基于微博平台的python爬虫数据采集,非常简单的小案例
- 搭建环境
- 代码设计
- 使用说明及效果展示
Anaconda3
2. 环境搭建问题
- 配置Anaconda环境变量问题:anaconda未设置在环境变量里 , 导致使用pip下载python自带的库时无法下载到对应的路径进行使用 。 解决:在电脑的环境变量中添加anaconda的路径 。
- 使用pip网络问题问题:因为网速过慢的原因导致无法正常使用pip进行更新以及python库的下载 。 WARNING: pip is configured with locations that require TLS/SSL,however the ssl module in Python is not available.解决:输入命令改为pip install xxx -i--trusted-host pypi.douban.com , 使用豆瓣源进行下载 。
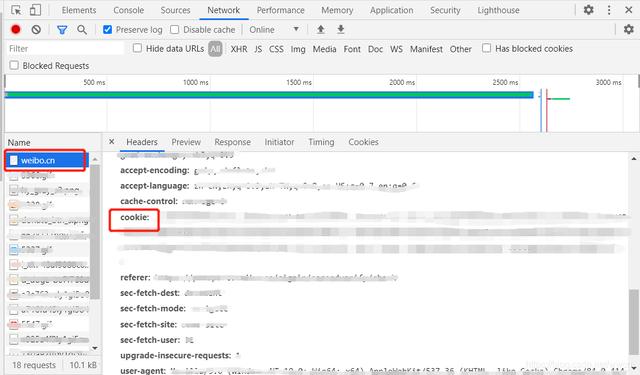
爬取平台:微博 www.weibo.cn获取cookie:使用用户名+密码登录www.weibo.cn 后 , 点击键盘F12 进入控制台界面 。 在network中找到名为weibo.cn的记录 , 点击查看里面的cookies 。
 文章插图
文章插图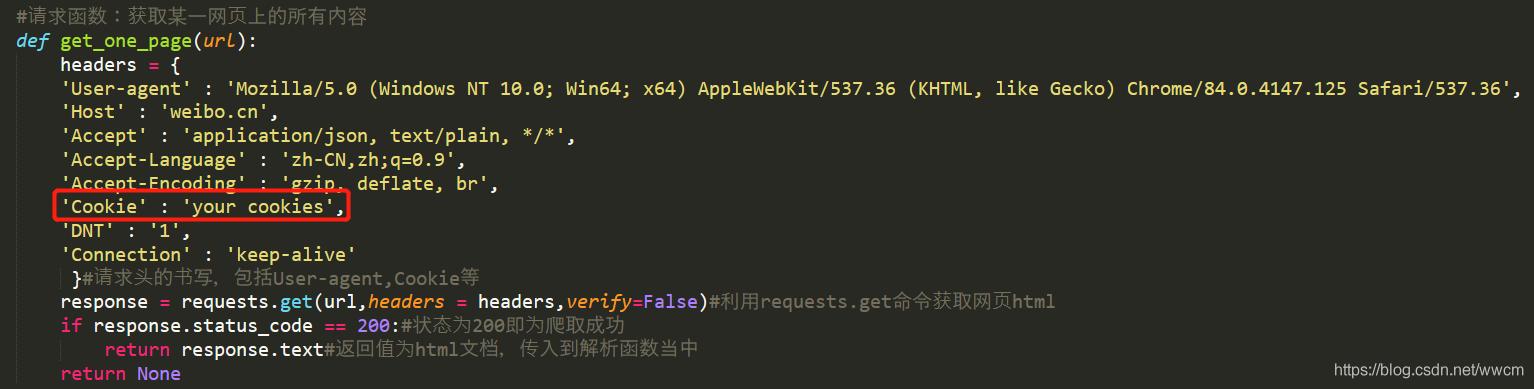 文章插图
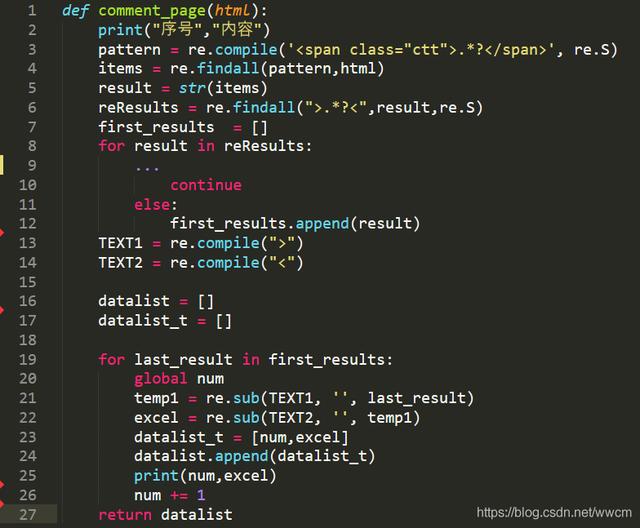
文章插图2. 爬取数据- 爬取文字该函数主要是用来爬取文字内容 , 其中省略了部分对于冗余字符的处理 。
 文章插图
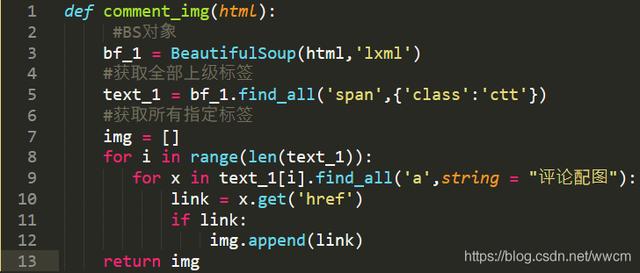
文章插图- 爬取图片该函数主要是用来爬取图片内容 , 其中根据微博图片/评论图片的不同 , 对于标签的筛选不同 。
 文章插图
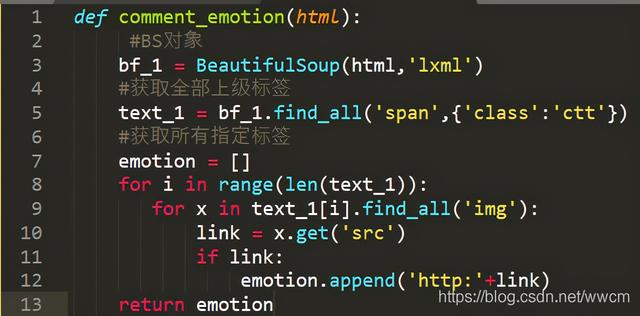
文章插图- 爬取表情该函数主要是用来爬取微博评论表情内容 。
 文章插图
文章插图三、使用说明及效果展示1. 使用说明
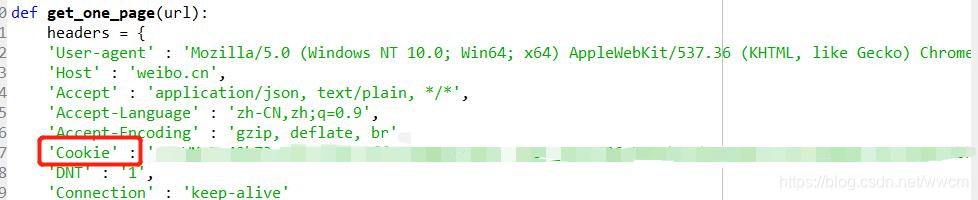
- 修改cookie
 文章插图
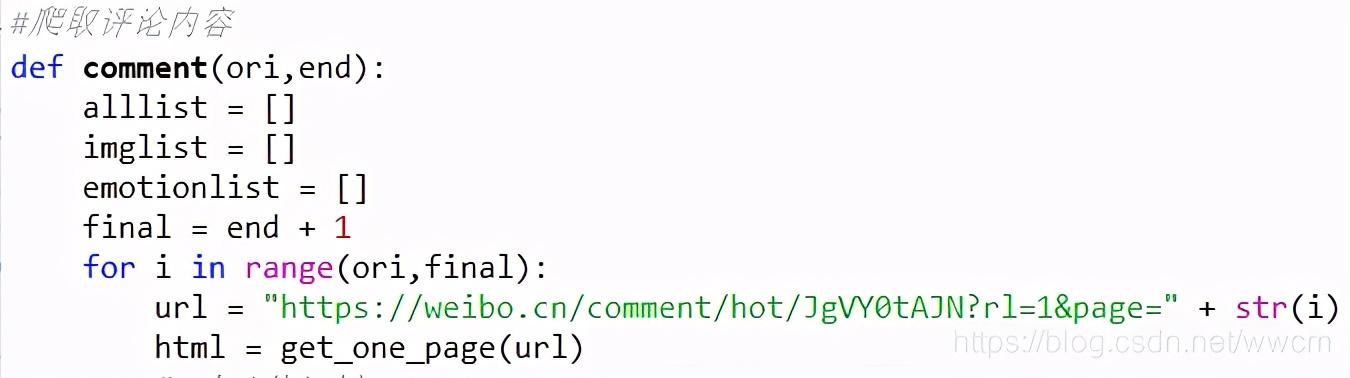
文章插图- 修改微博评论的网址为所要爬取的微博评论 , 以“page=”结尾
 文章插图
文章插图- 在程序所在位置的同级目录下创建两个文件夹分别为:评论图片、评论表情 。 (本代码使用的相对路径 , 无需修改代码中的路径)
- 运行程序输入爬取的起始页数、终止页数
- 已爬取相应内容附源代码:
