索引结构|每秒14亿次PolarDB如何应对双11“尖峰时刻”( 三 )
文章插图
并行schema变更
在阿里的业务中大量的POLARDB承载了超大规模的数据,然而业务的需求是实时变化的。过去对这些大表做DDL会持续数小时甚至数天,如此之高的延迟是难以容忍的。以创建二级索引为例,过高延迟的DDL操作会阻塞后续依赖新索引查询的DML操作。DDL操作会消耗CPU/Memory/IO资源,对业务DML带来一定的影响,因此用户往往在业务低峰期进行schema变更,但是如果不能确保变更在业务低峰期之内完成会对业务的稳定性产生严重的影响。
我们认为大表DDL运行缓慢的根本原因在于传统的DDL操作是针对单核和传统硬盘设计的。
随着多核处理器的日益发展和高速存储的普及,DDL的并行化是可以取得非常好的效果的。
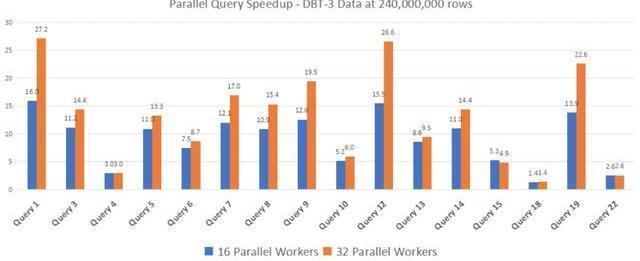
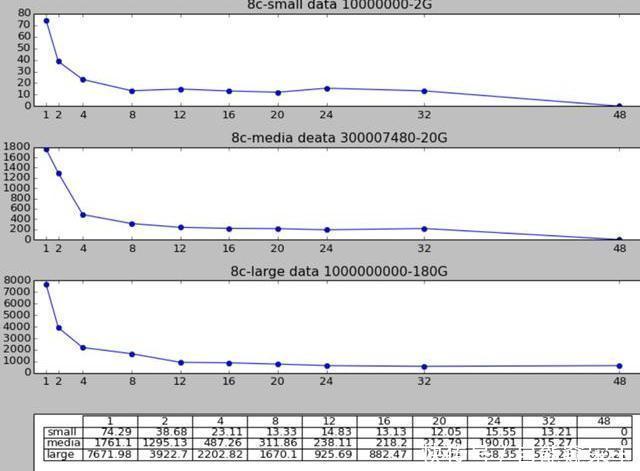
Online DDL分为创建临时表扫描拷贝全量数据加上增量应用期间的变更等几个主要阶段。以增加索引为例需要扫描主键所有记录,生成新的二级索引记录,写入磁盘文件中;对所有二级索引记录进行排序,写入磁盘文件;将有序的二级索引记录插入到新的二级索引中。
POLARDB可以对索引树进行并行扫描、并行多路归并的Merge Sort、并行的Bulk Load索引。 在8core32G规格的实例中针对CPU Bound 和 IO Bound的场景分别进行了测试,都可以达到6-13倍的速度提升。
文章插图
总结
今年的双十一对PolarDB在性能和功能上提出了更高的要求。 PolarDB在并发性能、跨域、弹性以及可用性上都更进了一步,POLARDB不仅承载着整个阿里集团的实时OLTP数据业务,而且在云上为更为广大的客户提供服务。 我们的目标是将云原生的数据库技术普惠所有的企业客户,帮助客户更好的实现业务价值。
本文为阿里云原创内容,未经允许不得转载。
- 页面|流程图怎样画?老板要我帮他做个组织结构图
- IPO|三旺通信IPO:产品结构相对单一业务规模较小 研发人员占员工总数33%
- 破解|“阿尔法狗”亲兄弟AlphaFold破解预测蛋白质结构50年难题
- 肇观|肇观电子视觉芯片每秒最快可计算181帧(张)视频/图片
- 数据结构与算法系列 - 深度优先和广度优先
- 你不知道的Redis:入门?数据结构?常用指令?
- 二叉状态树的结构,Part-1
- Mysql不止CRUD,聊聊索引
- 图解3种常见的深度学习网络结构:FC、CNN、RNN
- 二极管|6G技术再突破!在110米的距离实现:115GB每秒的数据传输!