Hinton新作!越大的自监督模型,半监督学习需要的标签越少
 文章插图
文章插图
编译 | 青暮
本文介绍了Hinton团队发表在NeurIPS 2020上的一项研究工作 , 一作是Ting Chen , 研究人员首次在ImageNet上尝试了半监督学习的典型范式 , 并取得了优越的结果 。 此外 , 他们还发现 , 网络的规模越大 , 需要的标签数据越少 。
论文地址:
仅使用1%的标签(每类≤13个标签图像) , 本文提出的方法即可达到73.9%ImageNet top-1准确率 , 与以前的SOTA相比 , 标签效率提高了10倍 。
使用10%的标签 , 本文的方法可以达到77.5%的top-1准确率 , 优于使用100%标签的标准监督训练 。
“无监督预训练、监督微调”范式
充分利用少量标记示例和大量未标记示例进行学习是机器学习的一个长期存在的问题 。
【Hinton新作!越大的自监督模型,半监督学习需要的标签越少】人们曾经提出一种半监督学习来试图解决这个问题 , 其中涉及无监督或自监督的预训练 , 然后进行有监督的微调 。
这种方法在预训练期间以与任务无关的方式利用未标记的数据 , 仅在有监督微调时使用带标签的数据 。
这种方法在计算机视觉上很少受关注 , 但是在自然语言处理中已成为主流 。 例如 , 人们首先在未标记的文本(例如Wikipedia)上训练大型语言模型 , 然后在一些带标记的示例中对该模型进行微调 。
基于视觉表示的自监督学习的最新进展 , Ting Chen等人对ImageNet上的半监督学习进行了深入研究 , 并首次探索了“无监督预训练、监督微调”范式 。
通过与任务无关的方式使用未标记数据 , 作者发现 , 网络规模非常重要 。
也就是说 , 使用大型(在深度和广度上)神经网络进行自监督的预训练和微调 , 可以大大提高准确率 。
除了网络规模之外 , 作者表示 , 这项研究还为对比表示学习提供了一些重要的设计选择 , 这些选择有益于监督微调和半监督学习 。
一旦卷积网络完成了预训练和微调 , 其在特定任务上的预测就可以得到进一步改善 , 并可以提炼成更小的网络 。
为此 , 作者接下来再次使用了未标记的数据 , 以让学生网络模仿教师网络的标签预测 。
这种使用未标记数据的蒸馏阶段类似于自训练中伪标签的使用 , 但没有增加太多额外的复杂性 。
作者提出的半监督学习框架包括三个步骤 , 如图3所示 。
(1)无监督或自我监督的预训练;
(2)有监督的微调;
(3)使用未标记的数据进行蒸馏 。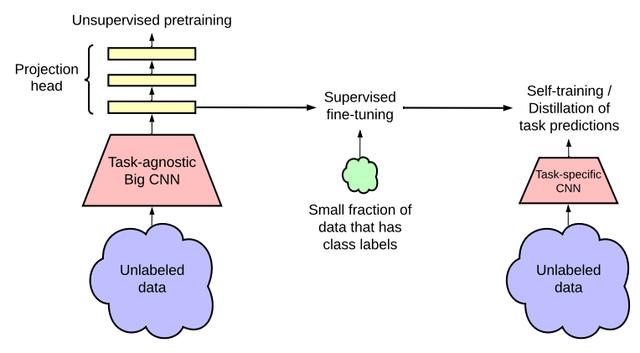 文章插图
文章插图
图3:本文提出的半监督学习框架 。 该框架通过两种方式利用未标记的数据:(1)在无监督的预训练中与任务无关的用法 , (2)在自训练/蒸馏中的任务特定的用法 。
