综述|计算机视觉中的注意力机制( 五 )
base_width=64, dilation=1, norm_layer=None,
*, reduction=16):
super(SEBasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes, 1)
self.bn2 = nn.BatchNorm2d(planes)
self.se = SELayer(planes, reduction)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.se(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
ResNet的Basic Block
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
if inplanes != planes:
self.downsample = nn.Sequential(nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes))
else:
self.downsample = lambda x: x
self.stride = stride
def forward(self, x):
residual = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += residual
out = self.relu(out)
return out
两者的差别主要体现在多了一个SElayer , 详细可以查看源码
3、混合域模型(融合空间域和通道域注意力)(1)论文:Residual Attention Network for image classification(CVPR 2017 Open Access Repository)
文章中注意力的机制是软注意力基本的加掩码(mask)机制 , 但是不同的是 , 这种注意力机制的mask借鉴了残差网络的想法 , 不只根据当前网络层的信息加上mask , 还把上一层的信息传递下来 , 这样就防止mask之后的信息量过少引起的网络层数不能堆叠很深的问题 。
该文章的注意力机制的创新点在于提出了残差注意力学习(residual attention learning) , 不仅只把mask之后的特征张量作为下一层的输入 , 同时也将mask之前的特征张量作为下一层的输入 , 这时候可以得到的特征更为丰富 , 从而能够更好的注意关键特征 。 同时采用三阶注意力模块来构成整个的注意力 。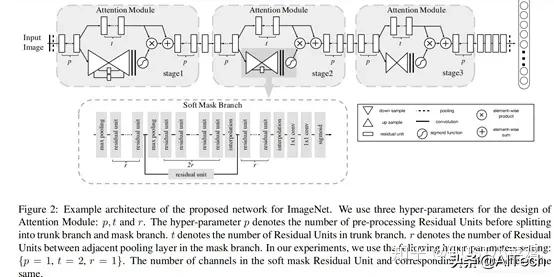 文章插图
文章插图
(2)Dual Attention Network for Scene Segmentation(CVPR 2019 Open Access Repository)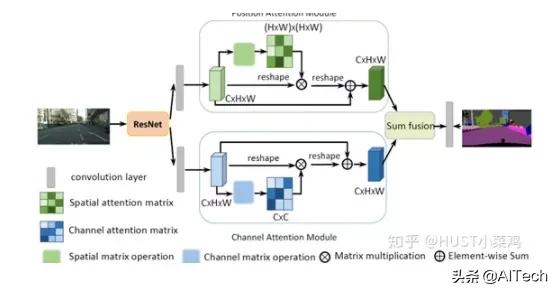 文章插图
文章插图
4、Non-Local论文:non-local neural networks(CVPR 2018 Open Access Repository)
GitHub地址:
Local这个词主要是针对感受野(receptive field)来说的 。 以单一的卷积操作为例 , 它的感受野大小就是卷积核大小 , 而我们一般都选用3*3 , 5*5之类的卷积核 , 它们只考虑局部区域 , 因此都是local的运算 。 同理 , 池化(Pooling)也是 。 相反的 , non-local指的就是感受野可以很大 , 而不是一个局部领域 。 全连接就是non-local的 , 而且是global的 。 但是全连接带来了大量的参数 , 给优化带来困难 。 卷积层的堆叠可以增大感受野 , 但是如果看特定层的卷积核在原图上的感受野 , 它毕竟是有限的 。 这是local运算不能避免的 。 然而有些任务 , 它们可能需要原图上更多的信息 , 比如attention 。 如果在某些层能够引入全局的信息 , 就能很好地解决local操作无法看清全局的情况 , 为后面的层带去更丰富的信息 。
文章定义的对于神经网络通用的Non-Local计算如下所示: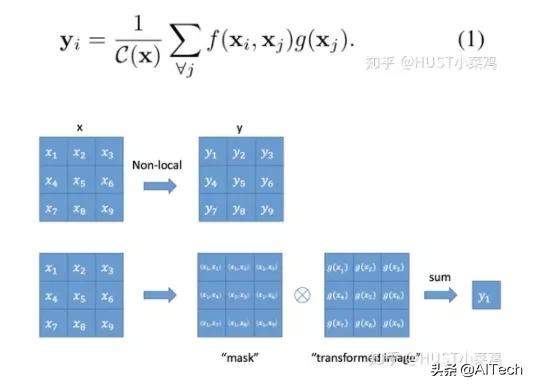 文章插图
文章插图
如果按照上面的公式 , 用for循环实现肯定是很慢的 。 此外 , 如果在尺寸很大的输入上应用non-local layer , 也是计算量很大的 。 后者的解决方案是 , 只在高阶语义层中引入non-local layer 。 还可以通过对embedding(θ,?,g)的结果加pooling层来进一步地减少计算量 。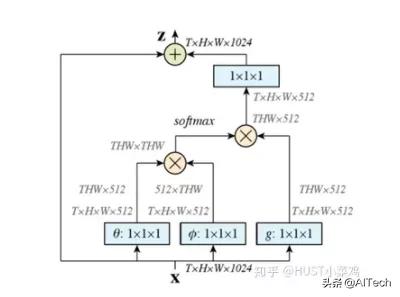 文章插图
文章插图
- 计算机学科|机器视觉系统是什么
- 视觉|首届“征图杯”校园机器视觉人工智能大赛闭幕,16支团队共享百万奖金
- 检测|机器视觉检测解决方案商“鼎纳自动化”完成B轮亿元融资
- 核磁共振|研发用于教研的核磁共振量子计算机,「量旋科技」还想在超导量子技术上取得突破
- 肇观|肇观电子视觉芯片每秒最快可计算181帧(张)视频/图片
- 顶尖的计算机专家,会采用何种方式来看待这个世界
- 吉林大学TARS-GO战队视觉代码
- 更改计算机待机睡眠状态时间方法,电脑设置关闭显示器时间教程
- NCT|NCT获IEEE计算机协会和麻省理工科技评论权威认证
- 首届“征图杯”校园机器视觉人工智能大赛闭幕,16支团队共享百万奖金