YOLOv5的妙用:学习手语,帮助听力障碍群体
编辑:魔王、杜伟
计算机视觉可以学习美式手语 , 进而帮助听力障碍群体吗?数据科学家 David Lee 用一个项目给出了答案 。
如果听不到了 , 你会怎么办?如果只能用手语交流呢?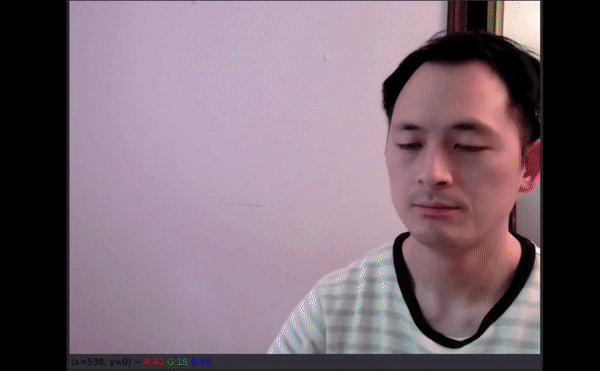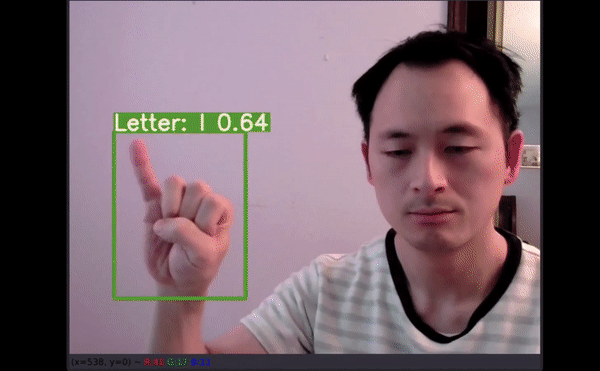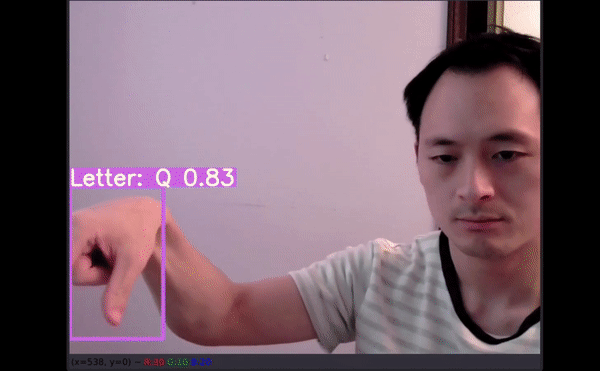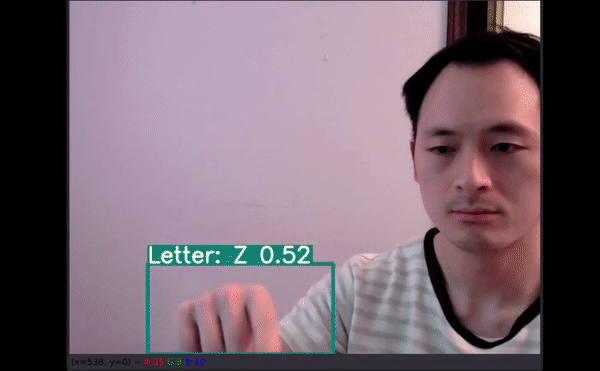 文章插图
文章插图
当对方无法理解你时 , 即使像订餐、讨论财务事项 , 甚至和朋友家人对话这样简单的事情也可能令你气馁 。
对普通人而言轻轻松松的事情对于听障群体可能是很困难的 , 他们甚至还会因此遭到歧视 。 在很多场景下 , 他们无法获取合格的翻译服务 , 从而导致失业、社会隔绝和公共卫生问题 。
为了让更多人听到听障群体的声音 , 数据科学家 David Lee 尝试利用数据科学项目来解决这一问题:
计算机视觉可以学习美式手语 , 进而帮助听力障碍群体吗?
