FedReID - 联邦学习在行人重识别上的首次深入实践
 文章插图
文章插图
作者 | 庄伟铭
编辑 | 陈大鑫
行人重识别的训练需要收集大量的人体数据到一个中心服务器上 , 这些数据包含了个人敏感信息 , 因此会造成隐私泄露问题 。
联邦学习是一种保护隐私的分布式训练方法 , 可以应用到行人重识别上 , 以解决这个问题 。
但是在现实场景中 , 将联邦学习应用到行人重识别上因为数据异构性 , 会导致精度下降和收敛的问题 。
数据异构性:数据非独立分布 (non-IID) 和 各端数据量不同 。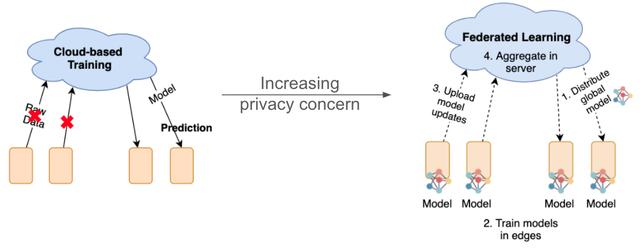 文章插图
文章插图
本文介绍一篇来自 ACMMM20 Oral 的论文 , 这篇论文主要通过构建一个 benchmark , 并基于 benchmark 结果的深入分析 , 提出两个优化方法 , 提升现实场景下联邦学习在行人重识别上碰到的数据异构性问题 。 文章插图
文章插图
论文地址:
开源代码:
论文第一作者:庄伟铭 , 商汤和新加坡南洋理工大学联合博士项目二年级学生 , 导师是文勇刚教授 , 本科毕业于新加坡国立大学 , 现在主要进行联邦学习相关的研究 。
本文主要对这篇文章的这三个方面内容做简要介绍:
- Benchmark: 包括数据集、新的算法、场景等
- Benchmark 的结果分析
- 优化方法:知识蒸馏、权重重分配
数据集
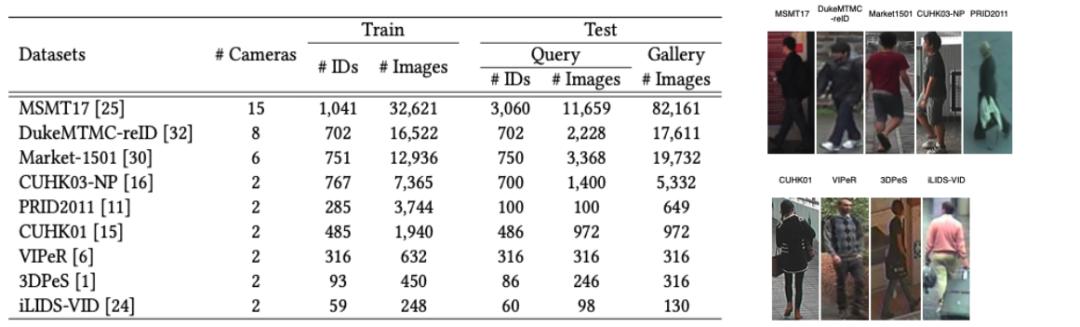
数据集由9个最常用的 行人重识别 数据集构成 , 具体的信息如下:
 文章插图
文章插图这些数据集的数据量、ID数量、领域都不同 , 能够有效的模拟现实情况下的数据异构性问题 。
算法
传统联邦学习算法 Federated Averaging (FedAvg) 要求端边全模型同步 , 但是 ReID 的分类层的维度由 ID数量决定 , 很可能是不同的 。
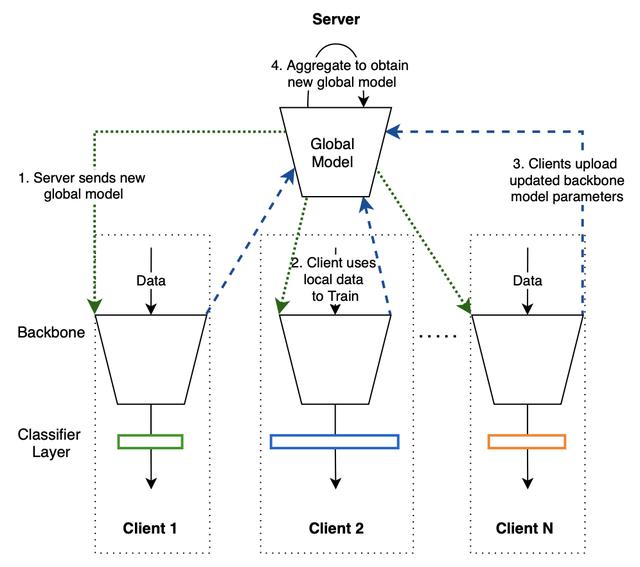
所以这篇论文提出了只同步部分的模型 Federated Partial Averaging (FedPav).