"""环境: Python 3.7.4内容:爬取微博评论内容、图片、表情修改时间:2020.10.27@author: Wenwen"""import requestsimport urllib.requestimport reimport timeimport csvfrom bs4 import BeautifulSoupnum = 1list_content = []list_t = []#请求函数:获取某一网页上的所有内容def get_one_page(url):headers = {'User-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36','Host' : 'weibo.cn','Accept' : 'application/json, text/plain, */*','Accept-Language' : 'zh-CN,zh;q=0.9','Accept-Encoding' : 'gzip, deflate, br','Cookie' : '_T_WM=7c42b73c4c9cfa6fc4ff7350804c4504; SUB=_2A25yR6oNDeRhGedO41AZ8CzJyz2IHXVRyzZFrDV6PUJbktAKLXfakW1Nm4uHzxmmnLSVywkxToubmHotH6MGAF_Y; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9W5cHZZGnYY4KoxQoDxu1c2T5NHD95QpehnE1h5ESK5pWs4DqcjHIsyQi--Ri-zciKnfi--RiK.7iKyh; SUHB=0jBFua3v6DW2fH; SSOLoginState=1598282334','DNT' : '1','Connection' : 'keep-alive'}#请求头的书写 , 包括User-agent,Cookie等response = requests.get(url,headers = headers,verify=False)#利用requests.get命令获取网页htmlif response.status_code == 200:#状态为200即为爬取成功return response.text#返回值为html文档 , 传入到解析函数当中return None#爬取微博评论内容def comment_page(html):print("序号","内容")pattern = re.compile('.*?', re.S)items = re.findall(pattern,html)result = str(items)reResults = re.findall(">.*?<",result,re.S)first_results= []for result in reResults:#print(result)if ">\'][\'<"in result:continueif ">:<"in result:continueif "回复<"in result:continueif ">评论配图<"in result:continueif "><"in result:continueif ">\', \'<"in result:continueif "@"in result:continueif "> <"in result:continueelse:first_results.append(result)#print("first:",firstStepResults)TEXT1 = re.compile(">")TEXT2 = re.compile("<")datalist = []datalist_t = []for last_result in first_results:global numtemp1 = re.sub(TEXT1, '', last_result)excel = re.sub(TEXT2, '', temp1)datalist_t = [num,excel]datalist.append(datalist_t)print(num,excel)with open('.\\微博评论内容.txt','a',encoding='utf-8') as fp:fp.write(excel)num += 1'''if datalist == datalist1:datalist.clear()else:datalist1 = datalist'''return datalist#爬取微博评论的图片def comment_img(html):#BS对象bf_1 = BeautifulSoup(html,'lxml')#获取全部上级标签text_1 = bf_1.find_all('span',{'class':'ctt'})#获取所有指定标签img = [] #img1 = []for i in range(len(text_1)):for x in text_1[i].find_all('a',string = "评论配图"):link = x.get('href')if link:img.append(link) #if img == img1: #img.clear() #else: #img1 = imgreturn img#爬取微博评论的表情def comment_emotion(html):#BS对象bf_1 = BeautifulSoup(html,'lxml')#获取全部上级标签text_1 = bf_1.find_all('span',{'class':'ctt'})#获取所有指定标签emotion = []#emotion1 = []for i in range(len(text_1)):for x in text_1[i].find_all('img'):link = x.get('src')if link:emotion.append('http:'+link)#if emotion == emotion1:#emotion.clear()#else:#emotion1 = emotionreturn emotion#爬取评论内容 def comment(ori,end):alllist = []imglist = []emotionlist = []final = end + 1for i in range(ori,final):url = ";page=" + str(i)html = get_one_page(url)#print(html)print('正在爬取第 %d 页评论' % (i))alllist = alllist + comment_page(html)imglist = imglist + comment_img(html)emotionlist = emotionlist + comment_emotion(html)time.sleep(3)if i == end :print('爬取结束 , 共爬取 %d 页评论' %(end-ori+1))print('保存评论到微博评论内容.csv文件中......')store_text(alllist)print('保存评论图片到文件夹中......')