如果通过机器学习应用可以精确地翻译美式手语 , 即使从最基础的字母表开始 , 我们也能向着为听力障碍群体提供更多的便利和教育资源前进一步 。
数据和项目介绍
出于多种原因 , David Lee 决定创建一个原始图像数据集 。 首先 , 基于移动设备或摄像头设置想要的环境 , 需要的分辨率一般是 720p 或 1080p 。 现有的几个数据集分辨率较低 , 而且很多不包括字母「J」和「Z」 , 因为这两个字母需要一些动作才能完成 。 文章插图
文章插图
为此 , David Lee 在社交平台上发送了手语图像数据收集请求 , 介绍了这个项目和如何提交手语图像的说明 , 希望借此提高大家的认识并收集数据 。
项目地址:
数据变形和过采样
David Lee 为该项目收集了 720 张图片 , 其中还有几张是他自己的手部图像 。 由于这个数据集规模较小 , 于是 David 使用 labelImg 软件手动进行边界框标记 , 设置变换函数的概率以基于同一张图像创建多个实例 , 每个实例上的边界框有所不同 。
下图展示了数据增强示例: 文章插图
文章插图
经过数据增强后 , 该数据集的规模从 720 张图像扩展到 18,000 张图像 。
建模
David 选择使用 YOLOv5 进行建模 。 将数据集中 90% 的图像用作训练数据 , 10% 的图像用作验证集 。 使用迁移学习和 YOLOv5m 预训练权重训练 300 个 epoch 。 文章插图
文章插图
在验证集上成功创建具备标签和预测置信度的新边界框 。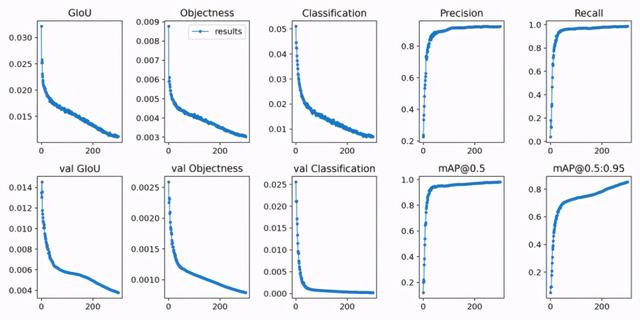 文章插图
文章插图
由于损失值并未出现增长 , 表明模型未过拟合 , 因此该模型或许可以训练更多轮次 。
模型最终获得了 85.27% 的 mAP@.5:.95 分数 。
图像推断测试
David 额外收集了他儿子的手部图像数据作为测试集 。 事实上 , 还没有儿童手部图像用于训练该模型 。 理想情况下 , 再多几张图像有助于展示模型的性能 , 但这只是个开始 。 文章插图
文章插图
26 个字母中 , 有 4 个没有预测结果(分别是 G、H、J 和 Z) 。
四个没有得到准确预测:
D 被预测为 F;
E 被预测为 T;
P 被预测为 Q;
R 被预测为 U 。
视频推断测试文章插图
?即使只有几个手部图像用于训练 , 模型仍能在如此小的数据集上展现不错的性能 , 而且还能以一定的速度提供优秀的预测结果 , 这一结果表现出了很大的潜力 。
更多数据有助于创建可在多种新环境中使用的模型 。
如以上视频所示 , 即使字母有一部分出框了 , 模型仍能给出不错的预测结果 。 最令人惊讶的是 , 字母 J 和 Z 也得到了准确识别 。
?
?其他测试
David 还执行了其他一些测试 , 例如:
左手手语测试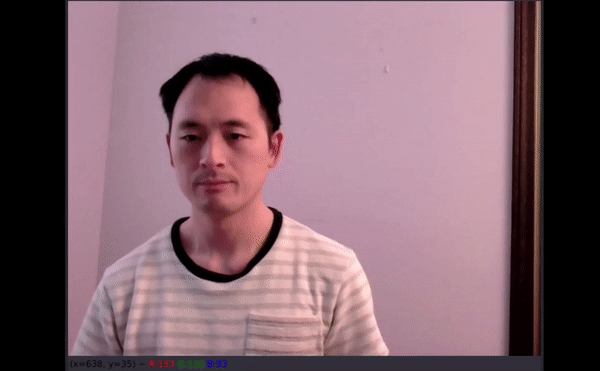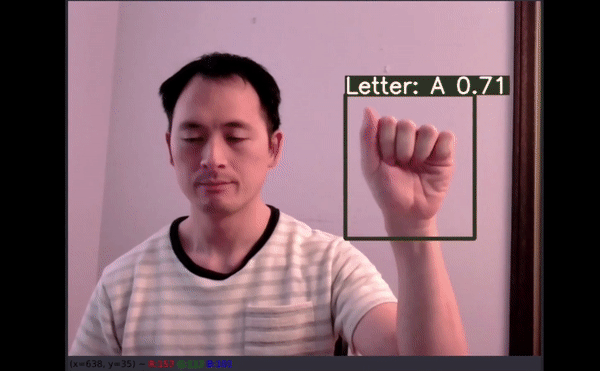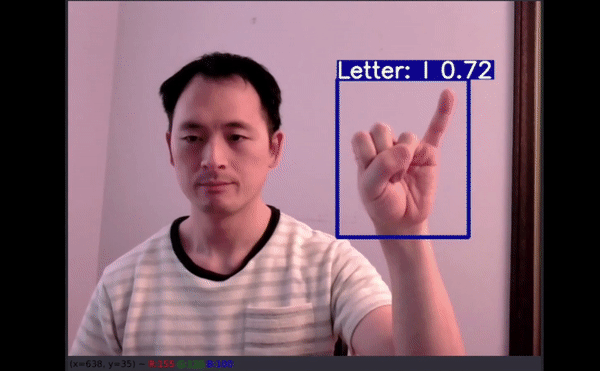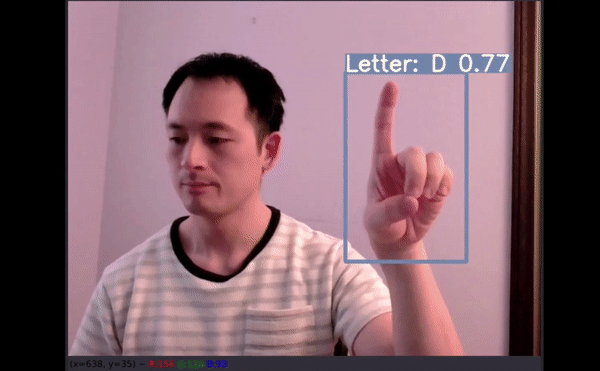 文章插图
文章插图
?
几乎所有原始图像都显示的是右手 , 但 David 惊喜地发现数据增强在这里起到了作用 , 因为有 50% 的可能性是针对左手用户进行水平翻转 。
?儿童手语测试 文章插图
文章插图
?David 儿子的手语数据未被用于训练集 , 但模型对此仍有不错的预测 。
?多实例 文章插图
文章插图
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化
- 中国|浅谈5G移动通信技术的前世和今生
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面