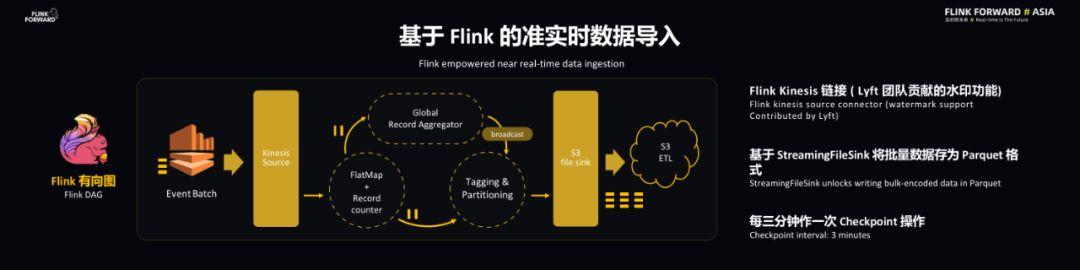 文章插图
文章插图
以上的方式会造成太多数量的小文件问题 , 因为数据链路支持成千上万种文件 , 因此使用了 Subtasks 记录本地事件权重 , 并通过全局记录聚合器来计算事件全局权重并广播到下游去 。 而 Operator 接收到事件权重之后将会将事件分配给 Sink 。
5. ETL 多级压缩和去重
上述的数据链路也会做 ETL 多级压缩和去重工作 , 主要是 Parquet 原始数据会经过每小时的智能压缩去重的 ETL 工作 , 产生更大的 Parquet File 。 同理 , 对于小时级别压缩去重不够的文件 , 每天还会再进行一次压缩去重 。 对于新产生的数据会有一个原子性的分区交换 , 也就是说当产生新的数据之后 , ETL Job 会让 Hive metastore 里的表分区指向新的数据和分区 。 这里的过程使用了启发性算法来分析哪些事件必须要经过压缩和去重以及压缩去重的时间间隔级别 。 此外 , 为了满足隐私和合规的要求 , 一些 ETL 数据会被保存数以年计的时间 。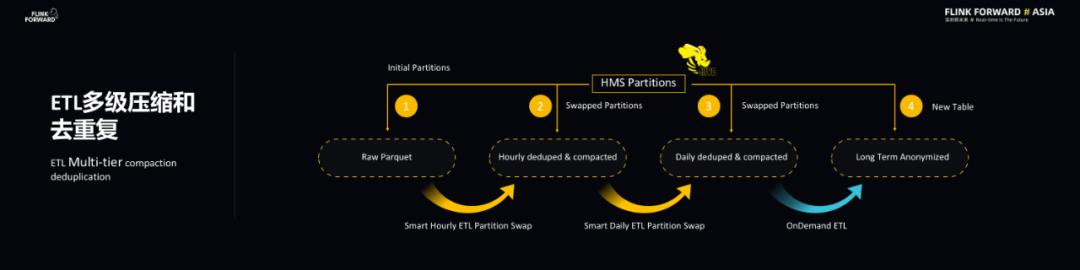 文章插图
文章插图
03
平台性能及容错深入分析
1. 事件时间驱动的分区感测
Flink 和 ETL 是通过事件时间驱动的分区感测实现同步的 。 S3 采用的是比较常见的分区格式 , 最后的分区是由时间戳决定的 , 时间戳则是基于 EventTime 的 , 这样的好处在于能够带来 Flink 和 ETL 共同的时间源 , 这样有助于同步操作 。 此外 , 基于事件时间能够使得一些回填操作和主操作实现类似的结果 。 Flink 处理完每个小时的事件后会向事件分区写入一个 Success 文件 , 这代表该小时的事件已经处理完毕 , ETL 可以对于该小时的文件进行操作了 。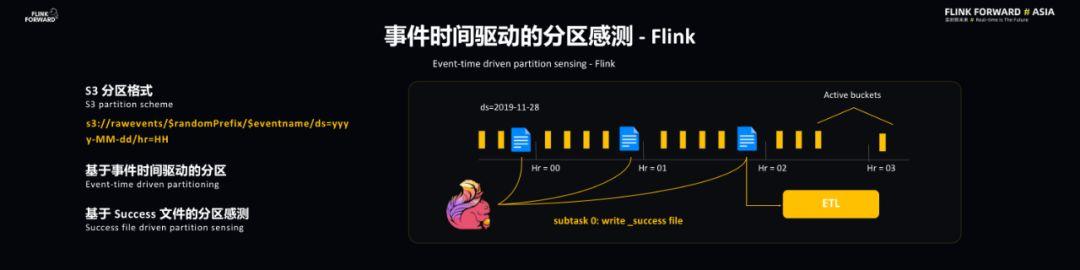 文章插图
文章插图
Flink 本身的水印并不能直接用到 Lyft 的应用场景当中 , 主要是因为当 Flink 处理完时间戳并不意味着它已经被持久化到存储当中 , 此时就需要引入分区水印的概念 , 这样一来每个 Sink Source 就能够知道当前写入的分区 , 并且维护一个分区 ID , 并且通过 Global State Aggregator 聚合每个分区的信息 。 每个 Subtasks 能够知道全局的信息 , 并将水印定义为分区时间戳中最小的一个 。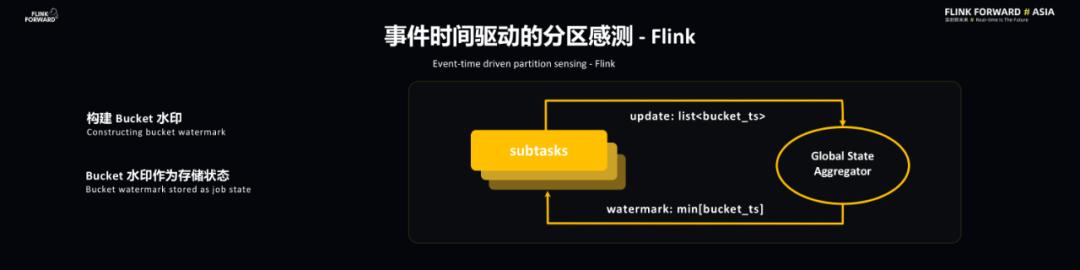 文章插图