此外 , 作者还开发了对比学习框架SimCLR的改进版本 , 用于ResNet架构的无监督预训练 , 此框架被称为SimCLRv2 。
在ImageNet ILSVRC-2012上评估该方法的有效性 , 作者发现 , 仅需要1%和10%的标签 , 就可以实现与过去SOTA方法相当的性能 。
作者表示 , 对于这种范式的半监督学习 , 标记越少 , 就越有可能受益于更大的模型 , 如图1所示 。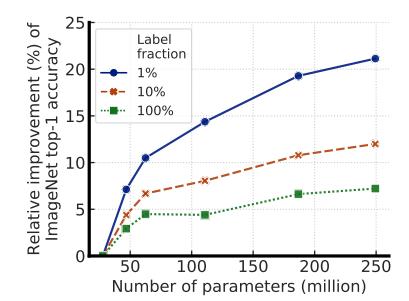 文章插图
文章插图
图1:使用较少标记的示例进行微调时 , 较大的模型会产生较大的收益 。
较大的自监督模型具有更高的标签效率 , 即使仅对少数几个带有示例的示例进行微调 , 它们的性能也明显更好 。
因此 , 通过未标记数据的特定任务使用 , 可以进一步提高模型的预测性能 , 并将其迁移到较小的网络中 。
作者进一步证明了 , 在SimCLR中用于半监督学习的卷积层之后 , 进行非线性变换(又称投影头)很重要 。
更深的投影头不仅可以改善通过线性评估测得的表示质量 , 而且还可以改善从投影头中间层进行微调时的半监督性能 。
结合这些发现 , 该框架在ImageNet上实现了半监督学习的SOTA , 如图2所示 。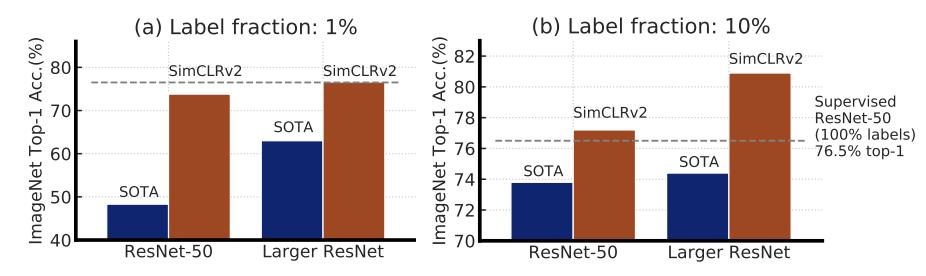 文章插图
文章插图
图2:仅使用1%/10%的标签 , 在ImageNet上 , 以前的SOTA方法和本文方法(SimCLRv2)的top-1准确率 。 虚线表示完全监督下的ResNet-50进行100%标签训练 。 完整比较见表3 。
在线性评估协议下 , SimCLRv2实现了79.8%的top-1准确率 , 相对于之前的SOTA的改进为4.3% 。
如果仅对1%/ 10%的标记示例进行微调 , 并使用未标记的示例将其蒸馏至相同的架构 , 则可以达到76.6%/ 80.9%的top-1准确率 , 相对于以前的SOTA , 准确率提高了21.6%/ 8.7% 。
- 成本|越拆越亏!旧家电回收面临成本困境:拆解一台旧电视亏损超20元
- 中国|对越南新增投资18亿?把30%的生产线转移?富士康真要跑了?
- 车一族|直播|@爱车一族:60分钟穿越汽车的前世今生
- 便携式水枪|区城管委保洁一队创新作业模式
- 摄像头|华为Mate40或采用五摄加一传感器,摄像头越多真越好
- 智能手机品|越南手机悄然崛起!创立短短2年时间,在当地接连击退苹果、小米
- 中国首富又换人了?马云凭100亿优势超越马化腾,网友:厉害了
- 为何越是发达国家,越不流行移动支付,无现金时代有多可怕?
- iPhone12Pro|华为再爆新机,P50Pro暗藏三大优势,全面超越iPhone12Pro
- NIST测试显示人脸识别系统对蒙面人的识别能力越来越强