玩转MySQL:深入解析InnoDB引擎存储结构+特性分析
推荐学习
- 10.24程序员节 , 喜得一套「MySQL性能优化金字塔法则」
- 阿里P8MySQL , 基础/索引/锁/日志/调优都不误 , 一锅深扒端给你
 文章插图
文章插图前言今天就让我们深入InnoDB的存储结构看看这些文件或缓存到底是如何存储及工作的 。
本文基于MySQL5.7版本 。
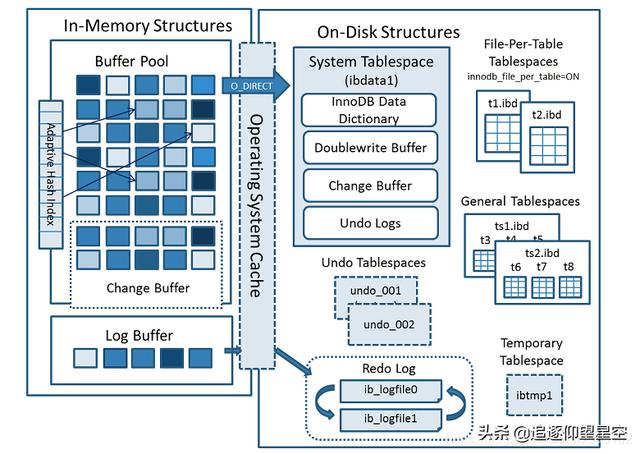
InnoDB总体结构首先我们来看官网的一张图(图片来源于MySQL官网):
 文章插图
文章插图从上图中可以看出其主要分为两部分结构 , 一部分为内存中的结构(上图左边) , 一部分为磁盘中的结构(上图右边)
内存结构InnoDB内存中的结构主要分为:Buffer Pool,Change Buffer和Log Buffer三部分 。
Buffer PoolBuffer Pool是InnoDB缓存表和索引的一块主内存区域 , Buffer Pool允许直接从内存中处理经常使用的数据 , 从而加快处理速度 , 带来一定的性能提升 。 但是缓存总有放满的时候 , 当缓存满了新来的数据怎么处理呢?Bufer Pool中采用的是LRU(least recently used , 最近最少使用)算法 , LRU列表中最前面存的是高频使用页 , 尾部放的是最少使用的页 。 当有新数据过来而缓存满了就会覆盖尾部数据 。
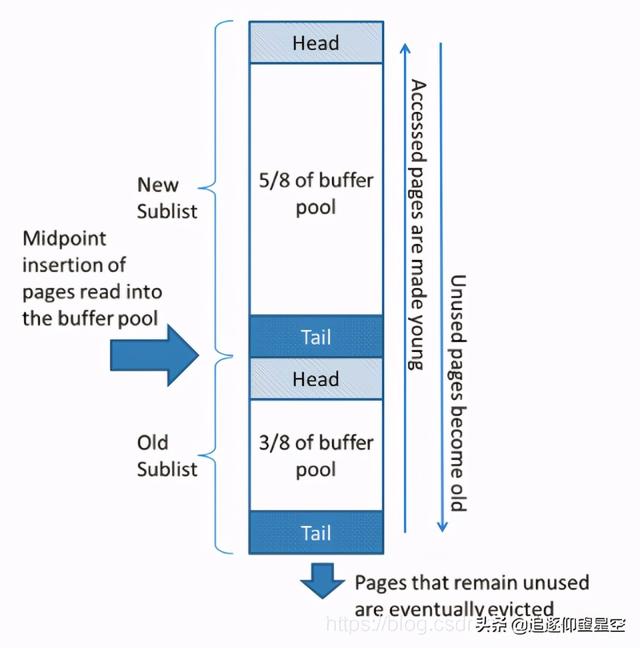
假如我们有一条查询语句非常大 , 返回的结果集直接就超过了Buffer Pool的大小 , 而这种语句使用场景又是极少的 , 可能查询这一次之后很久不会查询 , 而这一次就将缓存占满了 , 将一些热点数据全部覆盖了 。 为了避免这种情况发生 , InnoDB对传统的LRU算法又做了改进 , 将LRU列表分拆分为2个 , 如下图(图片来源于MySQL官网):
 文章插图
文章插图该算法在new子列表中保留大量页面(5/8),old子列表包含较少使用的页面(3/8);old子列表中数据可能会被覆盖 , 该算法具体操作如下:
- 3/8的Buffer Pool空间用于old子列表
- 列表的中点是new子列表的尾部与old子列表的头部之间的边界
- 当InnoDB将一个页面读入缓冲池时 , 它首先将它插入到中间点(old子列表的头) 。 读取的页面是由用户发起的操作(比如SQL查询)或InnoDB自动执行的预读操作
- 访问old子列表中的页面使其“young” , 并将其移动到new子列表的头部 。 如果读取的页是由用户发起的操作 , 那么就会立即进行第一次访问 , 并使页面处于young状态;如果读取的页是由预读发起的操作 , 那么第一次访问不会立即发生 , 而且可能直到覆盖都不会发生 。
