Python爬取网页信息并保存为CSV文件!又学了一招
本次爬取的网页是猎聘网内关于深圳的所有招聘信息 , 一共400多个职位 , 并保存为csv文件存储 , 好了 , 话不多说 , 开始进入讲解 。 (对爬虫感兴趣的 , 可以参考此篇文章的做法去爬你想要的网站去吧!!!)
首先打开目标网站:
页面信息如下(因为招聘信息是动态 , 可能你的界面的职位会有所不同)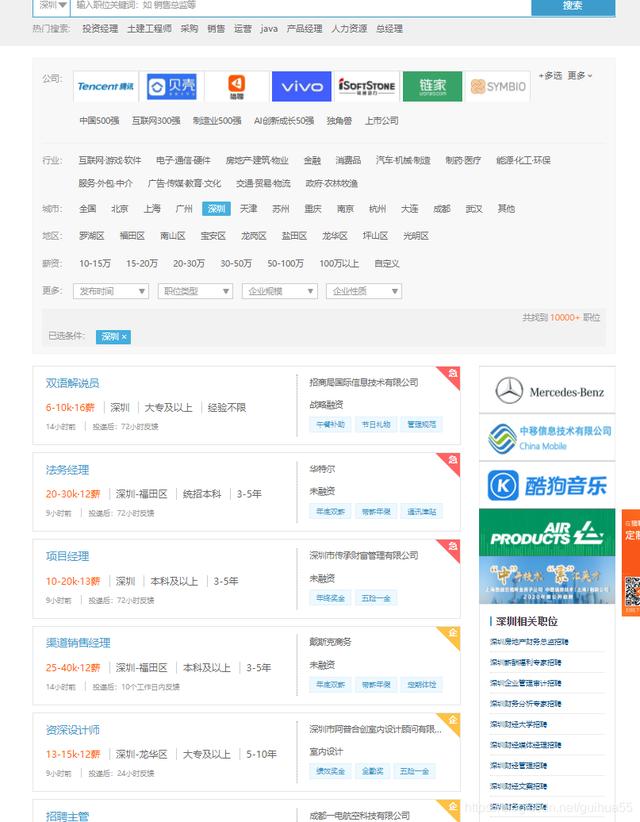 文章插图
文章插图
我们按F12进入开发者界面:
点击元素旁边的类似鼠标的按钮 , 如下: 文章插图
文章插图
然后就可以在原网页点击我们想要获取的标签 , 之后就会显示该标签对应的html代码
比如点击工作名称:双语解说员 , 然后右边就会帮我们找到对应的源代码 。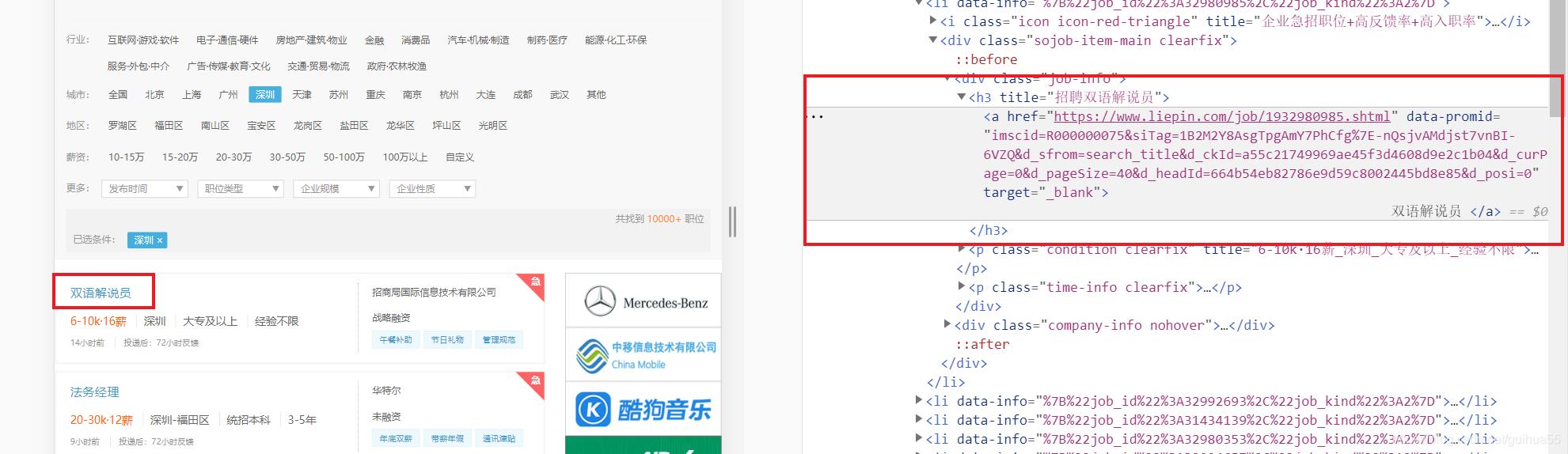 文章插图
文章插图
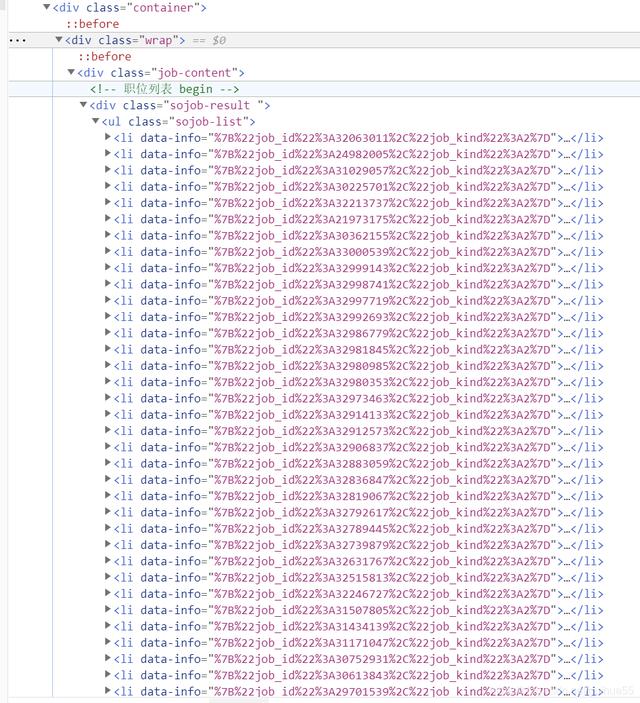
接着我们分析上下代码 , 发现该所有职位的代码都在
 文章插图
文章插图所有我们可以找到包含这些职位代码的上一个标签 , 即
 文章插图
文章插图故代码可以写成 all_job = html.find("ul", class_="sojob-list").find_all("li")
这样我们就定位到这个工作列表下 , 下面所有操作都是从这里面去查询 , 我们用一个循环遍历每个
用find方法可以让网页解析器一直查询 , 直到查到对应的标签下停止 , 这里我们可以定位到 下
该标签下就是我们要爬取的东西
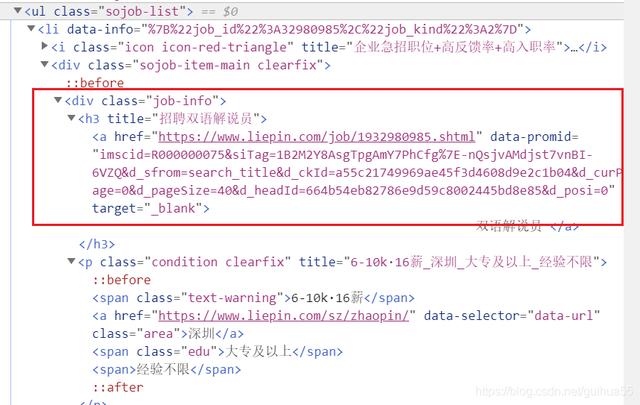 文章插图
文章插图爬取工作名实现:name = date.find("a", target="_blank").text.strip()
