使用WebAssembly提高模型部署的速度和可移植性
。 文章插图
文章插图
在最近几个月中 , 我们已经帮助许多公司在各种环境中部署其AI / ML模型 。我们为医疗行业的模型部署做出了贡献 , 在过去的几个月中 , 我们已经帮助多家公司将经过训练的模型转移到不同类型的IoT设备上 。特别是在IoT设备情况下 , 要求通常很严格:计算周期数和可用内存通常都受到限制 。
在本文中 , 我阐明了如何确保使用标准ML库(例如PyTorch , Scikit-learn和Tensorflow)训练的模型可以有效地部署在各种边缘设备上 。为了使事情变得切实 , 我们将研究简单的逻辑回归模型的训练和部署 。但是 , 我们在这里讨论的大多数内容都直接转移到更复杂的模型上 。
模型训练为了说明模型训练与部署之间的区别 , 让我们首先模拟一些数据 。下面的代码根据以下简单模型生成1000个观测值:图片发布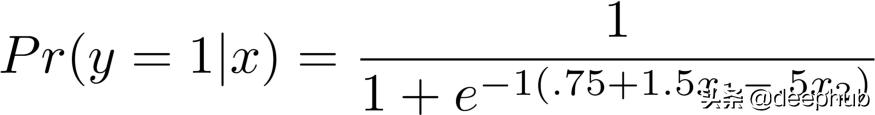 文章插图
文章插图
【使用WebAssembly提高模型部署的速度和可移植性】import numpy as npnp.random.seed(66)# Set seed for replication# Simulate Data Generating Processn = 1000# 1000 observationsx1 = np.random.uniform(-2,2,n)# x_1 其中一个原因是 , 我们可能希望有效地部署模型 , 而不会在每次做出预测时浪费能源 。 但是 , 一个小的内存占用和快速的执行也是很吸引人的 , 因为这正是我们在将模型投入生产的边缘所需要的:好运部署你的Docker容器(例如 , )在ESP32 MCU板上 。 使用WebAssembly , 这是小菜一碟 。
综上所述 , 你一定对WebAssembly十分感兴趣 , 那么看看这个代码吧 , 它包含了本文的所有内容
作者:Maurits Kaptein
deephub翻译组
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- QuestMobile|QuestMobile:百度智能小程序月人均使用个数达9.6个
- 轻松|使用 GIMP 轻松地设置图片透明度
- 电池容量|Windows 自带功能查看笔记本电脑电池使用情况,你的容量还好吗?
- 撕破脸|使用华为设备就罚款87万,英政府果真要和中国“撕破脸”?
- 同级别|卢伟冰再提高像素“方向错了”,红米Note9Pro证明给赵明看
- 冲突|智能互联汽车:通过数据托管模式解决数据使用方面的冲突
- 鼓励|(经济)商务部:鼓励引导商务领域减少使用塑料袋等一次性塑料制品
- 机身|轻松使用一整天,OPPO K7x给你不断电体验