七牛云 Niu Talk 数据科学论坛第三期:大数据开发与开源生态
近日 , 「七牛云 Niu Talk 」 数据科学系列论坛第三期如期举行 ,三位嘉宾围绕大数据开发与开源生态 , 结合自己多年行业经验 , 带来关于「大数据开发与开源生态」的精彩演讲和圆桌对话 。 文章插图
文章插图
【七牛云 Niu Talk 数据科学论坛第三期:大数据开发与开源生态】主持人 上海开源信息技术协会副秘书长 赵生宇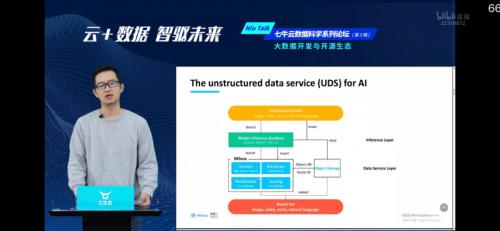 文章插图
文章插图
Zilliz 合伙人、首席布道师 顾钧 分享
Zilliz 合伙人、首席布道师顾钧在主题《 Unstructured Data Search Engine in AI Era 》分享中 , 畅聊非结构化数据服务 。 随着技术的发展和人与人之间互动方式的改变 , 图片、视频、语音、文本等非结构化数据正在快速而持续的增长 。 智慧城市 , 短视频 , 商品个性化推荐 , 视觉商品搜索等新兴应用领域对非结构化数据分析与搜索提出了更高的要求 。 顾钧结合 Zilliz 自研开源向量搜索引擎 Milvus 实践经验 , 分享如何帮助用户构建高效的非结构化数据服务 。 文章插图
文章插图
Databricks 开源技术负责人 范文臣 分享
技术的进步和新的解决方案 , 很多都与开源工具有很大关系 , 开源生态一直是技术人关注的热点话题 , Databricks 开源技术负责人 , Spark 社区最活跃的贡献者之一范文臣带来分享《基于 Spark 的高性能查询引擎》 。
随着 IO 硬件性能的不断提升 , 越来越多的查询引擎针对 CPU 进行优化 。 本次演讲范文臣为大家分享了 Databricks 如何结合当前的硬件趋势和公司的 Workload 趋势 , 构建向量化查询引擎 Photon , 以及构建过程中的一些实践经验 。 这款查询引擎 , 通过向量化、CPU 并行和指令集并行的方式获得更好的性能 。 文章插图
文章插图
圆桌讨论
对于开源项目和商业化产品之间的关系 , 三位嘉宾贡献了自己的想法 , 在矛盾与统一之间寻求平衡 。 对于开发者特别感兴趣的基金会 , 深入了解 Linux 和 Apache 基金会的两位嘉宾 , 对于开发者进行了回答 , 努力帮助更多开发者提供良好生态环境 , 为项目落地提供更多可能 。 同时面对中国开发者 , 基于开源生态和商业化的现状进行了解读 , 同时对于如何建设开源社区也分享了自己的想法 。
随着云计算跟大数据的深入人心 , 所有行业都在发生着或大或小的变化 , 数据中的商业价值也愈发突显 , 「七牛云 Niu Talk 」数据科学论坛集结技术大咖 , 围绕大数据价值、技术实践 , 以及企业面临数字化转型所遇到的困难与挑战进行了深入探讨和分享 。
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 建设|《青岛市城市云脑建设指引》发布
- 和谐|人民日报海外版今日聚焦云南西双版纳 看科技如何助力人象和谐
- 服务平台|HashiCorp发布多云服务平台Consul 1.9版
- 物种|苏宁易购赋能落地“新物种”旗下云网万店A轮融资60亿
- 电商|直播电商风云巨变,新一波红利路在何方?
- 方志|(社会)贵州上线“方志云”激活地方志价值
- 科技|短视频行业领先 云想科技成长空间广阔
- 中国首富又换人了?马云凭100亿优势超越马化腾,网友:厉害了
- 创园|中国V谷的云存储之道,马栏山文创园将视频处理效率提升6倍