python-酷我音乐(爬虫)
2020.9.19更新
- 排版美观了点(等学会了QT就做一个GUI)
- 下载方便了(根据序号选择)私信小编01即可获取大量Python学习资料
import requestsimport jsonimport os# 获取音乐数据def music_text():kw = input("搜索音乐(歌手也可):")# 请求头headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36 Edg/84.0.522.63","Cookie":"_ga=GA1.2.1083049585.1590317697; _gid=GA1.2.2053211683.1598526974; _gat=1; Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1597491567,1598094297,1598096480,1598526974; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1598526974; kw_token=HYZQI4KPK3P","Referer": "","csrf": "HYZQI4KPK3P",}# 参数列表params = {"key": kw,# 页数"pn": "1",# 音乐数"rn": "10","httpsStatus": "1","reqId": "cc337fa0-e856-11ea-8e2d-ab61b365fb50",}# 创建列表,后面下载需要music_list = []url = ""res = requests.get(url = url,headers = headers,params = params)res.encoding = "utf-8"text = res.text# 转成json数据json_list = json.loads(text)# 发现data中list是存主要数据的地方datapack = json_list["data"]["list"]# 遍历拿到所需要的数据 , 音乐名称 , 歌手 , id...a = 0for i in datapack:# 音乐名music_name = i["name"]# 歌手music_singer = i["artist"]# 待会需要的id先拿到rid = i["rid"]# 随便试听拿到一个音乐的接口,这是的rid就用得上了api_music = ";rid={} --tt-darkmode-color: #999999;">运行结果
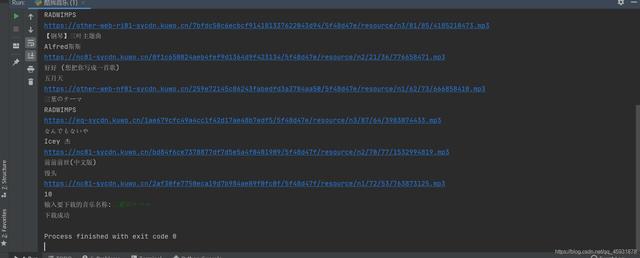 文章插图
文章插图
2020.9.2更新略微改动 , 如图 。 如果输入名字时对应搜索的音乐存在重复名字的情况 , 会直到所有重名的音乐下载完毕才退出程序 。
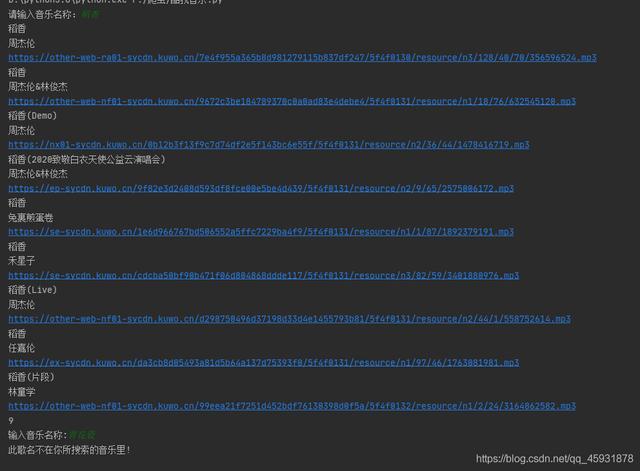 文章插图
文章插图
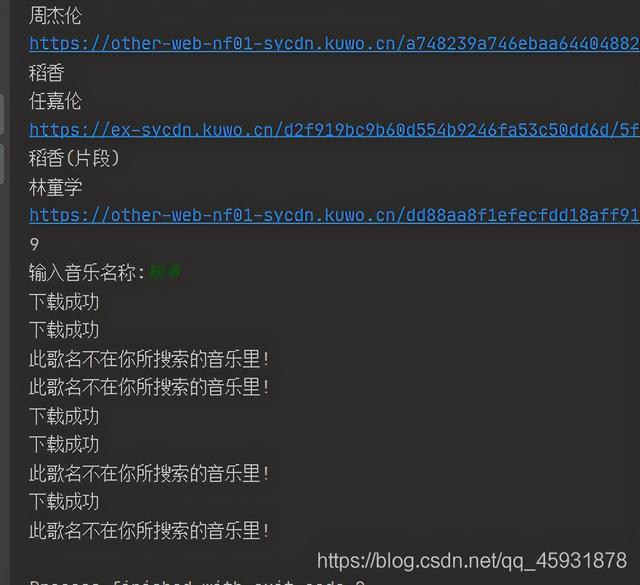 文章插图
文章插图
**
注:请勿用于商业用途
【python-酷我音乐(爬虫)】**
- 平台|Win平台上的本地音乐管理软件,MusicBee
- 蓝海|背靠万亿美元市场,老年人会是音乐产业的新蓝海吗?
- 市占率不足2%,虾米音乐还能听多久?|数据 | 虾米
- 高晓松|虾米音乐倒计时,大文娱总管高晓松还能撑多久
- 关闭|虾米音乐的关闭,再次应证了互联网下竞争的规则,小而精很难生存
- 纪贸易有限|京东关联公司申请“山海音乐节”商标
- 正式|虾米音乐或将关停,音乐流媒体正式步入两极时代?
- 关停|青春结束,当年碾压网易云、QQ音乐的应用要关停?
- 音乐APP“月活跃”用户数:网易云音乐仅第四,榜首意料之中
- 华强北|钢琴音乐会在深圳市福田区华强北科技综合体奏响