#print('comment_img:',imglist)store_img(imglist)print('保存评论表情到文件夹中......')#print('comment_emotion:',emotionlist)store_emotion(emotionlist)print('保存完毕!')#存储微博评论内容def store_text(list):with open('.\\微博评论内容.csv','w',encoding='utf-8-sig',newline='') as f:'''f.write('content\n')f.write('\n'.join(list))'''csv_writer = csv.writer(f)for item in list:csv_writer.writerow(item)f.close()#存储微博评论图片def store_img(list):j=0for imgurl in list:urllib.request.urlretrieve(imgurl,'.\\评论图片\\%s.jpg' % j)j+=1#存储微博评论表情def store_emotion(list):k=0for imgurl in list:urllib.request.urlretrieve(imgurl,'.\\评论表情\\%s.jpg' % k)k+=1if __name__=="__main__":ori = input("请输入你要爬取的起始页数:")end = input("情输入你要爬取的终止页数:")ori = int(ori)end = int(end)if ori and end:print("将会爬取第 %d 页到第 %d 页的评论内容" %(ori,end))comment(ori,end)else:print("请输入符合规范的数字!")
- 信息|澜湄合作机制开通水资源合作信息共享平台
- 互联网|苏宁跳出“零售商”重组互联网平台业务 融资60亿只是第一步
- 黑莓(BB.US)盘前涨逾32%,将与亚马逊开发智能汽车数据平台|美股异动 | US
- 发展|我省要求互联网平台坚持依法合规经营 推动线上经济健康规范发展
- 平台|Win平台上的本地音乐管理软件,MusicBee
- 短视频平台|大数据佐证,抖音带动三千万就业,视频手机将成生产力工具?
- 主题活动|首届“上海在线生活节”启动,8大电商平台优惠活动承包你的12月
- 优化|微软亚洲研究院发布开源平台“群策 MARO” 用于多智能体资源调度优化
- 羊毛|12月1日至15日,首届“上海在线生活节”来了,八大电商平台等你薅羊毛
- 小区|超方便!晋安这个平台在支付宝上线!快来体验