一文入门当今最火的3D视觉
一.导论目前深度学习已经在2D计算机视觉领域取得了非凡的成果 , 比如使用一张图像进行目标检测 , 语义分割 , 对视频当中的物体进行目标跟踪等任务都有非常不错的效果 。 传统的3D计算机视觉则是基于纯立体几何来实现的 , 而目前我们使用深度学习在3D计算机视觉当中也可以得到一些不错的效果 , 目前甚至有超越传统依靠立体几何识别准确率的趋势 。 因此咱们现在来介绍一下深度学习在3D计算机视觉当中的应用吧!本博文参考了前几天斯坦福大学最新出的CS231n课程(2020/8/11新出) , 新课增加了3D计算机视觉和视频/动作分类的lecture , 同时丰富了生成对抗网络(GAN)的内容 , 但暂时国内还无人翻译 , 因此小编将其翻译整理成博文的形式供大家参考,如有错误之处 , 请大家见谅 , 同时欢迎大家讨论 。
二.3D计算机视觉训练集以及表示方法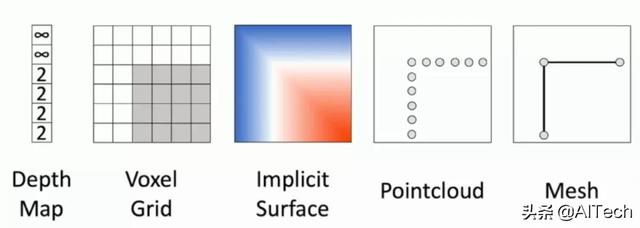 文章插图
文章插图
在3D计算机视觉当中 , 我们可以采用于训练的模型共有以上几种 , 分别是:
1.Depth Map(深度图)
2.Voxel Grid(翻译过来很奇怪 , 因此就保留原英语)
3.Implicit Surface(隐表面)
4.PointCloud(三维点云)
5.Mesh
那么什么是Depth Map(深度图)呢?咱们来看看
三.Depth Map(深度图)深度图的图像如下所示: 文章插图
文章插图
在左上角有一张关于斯坦福大学寝室的图片 , 我们可以将其转化为右上角的深度图 , 其中深度图当中不同的颜色表示了不同物体距离摄像头的距离 , 距离摄像头的距离越大 , 则显示出来的颜色则越红 。 我们假设有一个神经网络 , 我们只需要输入一张图片 , 就可以得到图片当中的所有位置距离摄像头的距离 , 这样是不是很酷呢?那么我们如何使用神经网络对一系列的图片训练成为深度图的形式呢?一些研究人员便立马想到可以使用全卷积神经网络(Fully convolutional Network)来实现这个过程 , 全卷积神经网络(Fully convolutional Network)是我们之前在2D计算机视觉当中所采用的用于图像分割的神经网络 , 之前图像分割得到的是每一个像素点显示的是属于某一个物体类别的概率值 , 而现在我们把同样的神经网络用于深度图当中就可以得到图像当中某一个像素距离摄像头的远近大小 。 这样就可以完美得到咱们的深度图训练模型了 , 我们甚至可以把这个全卷积神经网络替换成U-net以期在一些特定数据集上得到更好的效果 。 模型如下所示: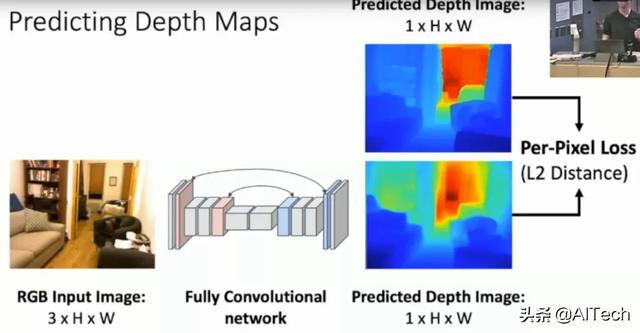 文章插图
文章插图
这个模型首先也是输出一个3通道的彩色图片 , 经过一个全卷积神经网络(FCN)然后对深度图进行估计 , 输出的深度图仅仅具有两个维度 , 因为第三个维度为1 , 意味着我们输出的深度图实际上是黑白的 , 用黑色或者白色的深度来表示距离摄像头的距离 , 图像当中使用了彩色仅仅是因为看起来更加方便 。 同时这里的loss使用了L2距离进行损失函数的编写 。
但是!!!!细心的同学肯定会发现其中有一定的问题 , 那就是同一个物体 , 拥有不同的大小 , 他们如果仅仅通过一张图片来判定他们离摄像头的距离是不一定准确的 。 因为图片当中并没有包含物体有关深度的信息 。
比如我们有两只形状完全相同的鸟 , 但是其中一只鸟是另一只鸟大小的2倍 , 我们把小鸟放到离摄像头更近的位置 , 将大鸟放到离摄像头更远的位置 , 那么仅仅通过一张图片我们就会认为这两只鸟离我们的摄像头距离是一样大的!如下图所示: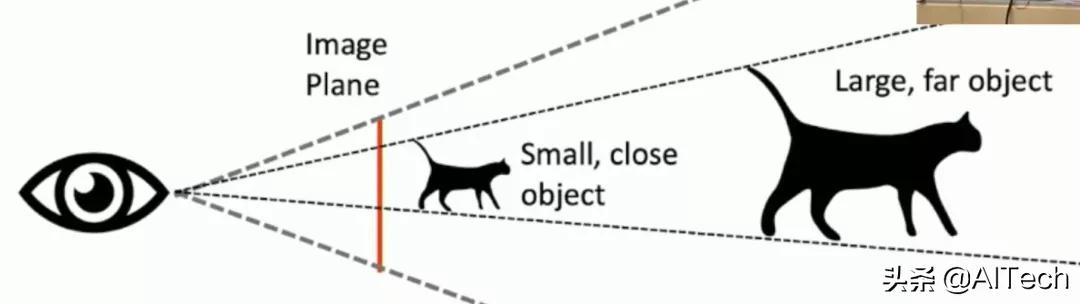 文章插图
文章插图
那么这样我们又该如何解决呢?聪明的研究人员设计了一个具有尺寸不变特征的的loss function来解决了这个问题 , 这个loss function的写法如下: 文章插图
文章插图
至于这个公式为什么会让图片的深度信息得以保留 , 这里不再赘述 , 感兴趣的同学可以翻看一下提出这个loss的论文 , 在2016年的世界顶级人工智能会议论文NIPS上发表 , 于纽约大学(New York University)提出 , 论文的链接如下:
同时呢 , 在深度图当中还有一种图叫做垂直表面法向量图 , 它的图像如下所示: 文章插图
文章插图
最后输出图像当中的不同颜色代表了这个物体的表面所朝空间当中的方向 , 比如绿色代表这个物体的表面是朝向右边的 , 而红色则代表这个物体的表面是朝向左边的 。 我们也可以使用全卷积神经网络(Fully convolutional Network)对这种输出的图像进行处理 , 其中的结构如下所示:
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- UWB|不得不知的汽车连接技术
- 入门|做抖音影视赚钱比工资多,教大家新手也可快速入门
- 制造|智能制造推动产业迈向中高端
- 开发人员|ER(实体关系)建模入门指引
- 零基础小白Python入门必看:通俗易懂,搞定深浅拷贝
- 你不知道的Redis:入门?数据结构?常用指令?
- 入门求稳定,这款真无线耳机做到了:惠威AW-72体验
- 入坑索尼A6100,或许是最好的入门级APS-C相机
- 腾讯数据工程师推荐的Python新手入门书籍,还是首发电子版