第07期:故障排查-为什么发出的告警为已解决?
 文章插图
文章插图
本期作者:吴洋
爱可生上海研发中心成员 , 研发工程师 。
现象测试环境中出现了一个异常的告警现象:一条告警通过 Thanos Ruler 的 HTTP 接口观察到持续处于 active 状态 , 但是从 AlertManager 这边看这条告警为已解决状态 。
按照 DMP 平台的设计 , 告警已解决指的是告警上设置的结束时间已经过了当前时间 。 一条发送至 AlertManager 的告警为已解决状态有三种可能:
1. 手动解决了告警
2. 告警只产生了一次 , 第二次计算告警规则时会发送一个已解决的告警
3. AlertManager 接收到的告警会带着一个自动解决时间 , 如果还没到达自动解决时间 , 则将该时间重置为 24h 后
首先 , 因为了解到测试环境没有手动解决过异常告警 , 排除第一条;
其次 , 由于该告警持续处于 active 状态 , 所以不会是因为告警只产生了一次而接收到已解决状态的告警 , 排除第二条;
最后 , 告警的告警的产生时间与自动解决时间相差不是 24h , 排除第三条 。
那问题出在什么地方呢?
分析下面我们开始分析这个问题 。
综合第一节的描述 , 初步的猜想是告警在到达 AlertManager 前的某些阶段的处理过程太长 , 导致告警到达 AlertManager 后就已经过了自动解决时间 。 我们从分析平台里一条告警的流转过程入手 , 找出告警在哪个处理阶段耗时过长 。
首先 , 一条告警的产生需要两方面的配合:
- metric 数据
- 告警规则
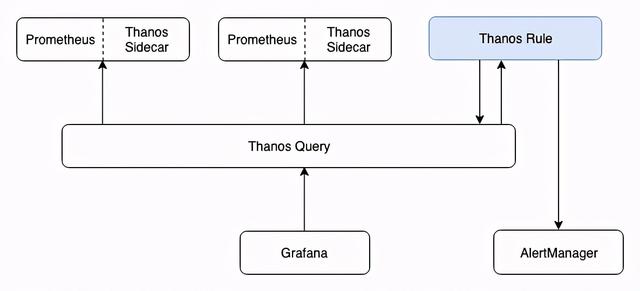
下图是 Ruler 组件在集群中所处的位置:
 文章插图
文章插图看来 , 想要弄清楚现告警的产生到 AlertManager 之间的过程 , 需要先弄清除 Ruler 的大致机制 。 官方文档对 Ruler 的介绍是:You can think of Rule as a simplified Prometheus that does not require a sidecar and does not scrape and do PromQL evaluation (no QueryAPI) 。
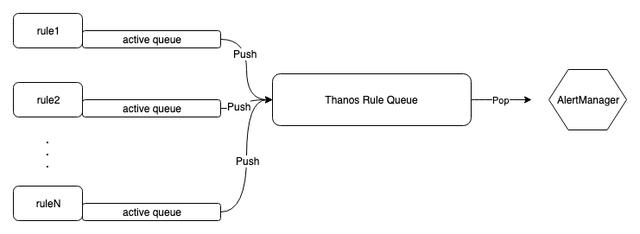
不难推测 , Ruler 应该是在 Prometheus 上封装了一层 , 并提供一些额外的功能 。 通过翻阅资料大致了解 , Ruler 使用 Prometheus 提供的库计算告警规则 , 并提供一些额外的功能 。 下面是 Ruler 中告警流转过程:
 文章插图
文章插图首先 , 图中每个告警规则 Rule 都有一个 active queue(下面简称本地队列) , 用来保存一个告警规则下的活跃告警 。
其次 , 从本地队列中取出告警 , 发送至 AlertManager 前 , 会被放入 Thanos Rule Queue(下面简称缓冲队列) , 该缓冲队列有两个属性:
- capacity(默认值为 10000):控制缓冲队列的大小 ,
- maxBatchSize(默认值为 100):控制单次发送到 AlertManager 的最大告警数
【第07期:故障排查-为什么发出的告警为已解决?】1. 缓冲队列阶段
2. 出缓冲队列到 AlertManager 阶段(网络延迟影响)
由于测试环境是局域网环境 , 并且也没在环境上发现网络相关的问题 , 我们初步排除第二个阶段的影响 , 下面我们将注意力放在缓冲队列上 。 通过相关源码发现 , 告警在缓冲队列中的处理过程大致如下:
如果本地队列中存在一条告警 , 其上次发送之间距离现在超过了 1m(默认值 , 可修改) , 则将该告警放入缓冲队列 , 并从缓冲队列中推送最多 maxBatchSize 个告警发送至 AlertManager 。 反之 , 如果所有本地队列中的告警 , 在最近 1m 内都有发送过 , 那么就不会推送缓冲队列中的告警 。 也就是说 , 如果在一段时间内 , 产生了大量重复的告警 , 缓冲队列的推送频率会下降 。 队列的生产方太多 , 消费方太少 , 该队列中的告警就会产生堆积的现象 。
因此我们不难猜测 , 问题原因很可能是是缓冲队列推送频率变低的情况下 , 单次推送的告警数量太少 , 导致缓冲队列堆积 。 下面我们通过两个方面验证上述猜想:
首先通过日志可以得到队列在大约 20000s 内推送了大约 2000 次 , 即平均 10s 推送一次 。 结合缓冲队列的具体属性 , 一条存在于队列中的告警大约需要 (capacity/maxBatchSize)*10s = 16m , AlertManager 在接收到告警后早已超过了默认的自动解决时间(3m) 。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 同比|亚马逊公布“剁手节”创纪录战绩:第三方卖家全球销售额超48亿美元 同比大增60%
- 产业|前瞻生鲜电商产业全球周报第67期:发力社区团购!京东内部筹划“京东优选”
- 零部件|马瑞利发力电动产品,全球第七大零部件供应商在转型
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 俄罗斯手机市场|被三星、小米击败,华为手机在俄罗斯排名跌至第三!
- 当初|这是我的第一部华为手机,当初花6799元买的,现在“一文不值”?
- 出海|出海日报丨短视频生产服务商小影科技完成近4亿元 C 轮融资;华为成为俄罗斯在线出售智能手机的第一品牌
- 敢动|女生最害怕被“偷看”的3软件,QQ不算啥,第二敢动就“翻脸”
- 报名啦!宿迁开展第五届“十大科技之星”评选