教你用python轻松解析XML和PDF,一文够了,赶紧码住( 二 )
输出结果: 文章插图
文章插图
ElementTree 方式解析Python 提供了两种 ElementTree 的实现方式 。
- 纯 Python 实现的 xml.etree.ElementTree
- C 语言实现 xml.etree.cElementTree , 使用 C 语言实现的方式速度更快且内存消耗更少 。
import xml.etree.ElementTree as ETtree = ET.parse("test.xml")# 根节点root = tree.getroot()# 标签名print('root_tag:',root.tag)for stu in root:# 属性值print ("stu_name:", stu.attrib["name"])# 标签中内容print ("id:", stu[0].text)print ("name:", stu[1].text)print("age:", stu[2].text)print("gender:", stu[3].text)输出结果: 文章插图
文章插图Python 解析 PDF用 Python 如何解析 PDF, 从它的表现来看 , 它更像是一张图片 , 在一张白纸上把内容摆放在固定的位置上 , 没有逻辑结构 。
正是因为 PDF 没有统一的规范 , 也没有逻辑结构 , 比如句子或段落 , 并且不能自适应页面大小的调整 。 今天要介绍的 PDFMiner 尝试通过猜测它们的布局来重建它们的结构 , 但是并不能保证一定能识别成功 , 尤其是对图片和表格的识别处理会差一些 。
安装 PDFMiner解析 PDF 需要用到 pdfminer 库 , 目前最新版本只支持 Python3.6 及以上, 执行如下安装命令:
C:\Users\Y>pip install pdfminerLooking in indexes: Collecting pdfminerDownloading(4.2MB)|████████████████████████████████| 4.2MB 930kB/sCollecting pycryptodome (from pdfminer)Downloading(14.1MB)|████████████████████████████████| 14.1MB 3.3MB/sBuilding wheels for collected packages: pdfminerBuilding wheel for pdfminer (setup.py) ... doneCreated wheel for pdfminer: filename=pdfminer-20191125-cp37-none-any.whl size=6140080 sha256=9a1c9db96fae1c4231b2272f6edce3e8ebf92645bdb0a318e0952d751b3d70bfStored in directory: C:\Users\Y\AppData\Local\pip\Cache\wheels\95\e4\2f\493db6cf7b26fd7b962c543b0560cbc13d42193890a39a1c65Successfully built pdfminerInstalling collected packages: pycryptodome, pdfminerSuccessfully installed pdfminer-20191125 pycryptodome-3.9.8OK , 如果提示以上信息则安装成功 。解析概述由于PDF文件有如此大和复杂的结构 , 完整解析 PDF 文件很费时费力的 。 因此 PDFMiner 采用了一个懒惰分析的策略 , 就是只分析你所需要的部分 。 换句话就是说 , 根据你自己的需要只解释出你要的那部分就可以了 。 这里有两个核心类是必须的 PDFParser 和 PDFDocument , 除了这两个模块还有以下几个模块来配合使用 。
模块名说明PDFParser从文件中获取数据PDFDocument存储文档数据结构到内存中PDFPageInterpreter解析page内容PDFDevice把解析到的内容转化为你需要的东西PDFResourceManager存储共享资源 , 例如字体或图片等
下面这个图表示了 PDFMiner 各模块之间的关系:
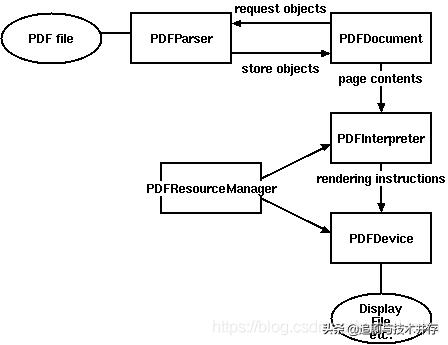 文章插图
文章插图基本用法首先我准备了一个 pdf 格式的文档 , 内容基本如下图这样:
 文章插图
文章插图下面这段代码给出了 PDFMiner 解析 PDF 文档的基本方法:
- 打开 pdf 文件 , 创建解析对象 , 存储文档结构 , 创建资源管理对象以及共享资源
- 再创建 device 对象
- 再创建文档解析对象 , 并处理文档中的每一页
# 导入库from pdfminer.pdfparser import PDFParserfrom pdfminer.pdfdocument import PDFDocumentfrom pdfminer.pdfpage import PDFPagefrom pdfminer.pdfpage import PDFTextExtractionNotAllowedfrom pdfminer.pdfinterp import PDFResourceManagerfrom pdfminer.pdfinterp import PDFPageInterpreterfrom pdfminer.pdfdevice import PDFDevicefrom pdfminer.layout import LAParamsfrom pdfminer.converter import PDFPageAggregator# 设置文档密码password = ''#打开pdf文件fp = open('pdf_test.pdf','rb')#从文件句柄创建一个pdf解析对象parser = PDFParser(fp)#创建pdf文档对象 , 存储文档结构document = PDFDocument(parser,password)#创建一个pdf资源管理对象 , 存储共享资源rsrcmgr = PDFResourceManager()#创建一个device对象device = PDFDevice(rsrcmgr)#创建一个解释对象interpreter = PDFPageInterpreter(rsrcmgr, device)#处理包含在文档中的每一页for page in PDFPage.create_pages(document):interpreter.process_page(page)
- 世代|Z星球——腾讯布局Z世代教育社交的新尝试
- 缩小|调整电脑屏幕文本文字显示大小,系统设置放大缩小DPI图文教程
- 路由器|家里无线网经常断网、网速慢怎么办?教你几个小窍门,轻松解决
- 教学|机器人教学的目标方案
- 走心|平安夜还在送苹果?太不走心了,教你几招,快来物色一个
- 势不可挡|清华教授刘瑜:我的女儿正势不可挡地成为一个普通人
- 云图|不会制作词云图?我来教你
- 品牌|回忆杀!夏普索爱摩托罗拉,这几个经典手机品牌你用过哪一个
- 入门|做抖音影视赚钱比工资多,教大家新手也可快速入门
- 契机|抓住人工智能助推教师发展的新契机