监控平台选Prometheus还是Zabbix?( 三 )
不止于此 , 还要继续为这 10000 个监控项配置触发器和告警规则 。
而在 Zabbix 中 , 我们只需创建一个模版 , 定义低级别发现的规则 , 并将这个模版同这 100 台需要监控的服务器关联即可 。
Zabbix 会根据服务器上实际的磁盘数量自动生成对应的监控项 , 大大提升了添加监控的效率 , 同时也减少了手动添加监控的纰漏 。
自动发现:它能帮助我们快速发现网络内的设备 , 并按规则识别出它的类型 , 将其和指定的模版进行关联 。
全栈级监控:就像刚才所介绍的 , Zabbix 在监控的广度和深度之间做了一个比较好的权衡 , 它是一个全栈级的监控平台 。
从底层的硬件、操作系统、中间件、数据库 , 到上层的应用、业务 , 都可以纳入到 Zabbix 的监控范围中 。
实现了通过一个统一的监控平台 , 覆盖所有监控对象不同层次监控的需求 , 同时降低了维护多套监控平台的成本和所需要的知识积累 , 方便上手 。
可定制 , 与 DevOps 流水线集成:Zabbix 本身也是一个开放的系统 。 提供了丰富的 API , 这些 API 几乎可以实现界面上所有的功能 , 可以同企业内部的 DevOps 持续交付流水线进行集成 , 提升整体自动化的水平 。
Zabbix 全栈自动化监控实践案例
接下来 , 我们来讨论下 Zabbix 这些高级特性在实际使用场景中的最佳实践案例 。
分布式自动化监控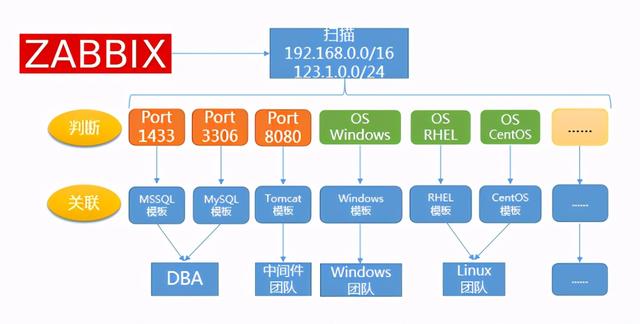 文章插图
文章插图
首先来看下我们是如何通过自动发现特性实现监控的自动添加的:
我们会在 Zabbix 中配置自动发现规则 , 比如我们对制定的网段进行扫描 。 当我们发现网段中某个 IP 的 1433 端口是打开的 , 我们基本上可以推断它上面运行着微软的 SQLServer 服务 。
因此 , 我们通过已经配置好的规则 , 将发现的这个开放着 1433 端口的 IP 和 SQLServer 模版进行关联 。
SQLServer 的模版是我们预先定制好的对于微软数据库的监控模版 , 通过自动发现 , 我们能达到两个目的:
- 所有的微软数据库都被监控到了 。
- 所有被监控的数据库使用了同一套监控基线 , 实现了标准化监控 。
除了关联模版 , 我们会把监控对象添加到不同的组中 , 确保每个组关联了对应的运维人员 。
这样做的好处在于 , 我们不需要频繁的更新告警策略 , 而当故障发生的时候 , 对应的管理员也能第一时间收到告警 。
双维度管理(平台维度/业务维度)
 文章插图
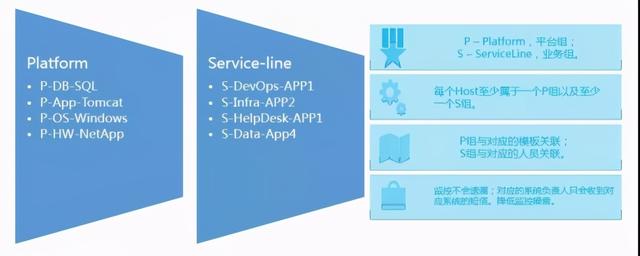
文章插图刚才提到了组的概念 , 我们在实际应用中 , 一个监控对象属于两个组 , 即一个 P 组(平台组)和一个 S 组(业务组) 。
IT 运维人员的视角和业务人员的视角存在差异性 , 通常一个组织内会雇佣不同角色的 IT 专业人员 , 比如 Windows 管理员 , Linux 管理员 , DBA 等 。
DBA 会负责所有数据库相关的运维工作 , 而且不在乎这个数据库属于那个应用系统 。
因此所有的数据库服务器 , 比如所有的 MySQL , 都会放到一个叫做 P-DB-MySQL 的组中 。
这个组所有的告警会发送给指定的 DBA 而不是 Windows 管理员 , 同时会和对应的 MySQL 监控模版进行关联 。
这样做的收益在于 DBA 只会收到他们所负责系统的告警 , 同时监控也实现了标准化 。
而业务人员关注的是整体业务应用是否正常运行 。 比如一个登陆系统 , 它可能有前端的 Tomcat 中间件 , 还有一台 MySQL 存放着用户登录信息 , 底层跑着一台 HP 的服务器 。
那么我们会把这三个监控对象放在一个叫做 S-Department1-Login 的组中 。
这样做的好处在于 , 一旦一个监控对象出现任何问题 , 我们可以第一时间知道它影响什么系统 。
通过 P 组和 S 组的结合 , 我们可以在监控告警不被遗漏的同时 , 最大限度降低监控噪音 , 同时也能直观知晓当前的问题会对那些业务造成影响 。
告警方式
 文章插图
文章插图Zabbix 支持非常多的告警方式 , 这点类似于 Prometheus 的 AlertManager 。
首先我们会对报警进行分级 , Zabbix 原生提供了 5 种级别的告警 , 即 Disaster , High , Warning , Average 和 Info 。
我们使用了其中的三种 , 并给出了这三种级别告警的定义:
- Disaster:触发后需要立即处理 , 如不处理会直接影响生产系统的告警 。
- 产业|前瞻生鲜电商产业全球周报第67期:发力社区团购!京东内部筹划“京东优选”
- 王兴称美团优选目前重点是建设核心能力;苏宁旗下云网万店融资60亿元;阿里小米拟增资居然之家|8点1氪 | 美团
- 信息|澜湄合作机制开通水资源合作信息共享平台
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 研发|闽企制伞有“功夫”项目入选国家重点研发计划
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 发展|我省要求互联网平台坚持依法合规经营 推动线上经济健康规范发展
- 平台|Win平台上的本地音乐管理软件,MusicBee
- 报名啦!宿迁开展第五届“十大科技之星”评选
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?