信息|开课吧:我是如何爬取B站全站视频信息?

文章插图
神无月初音ミク - 神无月(中文版)
文章插图

文章插图
B站我想大家都熟悉吧,其实 B 站的爬虫网上一搜一大堆。不过纸上得来终觉浅,绝知此事要躬行,我码故我在。最终爬取到数据总量为 760万 条。
准备工作
首先打开 B 站,随便在首页找一个视频点击进去。常规操作,打开开发者工具。这次是目标是通过爬取 B 站提供的 api 来获取视频信息,不去解析网页,解析网页的速度太慢了而且容易被封 ip。
勾选 JS 选项,F5 刷新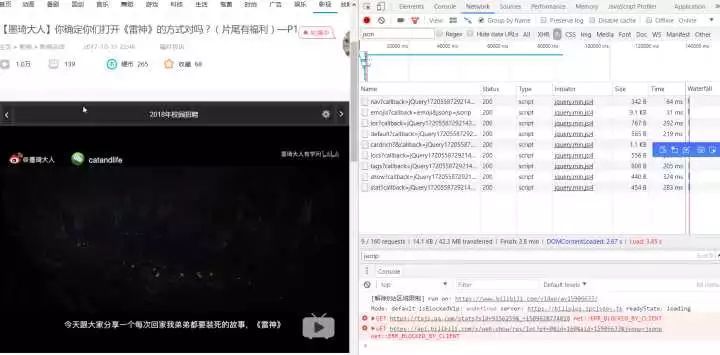
文章插图
找到了 api 的地址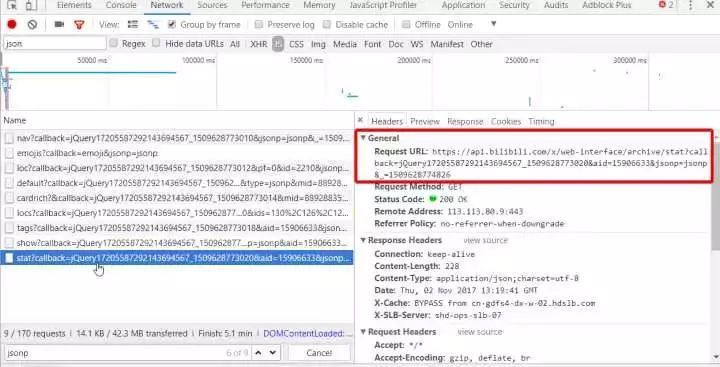
文章插图
复制下来,去除没必要的内容,得到https://api.bilibili.com/x/web-interface/archive/stat?aid=15906633 ,用浏览器打开,会得到如下的 json 数据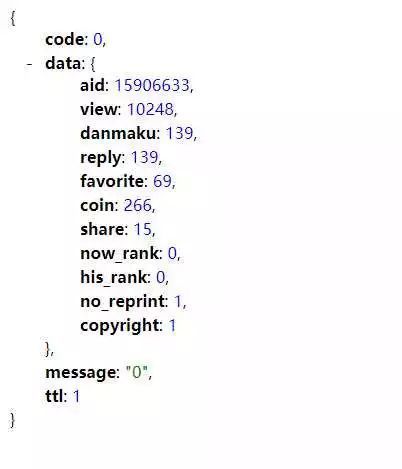
文章插图
动手写码
好了,到这里代码就可以码起来了,通过 request 不断的迭代获取数据,为了让爬虫更高效,可以利用多线程。
核心代码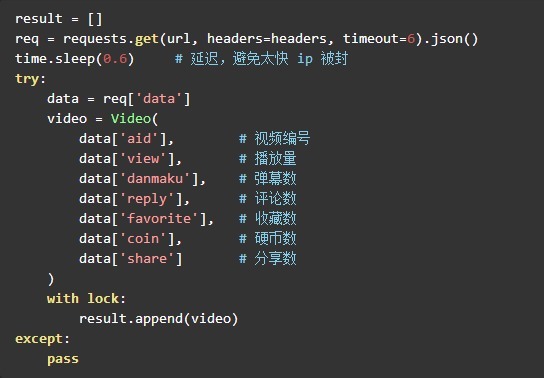
文章插图
迭代爬取
文章插图
整个项目的最主要部分的代码也就是 20 行左右,挺简洁的。
运行的效果大概是这样的,数字是已经已经爬取了多少条链接,其实完全可以在一天或者两天内就把全站信息爬完的。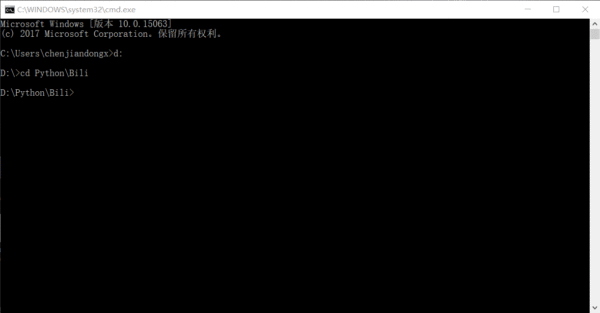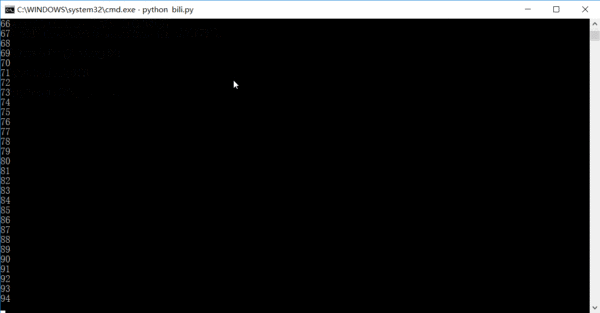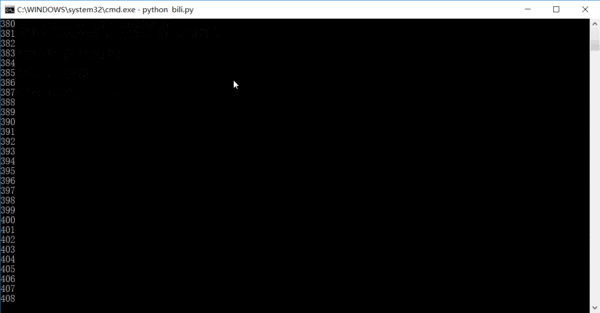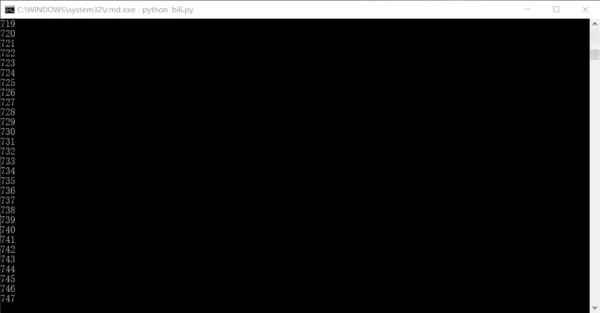
