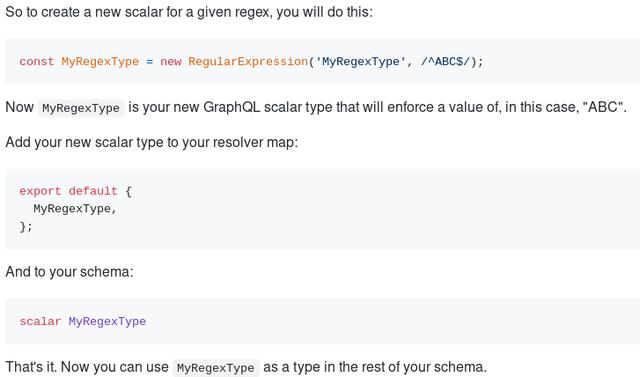
怎样设计安全的GraphQL API?( 二 )
当实现自定义标量时 , 考虑使用旨在定义通用自定义标量的开源库并进行贡献 。 这能帮助每个团队减少开发他们自己的校验逻辑所需的时间和精力 , 还可以帮助每个人避免重复相同错误 。 下面是两个现有的致力于创建共享自定义标量库的项目:
- Urigo
- Saeris
 文章插图
文章插图避免自定义标量封装其它类型(JSON/XML)避免创建复杂类型的自定义标量 , 例如 JSON(例如graphql-type-json) 。
复杂的自定义标量会妨碍嵌套类型的正确校验 , 还可能引入漏洞 , 例如 GraphQL 查询注入或 NoSQL 注入 。 对于这些风险 , 我们会在下一节进行详细讨论 。
其它转换和缓存问题大部分 GraphQL 实现是引入到现有的 REST 生态系统的 。
在本节 , 我们将检查你在转换过程中可能遇到的风险 。 GraphQL 和 REST 之间的转换过程 , 结合缓存 , 它会导致各种不可预知的漏洞 。
REST 和 GraphQL 之间转换时避免输入校验问题REST 转 GraphQL假设我们引入了一个新的 GraphQL 后端服务来支持对一个现有的 REST API 网关的数据检索 。 为了查询 GraphQL 服务 , 我们的开发者可能会尝试将传入的查询参数插入到一个后端 GraphQL 请求中:
userUpdateQuery = `mutation {updateUser(firstName: "${request['firstname']}",lastName: "${request['lastname']}",) {User {firstNamelastName}}}`;传统的 REST API 可能是弱类型的(GET/POST 参数)或者强类型的(JSON/XML) , 这使得转换成一个强类型 API 容易出错 。 例如 , 当尝试这样转换时 , 有很多机会向查询中注入额外的 JSON 语句 。为减少这些风险 , 可以考虑使用持久化查询 。 持久化查询允许你将一个哈希值对应于一个存储的服务器端查询及其输入变量 。 这将安全插值委托给库 , 限制了构建请求时的查询注入机会 。
GraphQL 转 REST作为我们迁移策略的一部分 , 假设我们在现有的 REST API 前面放一个 GraphQL 服务 。
那么 , 针对我们的 GraphQL API 的服务器端解析函数可能会使用用户提供的如下文件名参数来执行访问某个内部 REST API 的内部 GET 请求:
let myFile = await axios.get(`${args.filename}`);通过提交一个路径遍历负载作为参数 , 攻击者能控制外部的 API 请求来执行恶意行为(例如 , ../user/setRoles?roles=[admin,user]) 。 这只是会导致 SSRF 的不安全查询构建的一个例子;任何时候 , 外部请求中的用户输入都是有风险的 。这种转换可能更有挑战性 , 因为用户输入需要被清理两次:在 GraphQL 前端 , 对用于外部请求的查询构建中使用的数据进行额外清理 , 然后在 REST 后台服务中再次清理 。
确保所有查询参数都针对它们将放入的请求上下文进行了清理(例如 , 路径参数的 URI 语法和 JSON 信息的 JSON 语法) 。 尽可能依赖标准库 。
在引入中间缓存时避免破坏授权一些 GraphQL 实现会去除现有后端 REST 基础设施的所有授权 。 这在为现有 REST API 创建一个 GraphQL 网关时特别常见 。 然而 , 由于这会导致额外的延迟 , 所以常见的是在 GraphQL 服务器和 REST API 服务器之间引入中间缓存 。 然而 , 与转换带来的风险类似 , 这种方案也会导致问题 。
如果授权过的响应保存在缓存中 , 未经授权的请求可能会不恰当地获取到缓存的内容 , 而无需到后端 REST 服务器进行授权检查 。 由于授权逻辑位于中间缓存层后面 , GraphQL 服务器需要处理缓存检索逻辑来确保不会违反后端访问控制 。
安全测试用例既然我们已经对迁移过程中可能遇到的问题和犯的错误有了一个很好的理解 , 那么 , 我们可以定义一个测试用例列表:
- introspection 在生产环境被禁用了吗?
- 速率限制:
? 2. 有查询深度限制吗?
? 3. 有响应限制(例如 , 能否分页)吗? ?
4. 有查询复杂度限制吗?
- 授权:
? 2. 所有数据的访问路径都保持相同的访问控制吗?
? 3. 对于只有部分角色才能访问的字段 , 这些访问控制是强制的吗? ?
4. 不同的错误响应是否泄露了字段或节点的存在? ?
5. 源代码:授权检查是否依赖单一信源(例如 , 用户的 session);代码对非白名单字段是否有回退拒绝规则?
? 6. 输入校验:API 是否执行强输入校验(例如 , 有限制的整数值或者名称的有限字符集);API 是否正确处理了 null 值;当向输入中注入常见的 SQL(例如 , [‘]、[--]或[#])或 GraphQL(例如 , JSON)语句时 , 服务器端是否会报错?
- V2X|V2X:确保未来道路交通数据交换的安全性
- 余额|中兴通讯:现有资金余额仅能确保公司当前经营规模下现金流安全
- 页面|流程图怎样画?老板要我帮他做个组织结构图
- 摄像头|摄像头造型别出心裁 realme全新手机设计专利曝光
- 基建|深信服何朝曦:离开安全的“新基建”,就是在沙子上盖高楼
- 简单|密码太难记不住,太简单不安全,怎么办?
- 设计师|苹果设计师主刀,OriginOS欲掀起“ 拟态化”设计风
- 设计语言|全新家族设计,三星Galaxy A32渲染图曝光
- 副局长|杨林副局长在美团总部调研网络食品安全监管工作
- 这场|这场顶级盛会,15位全球设计行业组织主席@烟台:中国创新经验从这里影响世界