神经网络简史
介绍现在神经网络无处不在 。 各大公司都在硬件和人才上大肆挥霍 , 以确保他们能够构建最复杂的神经网络 , 并推出最好的深度学习解决方案 。
虽然深度学习是机器学习的一个相当古老的子集 , 但直到20世纪10年代初 , 它才得到应有的认可 。 今天 , 它已经风靡全球 , 吸引了公众的注意 。
在本文中 , 我想对神经网络采取一种稍微不同的方法 , 并了解它们是如何形成的 。 文章插图
文章插图
神经网络的起源神经网络领域最早的报道始于20世纪40年代 , 沃伦·麦卡洛克和沃尔特·皮茨尝试用电路建立一个简单的神经网络 。
下图显示了一个MCP神经元 。 如果你学的是高中物理 , 你会发现这看起来很像一个简单的NOR门 。
l论文展示了借助信号的基本思想 , 以及如何通过转换所提供的输入做出决策 。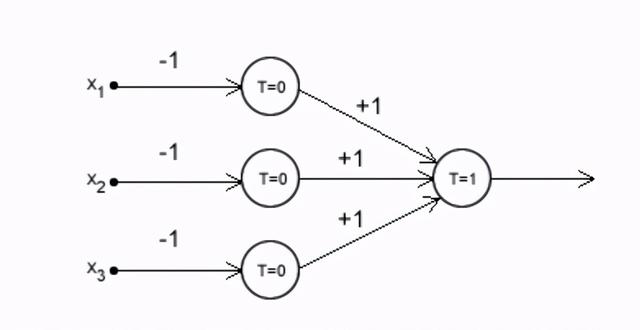 文章插图
文章插图
McCulloch和Pitts的论文提供了一种用抽象的术语描述大脑功能的方法 , 并表明神经网络中连接的简单元素可以具有巨大的计算能力 。
尽管它具有开创性的意义 , 但这篇论文几乎没有引起人们的注意 , 直到大约6年后 , 唐纳德·赫伯(下图)发表了一篇论文 , 强调了神经通路每次被使用时都会加强 。 文章插图
文章插图
请记住 , 那时计算机还处于初级阶段 , IBM在1981年推出了第一台PC(IBM5150) 。 文章插图
文章插图
快进到90年代 , 许多关于人工神经网络的研究已经发表 。 罗森布拉特在20世纪50年代发明了第一台感知器 , 1989年Yann LeCun在贝尔实验室成功地实现了反向传播算法 。 到了20世纪90年代 , 美国邮政局已经可以读取信封上的邮政编码 。
我们今天所知的LSTM是在1997年发明的 。
如果90年代已经打下了这么多基础 , 为什么要等到2012年才能利用神经网络完成深度学习任务?
硬件与互联网的兴起深度学习研究遇到的一个主要挑战是缺乏可重复的研究 。 到目前为止 , 这些进展都是理论驱动的 , 因为可靠数据的可用性很低 , 硬件资源有限 。
在过去的二十年里 , 硬件和互联网领域取得了长足的进步 。 在20世纪90年代 , IBM个人电脑的RAM为16KB 。 在2010年 , 个人电脑的平均内存在4GB左右!
现在 , 我们可以在我们的电脑上训练一个小型模型 , 这在90年代是无法想象的 。
游戏市场在这场革命中也扮演了重要角色 , 像NVIDIA和AMD这样的公司在超级计算机上投入巨资 , 以提供高端虚拟体验 。
随着互联网的发展 , 为机器学习任务创建和分发数据集变得容易得多 。
从Wikipedia中学习和收集图片变得更容易 。
2010年:我们的深度学习时代ImageNet:2009年 , 现代深度学习时代的开始 , 斯坦福大学的李飞飞创建了ImageNet , 这是一个大型的可视化数据集 , 被誉为是在世界范围内催生人工智能革命的项目 。
早在2006年 , 李是伊利诺伊大学香槟分校的新教授 。 她的同事们会不断地讨论新的算法来做出更好的决策 。 然而 , 她看到了他们计划中的缺陷 。
如果在反映真实世界的数据集上训练 , 那么最好的算法也不会运行得很好 。 ImageNet由超过2万个类别的1400万张图像组成 , 到目前为止 , 仍然是物体识别技术的基石 。
公开竞争:2009年 , Netflix举办了一个名为Netflix Prize的公开竞赛 , 以预测电影的用户收视率 。 2009年9月21日 , BellKor的务实混沌团队以10.06%的优势击败了Netflix自己的算法 , 获得了100万美元的奖金 。
Kaggle成立于2010年 , 是一个面向全球所有人举办机器学习竞赛的平台 。 它使研究人员、工程师和本土的程序员能够在解决复杂的数据任务时突破极限 。
在人工智能繁荣之前 , 人工智能的投资约为2000万美元 。 到2014年 , 这项投资增长了20倍 , 谷歌、Facebook和亚马逊等市场领导者拨出资金 , 进一步研究未来的人工智能产品 。 这一波新的投资浪潮使得深度学习领域的招聘人数从几百人增加到数万人 。
结尾尽管起步缓慢 , 但深度学习已经成为我们生活中不可避免的一部分 。 从Netflix和YouTube推荐到语言翻译引擎 , 从面部识别和医学诊断到自动驾驶汽车 , 没有一个领域是深度学习没有触及的 。
这些进展拓宽了神经网络在改善我们生活质量方面的未来范围和应用 。
- 介绍|5分钟介绍各种类型的人工智能技术
- 用于|用于半监督学习的图随机神经网络
- 能力|美国研发快速法评估神经网络的不确定性 改进自动驾驶车决策能力
- 平台好友|《妄想山海》好友列表介绍
- 程序员学英语第1天——JavaScript 程序测试的介绍1
- 混沌实施工具ChaosBlade实践
- 吉林大学TARS-GO战队视觉代码
- 媒介|智媒介:软文发布文案的核心写作技巧介绍
- 简单介绍Protobuf协议
- 如何系统地欺骗图像识别神经网络