文章插图
ETL 主要有两个特点 , 分别是及时性和去重 , 而 ETL 的主要功能在于去重和压缩 , 最重要的是在非阻塞的情况下就进行去重 。 前面也提到 Smart ETL , 所谓 Smart 就是智能感知 , 需要两个相应的信息来引导 Global State Aggregator , 分别是分区完整性标识 SuccessFile , 在每个分区还有几个相应的 States 统计信息能够告诉下游的 ETL 怎样去重和压缩以及操作的频率和范围 。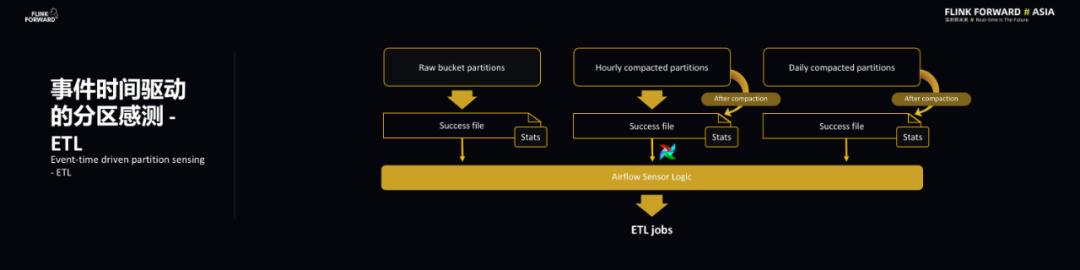 文章插图
文章插图
2. Schema 演进的挑战
ETL 除了去重和压缩的挑战之外 , 还经常会遇到 Schema 的演化挑战 。 Schema 演化的挑战分为三个方面 , 即不同引擎的数据类型、嵌套结构的演变、数据类型演变对去重逻辑的影响 。 文章插图
文章插图
3. S3 深入分析
Lyft 的数据存储系统其实可以认为是数据湖 , 对于 S3 而言 , Lyft 也有一些性能的优化考量 。 S3 本身内部也是有分区的 , 为了使其具有并行的读写性能 , 添加了 S3 的熵数前缀 , 在分区里面也增加了标记文件 , 这两种做法能够极大地降低 S3 的 IO 性能的影响 。 标识符对于能否触发 ETL 操作会产生影响 , 与此同时也是对于 presto 的集成 , 能够让 presto 决定什么情况下能够扫描多少个文件 。
- 科技成果|“基于第三代半导体光源的低投射比投影仪关键技术”通过科技成果评价
- 头条|超越总统选举?优步和Lyft的22号提案上头条
- 如何基于Python实现自动化控制鼠标和键盘操作
- 需要更换手机了:基于手机构建无人驾驶微型汽车
- 蓝鲸专访|水滴CTO邱慧:基于业务场景做技术创新,用户需求可分析并唤醒
- GPU|干货|基于 CPU 的深度学习推理部署优化实践
- Python编程:一个基于PyQt的Led控件库,建议收藏
- Canal探究
- 基于Ansible和CodeDeploy的DevOps方案
- 微软|微软新专利:基于肢体语言的会议“评分”系统