- 操作数据时 , Buffer Pool中未被访问的页会逐渐移到尾部 , 最终会被覆盖 。
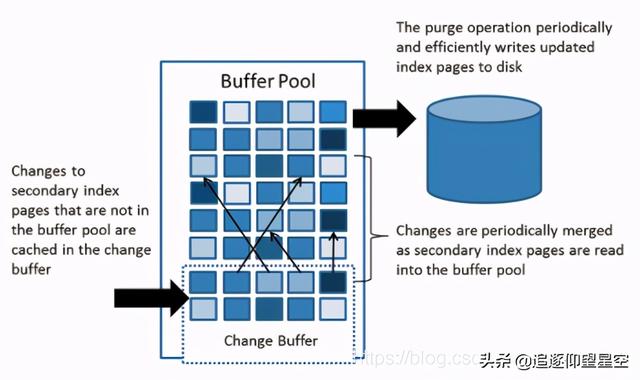
Change BufferChange Buffer是一种特殊的缓存结构 , 用来缓存不在Buffer Pool中的辅助索引页 ,支持insert, update,delete(DML)操作的缓存(注意 , 这个在MySQL5.5之前叫做Insert Buffer , 仅支持insert操作的缓存) 。 当这些数据页被其他查询加载到Buffer Pool后 , 则会将数据进行merge到索引数据叶中 。
 文章插图
文章插图InnoDB在进行DML操作非聚集非唯一索引时 , 会先判断要操作的数据页是不是在Buffer Pool中 , 如果不在就会先放到Change Buffer进行操作 , 然后再以一定的频率将数据和辅助索引数据页进行merge 。 这时候通常都能将多个操作合并到一次操作 , 减少了IO操作 , 尤其是辅助索引的操作大部分都是IO操作 , 可以大大提高DML性能 。
如果Change Buffer中存储了大量的数据 , 那么可能merge操作会需要消耗大量时间 。
为什么Change Buffer只能针对非聚集非唯一索引因为如果是主键索引或者唯一索引 , 需要判断数据是否唯一 , 这时候就需要去索引页中加载数据判断而不能仅仅只操作缓存 。
Change Buffer什么时候会merge总体来说 , Change Buffer的merge操作发生在以下三种情况:
- 辅助索引页被读取到Buffer Pool时 。 当执行一条select语句时 , 会去检查当前数据页是否在Change Buffer中 , 如果在 , 就会把数据merge到索引页
- 该辅助索引页没有可用空间时 。 InnoDB内部会检测辅助索引页是否还有可用空间(至少有1/32页) , 如果检测到当前操作之后 , 当前索引页剩余空间不足1/32时 , 会进行一次强制merge操作
- 后台线程Master Thread定时merge 。 Master Thread是一个非常核心的后台线程 , 主要负责将缓冲池中的数据异步刷新到磁盘 , 保证数据的一致性 。
- 启动|拼多多深入布局母婴产业带 补贴+直播启动“母婴产品溯源”行动
- 《深入理解Java虚拟机》:对象创建、布局和访问全过程
- pymysql 连接 MySQL 实现简单登录
- mysql 8.0.21 安装配置方法图文教程
- SpringBoot+MyBatis+MySQL读写分离实现
- Mysql不止CRUD,聊聊索引
- 深入理解Netty编解码、粘包拆包、心跳机制
- 详解mysql执行计划
- 什么是MySQL的执行计划(Explain关键字)?
- 《深入理解Java虚拟机》:锁优化