埋点模型|如何科学地输出一份的埋点需求文档?
编辑导语:在上一篇文章中,作者主要分享了关于数据埋点的核心问题:当我们在谈论数据埋点时,我们在谈论些什么?;本文作者分享了关于讨论用户行为数据采集工作的核心——埋点模型,我们一起来看一下。
文章插图
《数据埋点,一次讲个够》系列文章的第二篇,讨论用户行为数据采集工作的核心——埋点模型。
主要讨论:
下面来聊一聊埋点模型:
一、事件模型埋点体系中一个非常重要的角度是埋点模型,它决定了我们以什么样的架构收集用户行为信息。
换句话说埋点模型反应的是数据采集的世界观,我们用什么样的视角去理解用户行为;比如,以产品的视角,用户和产品的交互可以理解为浏览了页面、点击了按钮,对于页面浏览的行为,埋点会记录用户id、ip、进入页面时间、页面名称等等,然后把这些数据单独落到一个表中,后续我们基于这张表可以查询 PV、UV 这样的指标。
对于点击行为,埋点会记录用户id、ip、点击时间、按钮名称、按钮所属页面名称,这些信息会落在另外的表中,后续基于这张表可以查询点击某元素的用户数等指标;这样的埋点模型是基于产品视角的,我们把用户对产品的操作分为几种类型,针对不同类的行为设置不同的字段;这是 PC 时代的设计方式,埋点能采集到的内容相对固定,能统计的指标也比较有限,也是 PV、UV、跳出率、停留时长这些,和业务数据打通比较困难,笔者就职的上一家公司,就采用这种模型来设计埋点。
目前主流的埋点模型是「事件模型」,市面上提供用户行为分析服务的绝大多数厂商都采用这种模型,比如,GrowingIO、神策、诸葛IO、TalkingData、友盟、Mixpanel等。
所谓的「事件模型」,其实是「事件 – 用户模型」,简单理解,我们把用户的行为记录为事件和用户,分别存在事件表和用户表中,事件表中记录 Who、When、Where、What、How,即谁在什么时间,什么地点,以什么样的方式,做了一件什么样的事,用户表里面记录了某个用户有什么样的属性特征,比如年龄、性别等。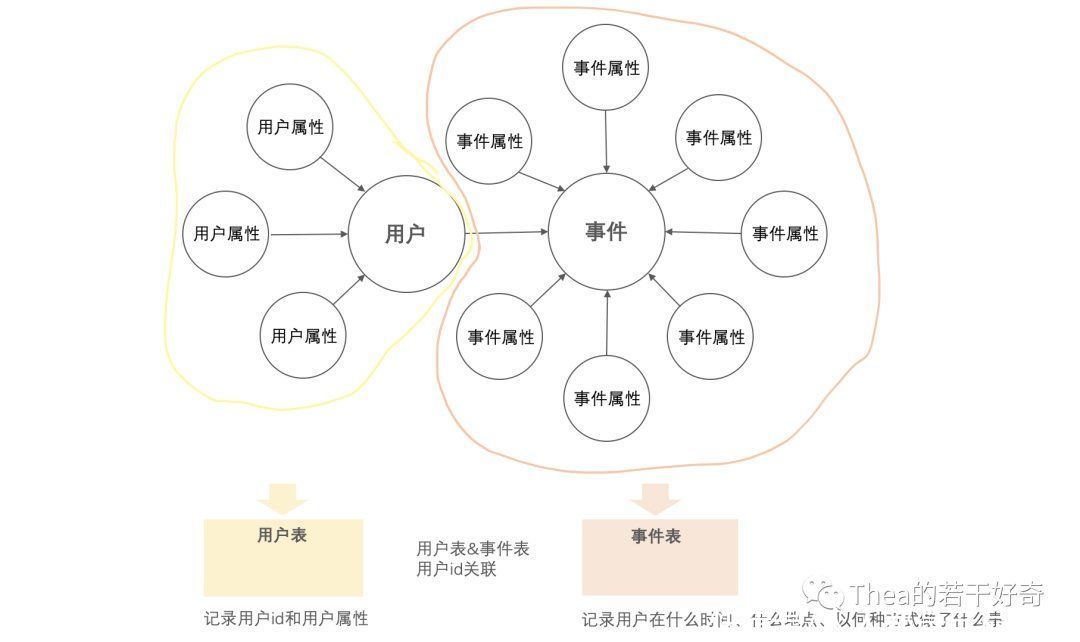
文章插图
在我看来,事件模型有三个优点:
1)抽象能力强,能全面、精细地描述的用户行为
相比于 PC 时代的页面模型,事件模型表达能力更强,能刻画更多类型的用户行为;因为,对于页面模型的埋点,在最开始的时候已经固定好了采集哪几种类型的行为,比如页面浏览、按钮点击、push点击等等,不同类型的埋点也确定了其中会采集哪些字段,如果后续业务同学想在某个埋点中新增个性化的字段是比较麻烦的。
针对添加个性化字段的需求,一种解决方式是,我们在每类埋点中都预留一个 valvus 字段,以 k-v 的形式来记录此类埋点下所有个性化的字段,这样是可以解决问题,但成本比较高:
- 一个字段中存了多个信息,埋点元数据的管理成本增加;
- 这样的字段非常灵活,难以约束业务方按照约定上报数据,有可能会出现一个 values 字段包含了上千个k-v,数据质量难以把控;
- 在后期处理数据时,需要做额外的解析工作。另外,对于页面模型,如果后面要再采集一类埋点,需要重新设计一类埋点,后面的表、查询模型都要重新开发,非常的不灵活。
要把业务数据放入页面模型中是比较困难的,而对于事件模型,只要这个业务过程是有用户参与,就可以把业务数据表示为谁在什么时间、什么地点、以什么样的方式、做了一件什么样的事;随着用户行为分析越来精细,越来越深入业务,打通业务数据和行为数据已经是一件必要的事了,而事件模型在数据采集阶段就解决了这个问题。
3)容易理解,埋点设计起来相对容易
事件模型把用户和用户行为描述为「谁在什么时间,什么地点,以什么样的方式,做了一件什么样的事,这个用户有什么样的属性特征」,非常贴近自然语言,在很大程度上降低了模型的理解难度。
鉴于业界主流已经从页面模型切换到事件模型了,建议在构建埋点体系时尽量采用事件模型。后面的埋点设计也会以事件模型来说。
二、设计埋点设计埋点是按照埋点模型把将业务需求翻译成为开发能懂的语言。
如果采用事件模型,翻译过程可以概括为四个步骤:业务分析、定义指标、事件设计、属性设计。
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 计费|5G是如何计费的?
- 车轮旋转|牵引力控制系统是如何工作的?它有什么作用?
- 视频|短视频如何在前3秒吸引用户眼球?
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 涡轮|看法米特涡轮流量计如何让你得心应手
- 手机|OPPO手机该如何截屏?四种最简单的方法已汇总!
- 和谐|人民日报海外版今日聚焦云南西双版纳 看科技如何助力人象和谐