 文章插图
文章插图FedPav 的每一轮训练可以通过4个步骤完成:
- Server 下发一个全局模型到每个 Client
- 每个 Client 收到全局模型后 , 将全局模型加上本地的分类器 , 用本地数据进行训练 , 每个 Client 得到一个 local model
- Client 将 local model 的 backbone 上传到 Server
- Server 对所有 client 收到的 model 进行加权平均 。
 文章插图
文章插图2 Benchmark结果
通过 Benchmark 的实验 , 论文里描述了不少联邦学习和行人重识别结合的洞见 。 这边着重提出两点因数据异构性导致的问题 。
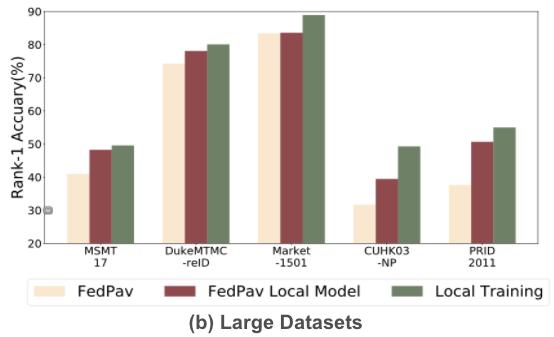
1. 大数据集在联邦学习中的精度低于单个数据集训练的精度
 文章插图
文章插图- FedPav: 联邦学习模型的精度
- FedPav Local Model: 联邦学习各边端模型模型上传前在各自边端测试的精度
- Local Training: 基准 , 每个数据集单独训练和测试的精度
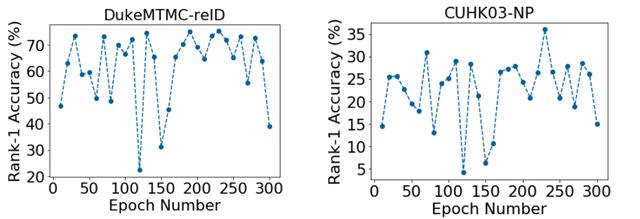
2. 联邦学习训练不收敛
 文章插图
文章插图通过这两个数据集测试曲线可以看出 , 因为数据异构性的影响 , 精度波动较大 , 收敛性差 。
3 优化方法
【FedReID - 联邦学习在行人重识别上的首次深入实践】采用知识蒸馏 , 提高收敛
因为数据的异构性的原因 , 导致参与联邦学习多方上传前的本地模型的性能优于云端服务器进行模型融合后的模型性能 , 另外数据异构性还导致了训练的不稳定性和难收敛的问题 。
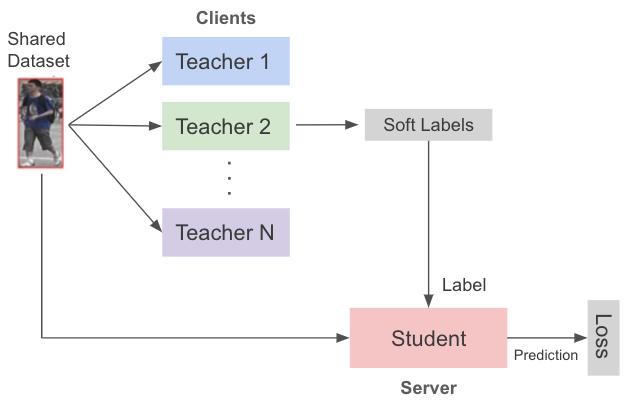
针对这个问题 , 本方案提出使用知识蒸馏的方法 , 将参与联邦学习的多方的本地模型当成教师模型 , 云端服务器的模型作为学生模型 , 用知识蒸馏的方法更好的将教师模型的知识传递到学生模型 , 以此提高了模型训练的稳定性和收敛性 。
完整算法可以参考下图:
 文章插图
文章插图 文章插图
文章插图下面的实验结果显示 , 采用知识蒸馏(橙线)的训练收敛效果能够得到有效提高 。
- 用于|用于半监督学习的图随机神经网络
- 今日|“舜网”学习强国号今日上线 济南报业全媒体矩阵再添新成员
- SK|SK电讯推出自研AI芯片SAPEON X220 深度学习计算速度是常用GPU 1.5倍
- 效果|这个让你相见恨晚的技巧,能让PPT排版更加有设计感,推荐学习
- 学习C语言的软件,就突然被我绿了?
- 学习python第二弹
- 喵喵机错题打印机P1:随时打印,随时学习,快速整理错题
- 爱可可AI论文推介(10月17日)
- D3学习手记 - 02 - 数据绑定
- TOP8无代码平台:2020年,这些机器学习平台不容错过