从头开始设计分布式缓存
使用Ballet语言实现分布式缓存是我在WSO2的第一个实习项目 。那时我还只是二年级的本科生 , 拥有不错的编程技能 , 但是我不知道什么是分布式计算 , 因此这个项目对我来说是一次独特的经历 。本文试图解释我在分布式系统上获得的曝光以及从头开始设计和实现分布式缓存的过程 。 文章插图
文章插图
> Distributed computing illustration
需求和推理这是一个研究项目 , 旨在向实习生介绍分布式计算的基础知识 , 因为它涵盖了分布式计算的许多概念 。您可以查看"学习成果"部分以获取更多详细信息 。
要求是使用芭蕾舞者语言从头开始实现一个自包含的分布式缓存 。这意味着不允许我使用诸如Zookeeper之类的工具 。Ballerina是WSO2设计的一种新的云原生编程语言 , 可让开发人员更轻松地构建分布式系统 。我相信他们需要测试该语言是否能够构建这样的复杂分布式应用程序 。此外 , 由于芭蕾舞女演员当时没有现有的库 , 因此我也必须学习和实现这些算法 。
当我开始项目时 , 我甚至不知道分布式缓存是什么 。因此 , 我必须对现有系统进行一些研究 , 以了解该域及其用例 。结果 , 我找到了诸如Memcached , Hazelcast IMDG , EHCache之类的解决方案 。然后 , 我对这些平台的功能 , 体系结构和实现进行了深入研究 , 并逐渐帮助我熟悉了该领域 , 并深入了解了分布式缓存的设计和实现 。
问题在研究现有系统时 , 我发现开发人员出于各种原因不愿使用分布式缓存 。
更改群集成员身份后 , 缓存将执行一项昂贵的重定位任务 , 以恢复由成员身份更改导致的可能的数据丢失 。然后 , 当节点重新联机时 , 它将导致另一个数据恢复任务 。如果网络不可靠 , 则可能会反复发生 。这导致拒绝服务 , 最终使整个集群崩溃 。这可能会使数据库超载 , 并显着降低应用程序的性能 。
该设计对每个组件的算法进行评估是该项目中最具挑战性和最有趣的部分 。我必须学习可以在组件中使用的所有相关概念和技术 , 并评估每个组件最合适的概念和技术 。
会员管理
主要的设计决策是确保集群成员的可靠性 。为了达到此要求 , 选择了RAFT共识协议 。RAFT是诸如Kubernetes等流行平台背后的可靠性 。
Raft协议包括以下机制
· 心跳机制可不断监视群集节点的状态 。
· 领导者选举机制 , 用于选择集群的领导者并在给定时间控制集群 。
· 日志复制机制可确保状态机的数据安全 。
故障检测仪
Raft共识由心跳机制组成 , 但是其中不包含适当的故障检测器 。由于问题是由于无法正确检测到故障引起的 , 因此将故障检测器设计为Raft心跳机制的扩展 。
故障检测器的设计考虑了正确性 。群集的领导者保留所有节点的运行状况日志 , 并在运行状况不响应心跳时降低运行状况 。当节点运行状况低时 , 将从高速缓存分发中删除该节点 , 并在将其重新添加到高速缓存之前对其进行一定时间的监视 。
当节点处于监视阶段时 , 群集的负责人将继续通过RPC调用向检测到的节点发送心跳信号 。该监视器还可以用作检测故障的高级断路器 。在添加缓存分配之前 , 将对所有新群集成员和已恢复的节点进行健康检查 。
设计缓存条目分配器时要考虑几个因素 。一致性哈希算法的扩展版本用于此条目分发 。选择"有边界负载一致散列"算法时 , 要考虑以下因素 。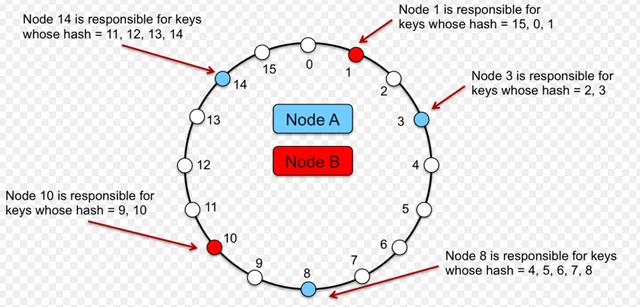 文章插图
文章插图
> Consistent Hashing illustration by vitalflux
【从头开始设计分布式缓存】 1.读写性能
一致性哈希是一种分布式哈希方案 , 通过为服务器或对象分配抽象圆或哈希环上的位置来独立于服务器或对象的数量进行操作 。这允许服务器和对象扩展而不影响整个系统 。
2.复制
条目复制是任何分布式环境中的关键因素 。一致的哈希提供了一种简单的复制机制 , 该机制可以复制数据而无需在同一节点中进行复制 。
3.数据重定位
一致的哈希提供了一种减少添加或删除服务器时需要重新定位的密钥数量的方法 。
4.负载均衡
数据分布的不一致性是一致性哈希的主要缺点之一 。使用"有边界的负载进行一致的散列"算法可以将条目均匀地填充到群集中 , 而不会导致任何节点超载 。
学习成果如博客开头所述 , 我以前没有分布式计算经验 。我了解了CAP定理 , 共识算法 , 成员身份方案和协议 , gRPC等低开销网络协议 , 消息广播策略 , 数据分发算法 , 哈希函数 , 容错 , 混沌工程 , 事件排序和时间 , 数据复制策略 , 云 设计模式和正式定义语言 , 例如TLA + 。
- 摄像头|摄像头造型别出心裁 realme全新手机设计专利曝光
- 设计师|苹果设计师主刀,OriginOS欲掀起“ 拟态化”设计风
- 设计语言|全新家族设计,三星Galaxy A32渲染图曝光
- 这场|这场顶级盛会,15位全球设计行业组织主席@烟台:中国创新经验从这里影响世界
- 建设|日海智能(002313.SZ)中标板障山山地步道项目线路一智慧化建设设计施工总承包项目
- 概念图|华为Mate50Pro概念图:这样的设计才叫豪横,感觉苹果要过气了
- 设计|未来创意拒绝被垄断:欧拉共创成果深度解读!
- 华为|华为P50系列曝光,满溢屏+挖孔设计,花粉还喜欢吗?
- 曝光|realme新机设计专利曝光 超小挖孔屏+椭圆形镜头
- 延续|疑似OPPO Reno5真机亮相 延续上代设计