Python爬虫入门,详细讲解爬虫过程
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
以下文章来源于凌晨安全 , 作者 MoLing 文章插图
文章插图
1. 爬虫就是模拟浏览器抓取东西 , 爬虫三部曲:数据爬取、数据解析、数据存储数据爬取:手机端、pc端数据解析:正则表达式数据存储:存储到文件、存储到数据库
2. 相关python库爬虫需要两个库模块:requests和re
1. requests库
requests是比较简单易用的HTTP库 , 相较于urllib会简洁很多 , 但由于是第三方库 , 所以需要安装 , 文末附安装教程链接(链接全在后面 , 这样会比较方便看吧 , 贴心吧~)
requests库支持的HTTP特性:
保持活动和连接池、Cookie持久性会话、分段文件上传、分块请求等
Requests库中有许多方法 , 所有方法在底层的调用都是通过request()方法实现的 , 所以严格来说Requests库只有request()方法 , 但一般不会直接使用request()方法 。 以下介绍Requests库的7个主要的方法:
①requests.request()
构造一个请求 , 支撑一下请求的方法
具体形式:requests.request(method,url,**kwargs)
method:请求方式 , 对应get,post,put等方式
url:拟获取页面的url连接
**kwargs:控制访问参数
②requests.get()
获取网页HTM网页的主要方法 , 对应HTTP的GET 。 构造一个向服务器请求资源的Requests对象 , 返回一个包含服务器资源的Response对象 。
Response对象的属性: 文章插图
文章插图
【Python爬虫入门,详细讲解爬虫过程】 具体形式:res=requests.get(url)
code=res.text (text为文本形式;bin为二进制;json为json解析)
③requests.head()
获取HTML的网页头部信息 , 对应HTTP的HEAD
具体形式:res=requests.head(url)
④requests.post()
向网页提交post请求方法 , 对应HTTP的POST
具体形式:res=requests.post(url)
⑤requests.put()
向网页提交put请求方法 , 对应HTTP的PUT
⑥requests.patch()
向网页提交局部修改的请求 , 对应HTTP的PATCH
⑦requests.delete()
向网页提交删除的请求 , 对应HTTP的DELETE
# requests 操作练习import requestsimport re#数据的爬取h = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'}response = requests.get('',headers=h)html_str = response.text#数据解析pattern = re.compile('')#.*? 任意匹配尽可能多的匹配尽可能少的字符result = re.findall(pattern,html_str)print(result)2. re正则表达式:(Regular Expression)
一组由字母和符号组成的特殊字符串 , 作用:从文本中找到你想要的格式的句子
关于 .*? 的解释: 文章插图
文章插图
3. xpath解析源码import requestsimport refrom bs4 importBeautifulSoupfrom lxml import etree#数据爬取(一些HTTP头的信息)h = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'}response = requests.get('',headers=h)html_str = response.text#数据解析#正则表达式解析def re_parse(html_str):pattern = re.compile('4. python写爬虫的架构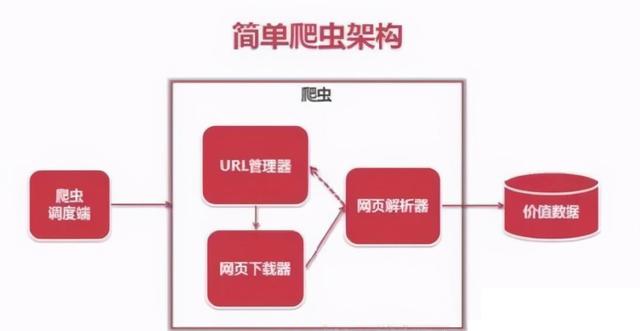 文章插图
文章插图
从图上可以看到 , 整个基础爬虫架构分为5大类:爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储器 。
下面给大家依次来介绍一下这5个大类的功能:
① 爬虫调度器:主要是配合调用其他四个模块 , 所谓调度就是取调用其他的模板 。
② URL管理器:就是负责管理URL链接的 , URL链接分为已经爬取的和未爬取的 , 这就需要URL管理器来管理它们 , 同时它也为获取新URL链接提供接口 。
③ HTML下载器:就是将要爬取的页面的HTML下载下来 。
④ HTML解析器:就是将要爬取的数据从HTML源码中获取出来 , 同时也将新的URL链接发送给URL管理器以及将处理后的数据发送给数据存储器 。
⑤ 数据存储器:就是将HTML下载器发送过来的数据存储到本地 。
0x01 whois爬取 每年 , 有成百上千万的个人、企业、组织和政府机构注册域名 , 每个注册人都必须提供身份识别信息和联系方式 , 包括姓名、地址、电子邮件、联系电话、管理联系人和技术联系人一这类信息通常被叫做whois数据
import requestsimport reh = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'}response = requests.get(''+input("请输入网址:"),headers=h)print(response.status_code)html = response.text#print(html)#解析数据pattern = re.compile('class="MoreInfo".*?>(.*?)
- 入门|做抖音影视赚钱比工资多,教大家新手也可快速入门
- 开发人员|ER(实体关系)建模入门指引
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- Python中文速查表-Pandas 基础
- 零基础小白Python入门必看:通俗易懂,搞定深浅拷贝