按关键词阅读: 创投圈
我们都知道 , Facebook全身心all in 元宇宙 , 连“Face”都不要了 , 自家名字都改成了Meta 。 可能也正是为了自己的元宇宙愿景 , Meta发布了自监督语音处理模型XLS-R , 不要小看这个人工智能模型 , 它可是支持高达128种语言 。
这个新的语音模型 , 简直可以说跨越全球人的不同语言障碍了 , 可以让大家各说各的 , 还能互相理解 , 彼此交流起来如同以同一种语言来沟通一样 。 可能说起来 , 类似于一个直译 , 把我说的语音以你的母语的方式转化出来 。 机智客这里表达的意思是 , XLS-R要实现的场景是 , 我说我的汉语 , 你说你的英语 , 可是我们彼此之间都能丝滑秒懂 , 如同我们都在说汉语或者英语 。 这个语音模型 , 神奇吧 。
虽然 , 多语言模型并不罕见 , 彼此翻译也实不鲜见 。 不过 , 据了解 , XLS-R则是基于以前自己也就是以前的Facebook发布的wav2vec 2.0技术 , 通过自监督技术对10倍的语音数据进行训练 , 而大大改善了以前的多语言模型 , 尤其是针对小语种的处理 。
【创投圈|跨所有语言?Meta发布新语音模型,简直能让全球人无障碍交流】可能有朋友知道谷歌发布的BERT模型 , 而wav2vec2.0则和BERT类似 , 不过它们的区别是 , 语音音频是一种连续的信号 , 不能轻易清晰地分割成单词或其他单位 。 机智客看资料显示 , wav2vec 2.0通过学习25毫秒长的基本单元来解决这个问题 , 以便能够学习高级上下文表示 。 通过少量有标记训练数据的情况下 , Meta的技术通过后续无监督的训练数据 , 在LibreSpeech测试基准的100小时子集上达到SOTA水平 。 之后 , 又通过高性能语音识别模型wav2vec-U来从录制的语音音频和未配对的文本中学习 。 其中还用到了GAN技术来学习识别音频录音中的单词 。
也就是有了这一系列的技术实现基础 , Meta这才推出了包含53种语言的XLSR 。 而最新的发布的XLS-R则远超XLSR , 包含高达128种语言 。 它 , 包含20亿参数 。 其表现优于先前的工作 , 哪怕是小语种识别上 。
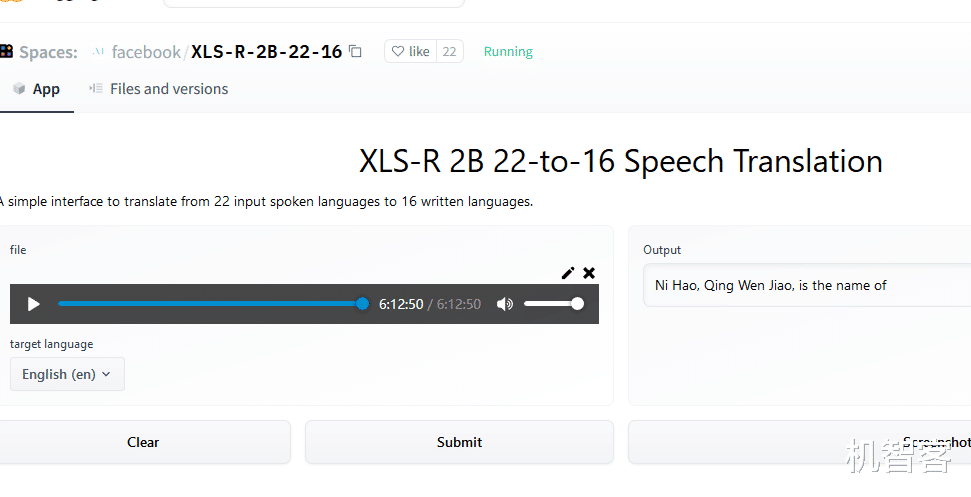
遥想到 , 上帝为了阻止人类造通天塔而变乱人类的语言 , 使之各不相同 , 无法彼此直接沟通 。 现在Meta要“冒天上之大不韪”——把上帝扰乱的东西再捋顺统一过来 , 公然“逆天而行” , 其心壮哉——厉害了我滴哥 。 算了不皮了 , 其实吧 , 当机智客试玩了那个在线Demo , 随便录了一句汉语语音 , Submit后看到Output的结果 , 差点笑出声来 。
![]()
稿源:(未知)
【傻大方】网址:/c/1124a3cH021.html
标题:创投圈|跨所有语言?Meta发布新语音模型,简直能让全球人无障碍交流