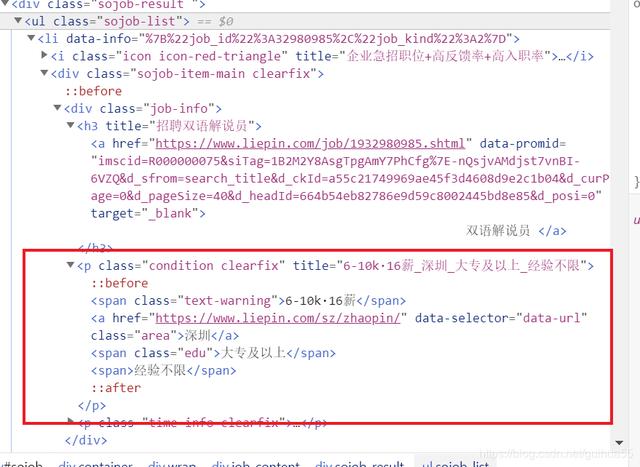
再打开标签 , 爬取地区 , 薪水 , 对应的网站 , 学历
 文章插图
文章插图因此
爬取地区实现:area = date.find("a", class_="area").text
爬取薪水实现:salary = date.find("span", class_="text-warning").text
爬取网站实现:url = date.find("a", class_="area")["href"]
爬取学历实现:edu = date.find("span", class_="edu").text
最后我们再用一个循环去让网站的url发生变化 , 也就是网站最后面的数字就是该网页的页数 , 如下:
 文章插图
文章插图最后再通过两行命令 , 将结果保存为csv文件即可
爬取结束!!
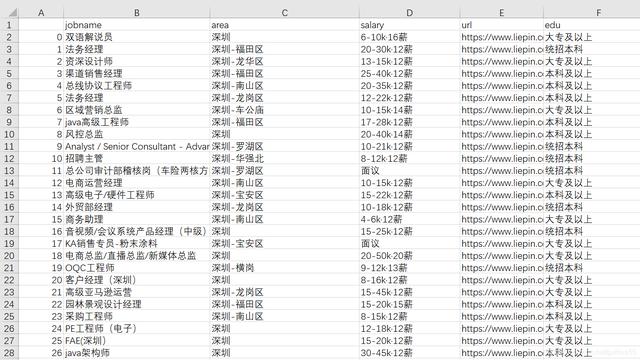
查看结果:
 文章插图
文章插图附上完整代码:
import requests
import bs4
import pandas as pd
result = {"jobname": [], # 工作名
"area": [], # 地区
"salary": [], # 薪水
"url": [], # 网址
"edu":[] #学历
}
for i in range(11):
url = ";dqs=050090 --tt-darkmode-color: #A1A4B0;"> print(url)
r = requests.get(url)
html = bs4.BeautifulSoup(r.text, "html.parser")
all_job = html.find("ul", class_="sojob-list").find_all("li")
for date in all_job:
name = date.find("a", target="_blank").text.strip()
area = date.find("a", class_="area").text
salary = date.find("span", class_="text-warning").text
url = date.find("a", class_="area")["href"]
edu = date.find("span", class_="edu").text
result["jobname"].append(name)
result["area"].append(area)
result["salary"].append(salary)
result["url"].append(url)
result["edu"].append(edu)
df = pd.DataFrame(result)
df.to_csv("shenzhen_Zhaopin.csv", encoding="utf_8_sig")
PS:如遇到解决不了问题的小伙伴可以加点击下方链接自行获取
【Python爬取网页信息并保存为CSV文件!又学了一招】python免费学习资料以及群交流解答点击即可加入
- 八大|黑五的购物网页该怎么设计?!电商UI设计八大技巧来了
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- Python中文速查表-Pandas 基础
- 零基础小白Python入门必看:通俗易懂,搞定深浅拷贝
- Python 使用摄像头监测心率!这么强吗?