Python搭建代理池,为你的爬虫程序保驾护航
由于爬虫工作往往有大量数据需要爬取 , 便需要大量的备用IP更换 , 这时就需要用到代理IP池 。 将大量可以用于更换的代理IP汇聚要一起 , 便于管理和调用 , IP池就这样产生了 。 IP池有一下特征:它里面的IP是持续补充的 , 会有源源不断的新的IP被加入到池子中 。 它里面的IP是有生命周期的 , 一但失效就会被清除出 IP池;它里面的IP是可以被任意取出 , 方便爬虫用户使用的 。
私信小编01即可获取大量Python学习资料
免费ip其实是不适合搭建代理池的 , 因为数量上面不具备优势 , 而且很耗时 , 大家需要用时间来一一排查 , 要做就要做好 , 建议大家还是选择专业一点的提供商 。
代理池主要分四个部分:IP抓取 , IP有效性检测 , IP存储 , webAPI提供 。 示意图如下: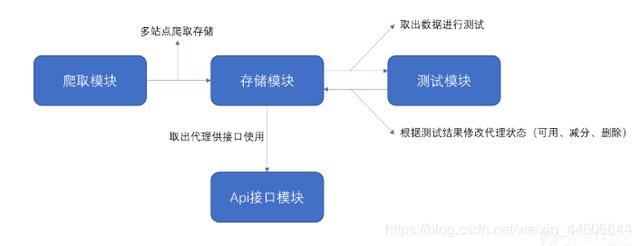 文章插图
文章插图
数据库选择redis , 它的有序集合可以给插入值赋于一个"分数"用于排序存取值等等 , 我们可以利用分数绑定ip的可用性进行提取及检测管理 。 Redis有序集合的基本操作
- 爬取模块
class BaseCrawler(object):urls = []# new_loop = asyncio.new_event_loop()# asyncio.set_event_loop(new_loop)LOOP = asyncio.get_event_loop()asyncio.set_event_loop(LOOP)@retry(stop_max_attempt_number=3, retry_on_result=lambda x: x is None)async def _get_page(self, url):async with aiohttp.ClientSession() as session:try:async with session.get(url,timeout=10) as resp:# print(dir(resp.content),resp.content)return await resp.text()except:return ''def crawl(self):"""crawl main method"""for url in self.urls:app_logger.info(f'fetching {url}')# html = self.LOOP.run_until_complete(asyncio.gather(self._get_page(url)))html = self.LOOP.run_until_complete(self._get_page(url))# print('html', html)for proxy in self.parse(html):# app_logger.info(f'fetched proxy {proxy.string()} from {url}')yield proxy注:一般采取付费的代理平台 , IP稳定寿命长 。- 测试模块
class Tester(object):"""tester for testing proxies in queue"""def __init__(self):self.redis = RedisClient()self.loop = asyncio.get_event_loop()async def test(self, proxy):"""test single proxy:param proxy::return:"""async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(ssl=False)) as session:try:app_logger.debug(f'testing {proxy}')async with session.get(TEST_URL, proxy=f'http://{proxy}', timeout=TEST_TIMEOUT,allow_redirects=False) as response:if response.status in TEST_VALID_STATUS:self.redis.set_max(proxy)app_logger.debug(f'proxy {proxy} is valid, set max score')else:self.redis.decrease(proxy)app_logger.debug(f'proxy {proxy} is invalid, decrease score')except EXCEPTIONS:self.redis.decrease(proxy)app_logger.debug(f'proxy {proxy} is invalid, decrease score')def run(self):"""test main method:return:"""# event loop of aiohttpapp_logger.info('stating tester...')count = self.redis.count()app_logger.debug(f'{count} proxies to test')for i in range(0, count, TEST_BATCH):# start end end offsetstart, end = i, min(i + TEST_BATCH, count)app_logger.debug(f'testing proxies from {start} to {end} indices')proxies = self.redis.batch(start, end)tasks = [self.test(proxy) for proxy in proxies]# run tasks using event loopself.loop.run_until_complete(asyncio.wait(tasks))- API接口模块
__all__ = ['app']app = Flask(__name__)def get_conn():"""get redis client object:return:"""if not hasattr(g, 'redis'):g.redis = RedisClient()return g.redis@app.route('/')def index():"""get home page, you can define your own templates:return:"""return 'Welcome to Proxy Pool System'@app.route('/random')def get_proxy():"""get a random proxy:return: get a random proxy"""conn = get_conn()return conn.random()@app.route('/count')def get_count():"""get the count of proxies:return: count, int"""conn = get_conn()return str(conn.count())以上为代理池的基本功能 , 另外需要再创建一个调度器协调控制各功能模块 , 检测与获取IP需要定时进行 , web服务在后台运行 。 定时采用Python的定时管理库apscheduler , 同时通过multiprocessing管理各功能模块多进程运行 。【Python搭建代理池,为你的爬虫程序保驾护航】
- 票票|淘票票经营主体公司改名,经营范围新增文艺经纪代理
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- Python中文速查表-Pandas 基础
- 零基础小白Python入门必看:通俗易懂,搞定深浅拷贝
- Python 使用摄像头监测心率!这么强吗?