文章插图
至于爬取后要怎么处理就看自己爱好了,我是先保存为 csv 文件,然后再汇总插入到数据库。
数据库表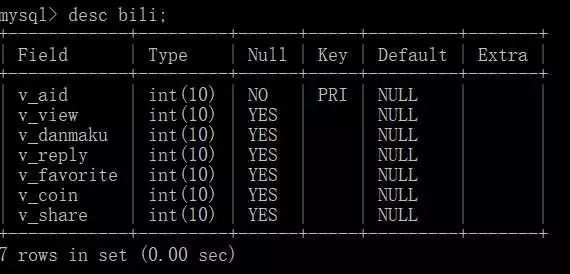
文章插图
由于这些内容是我在几个月前爬取的,所以数据其实有些滞后了。
数据总量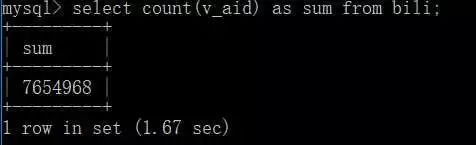
文章插图
查询播放量前十的视频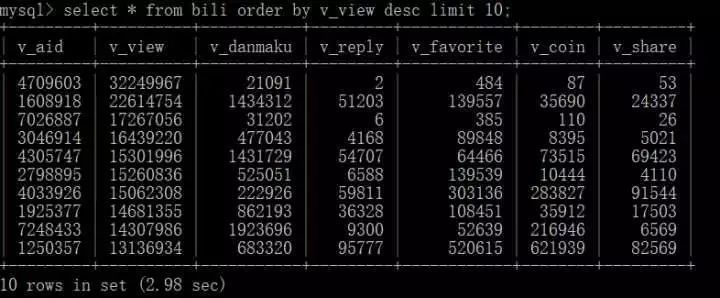
文章插图
查询回复量前十的视频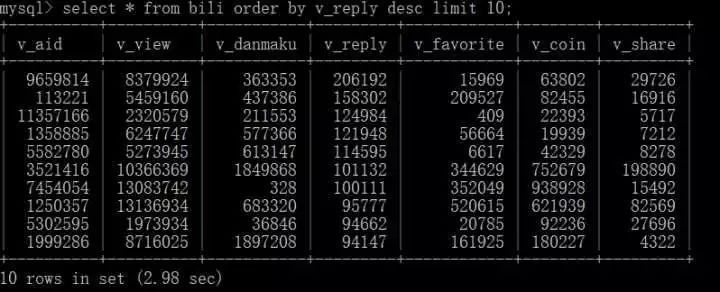
文章插图
【 信息|开课吧:我是如何爬取B站全站视频信息?】各种花样查询任君选择!!关注我了解更多的爬虫知识!
- 信息|澜湄合作机制开通水资源合作信息共享平台
- 通气会|12月4~6日,2020中国信息通信大会将在成都举行
- 互联网|强制收集个人信息?国家网信办拟为38类App戴紧箍
- 建设|龙元建设中标中国移动宁波信息通信产业园二期施工项目
- 湖北|湖北将建立进口冷链食品信息追溯平台
- 贵阳|捷顺科技(002609.SZ)中标贵阳智慧停车公共信息服务平台系统建设项目
- 注册|阿里申请注册“爆改吧!小店”商标,打造线下特色实体小店
- 算法|【远见】个人信息保护法将出台 揭开数据算法的神秘“面纱”
- 5G|想入手iPhone 12吗?如果你是这四种人,我劝你还是放弃吧!
- 用户|自称百度旗下平台,收集用户信息,为资金盘倒流,这个坑你踩过吗?