索引结构|每秒14亿次PolarDB如何应对双11“尖峰时刻”
2020年是云原生数据库PolarDB全面支撑天猫双十一的第二年,天猫交易、买家、卖家以及物流等系统在双十一期间基于PolarDB为亿万客户提供了顺滑的体验。同时,PolarDB还刷新了去年由自己创造的数据库处理峰值(TPS)纪录,今年TPS峰值高达1.4亿次/秒,较去年提升了60%。
PolarDB是阿里自研的云原生数据库品牌, 通过独有的存储计算分离、分布式共享存储技术,解决了传统RDBMS容量有限、扩缩容时间长等问题, 在性能、容量、弹性、以及可用性上都有很大的突破:
PolarDB今年下半年发布了MySQL 5.7的兼容版。
至此PolarDB成为全球唯一一家兼容 MySQL 所有在役版本的云数据库,可以覆盖更多的业务场景
性能优化
性能对于双十一大促来说是永恒的主题。
在天猫的核心交易链路的数据库,在零点峰值场景中,会有大量的数据读写。
而每一年随着峰值的增长,数据库会遇到更严峻的挑战。
在过去的几年中,随着数据库硬件的不断进化,我们为PolarDB重点优化了索引结构、I/O子系统、锁系统以及事务系统来完成并发性能的提升。
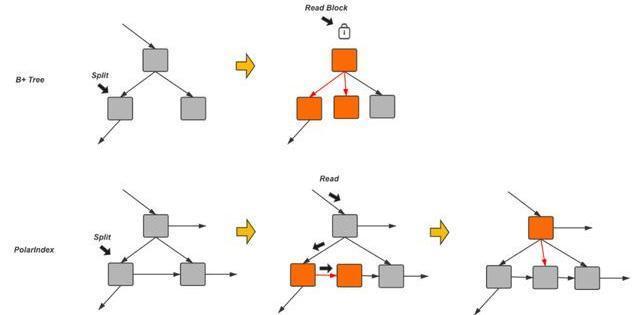
首先是索引结构。众所周知传统的InnoDB 索引在这样的场景下会遇到频繁的页面分裂导致的并发瓶颈。
所有的对索引结构的修改都要排队串行执行。为了解决这个问题, PolarDB引入了新的索引结构来替代传统索引,细化索引结构变更时的并发粒度,提升了接近20%的读写性能。新的索引结构使得原本需要将所有涉及索引分裂的页面加锁直到整个分裂动作完成后才释放的逻辑变成逐层加锁。这样原本被索引页面分裂阻塞的读操作会有机会在整个分裂动作中间进来:通过对每个节点增加一个后继链接的方式,使得在分裂的中间状态也可以完成对数据页面的安全的访问,从而提高读取性能。
文章插图
其次是IO子系统。
由于PolarDB是采用的用户态文件系统, 因此需要有一套对应的IO系统来确保对底层分布式存储的高效访问, InnoDB原有的AIO策略,是将所有异步IO请求按照目标地址进行组织存放在同一个IO数组中,方便将目标地址连续的小IO合并成大IO以提升IO的吞吐,但是在分布式存储的场景下连续的大IO操作,会使得同一时刻,只有一个或少量存储节点处在服务状态,其他的存储节点处于空闲状态,此外,分布式存储在高IO负载的场景中会出现网络中的Inflight IO较多的情况,IO任务数组中添加I和移除请求的开销都很大。为此PolarDB专门对IO系统进行了重新的设计,主要包括:合理的选择IO合并和拆解,充分利分布式存储的多节点优势;建立状态有序的IO服务队列,减少高负载下的IO服务开销。新的子系统让PolarDB在写入和读写混合的场景下性能和稳定性都得到了显著的性能提升。

文章插图
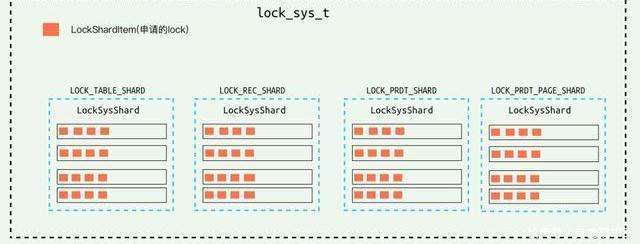
再接下来是锁系统的优化。 PolarDB和MySQL一样都是采用MVCC的方式看来做事务之间的并发控制, 但是在处理写请求和写请求之间的并发时是通过两阶段的锁来做保护的。大量且频繁的插入更新删除带来了锁系统的负担和并发的瓶颈。 因此PolarDB采取了Partition Lock System的方式,将锁系统改造成由多个分片组成,每个分片中都有自己局部的并发控制,从而将这个瓶颈打散。尤其是在这种大压力的写入场景下明显的提升写入性能。
文章插图
最后是事务系统。
PolarDB中支持Snapshot Isolation的隔离级别,通过保留使用的Undo版本信息来支持对不同版本的记录的访问,即MVCC。
而实现MVCC需要事务系统有能力跟踪当前活跃及已经提交的事务信息。在之前的实现中每当有写事务开始时,需要分配一个事务ID,并将这个ID添加到事务系统中的一个活跃事务列表中。当有读请求需要访问数据时,会首先分配一个ReadView,其中包括当前已分配最大的事务ID,以及当前这个活跃事务列表的一个备份。每当读请求访问数据时,会通过从索引开始的指针访问到这个记录所有的历史版本,通过对比某个历史版本的事务ID和自己ReadView中的活跃事务列表,可以判断是不是需要的版本。然而,这就导致每当有读事务开始时,都需要在整个拷贝过程对这个活跃事务列表加锁,从而阻塞了新的写事务将自己的ID加入。
同样写事务和写事务之间也有访问活跃事务列表的冲突。从而活跃事务列表在这里变成一个明显的性能瓶颈,在双十一这种大压力的读写场景下尤为明显。
- 页面|流程图怎样画?老板要我帮他做个组织结构图
- IPO|三旺通信IPO:产品结构相对单一业务规模较小 研发人员占员工总数33%
- 破解|“阿尔法狗”亲兄弟AlphaFold破解预测蛋白质结构50年难题
- 肇观|肇观电子视觉芯片每秒最快可计算181帧(张)视频/图片
- 数据结构与算法系列 - 深度优先和广度优先
- 你不知道的Redis:入门?数据结构?常用指令?
- 二叉状态树的结构,Part-1
- Mysql不止CRUD,聊聊索引
- 图解3种常见的深度学习网络结构:FC、CNN、RNN
- 二极管|6G技术再突破!在110米的距离实现:115GB每秒的数据传输!