再升级-Kubernetes Ingress监控进入智能时代( 二 )
- 原始访问日志存储:当Ingress Controller产生访问请求后 , 会实时将请求的访问日志推送到用户自身的Logstore中 , 整个过程的延迟一般在3-5秒即可完成 , SLS的Logstore具备高可靠、实时索引、自动扩容等功能 , 保证日志的可靠性和可扩展性 。
- 预聚和:由于原始访问日志量巨大 , 基于原始日志计算指标性能开销较大 , 因此SLS专门推出了基于访问日志的指标预聚和能力 , 能够将上百万甚至上亿的访问日志实时聚合成指标类型的时序数据 , 数据量会降低1-2个数量级 , 后续的分析与监控可直接基于时序数据进行 , 大大提高效率 。
- 智能巡检:对于预聚和后的Metrics(指标数据) , SLS提供了机器学习的自动巡检功能 , 帮助用户自动去检测各个Ingress的各个维度的指标异常 , 将异常信息实时展现在时序的图表中 , 结合实时告警能力进行自动的告警配置 。 此外后续还会支持异常打标 , 基于用户反馈的信息进行更加精确的检测 。
实时预聚和
 文章插图
文章插图Ingress的访问日志数量和用户访问成正比 , 在原始访问日志上实时计算指标的开销较大 , 一般不适合长时间的指标分析 , 并且原始日志存储的成本较高 , 一般不会将日志存储较长时间 , 但我们还是希望指标数据能够尽可能长的存储 , 这样可以在分析的时候查看更长时间的数据 。 为此SLS专门为Ingress访问日志定制了一套全托管指标实时预聚合的功能 , 能够实时将Ingress的访问日志聚合成指标并存储在SLS的时序库中 , 这样所有的监控数据查询工作都可以基于聚合后的时序数据进行 , 大大提升监控数据的查询效率 。
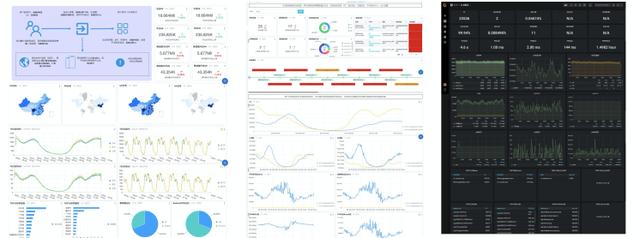
丰富可视化Ingress访问日志分析的一个重要工作是可视化系统的搭建 , 我们需要针对不同场景创建不同的报表以便满足各个方面的需求 , 例如:
- 整体大盘:包括网站当前的访问UV/PV、整体延迟、成功率等 , 这个是老板们和SRE需要看的数据 , 需要保证数据时效性和刷新的速度
- 监控大盘:能够把监控需要关注的各种数据(延迟(平均、P99/P9999等)、流量、成功率、错误码、TOP类统计)等显示在一张报表上 , 并且能够支持各种维度的过滤 , 方便定位到问题的实例 。
- 访问大盘:显示和用户相关的访问信息 , 例如PV/UV、访问的地域分布、设备分布等 , 一般情况技术Leader会关注 , 另外部分的运营同学可能也会需要这部分数据 。
- 异常大盘:显示异常巡检的指标信息 , 能够把异常的指标显示在报表上 , 方便查看 。
- 后端流量分析:快速分析后端的流量、QPS、延迟、错误率等分布信息 , 能够快速查找到“调皮”的机器 。
 文章插图
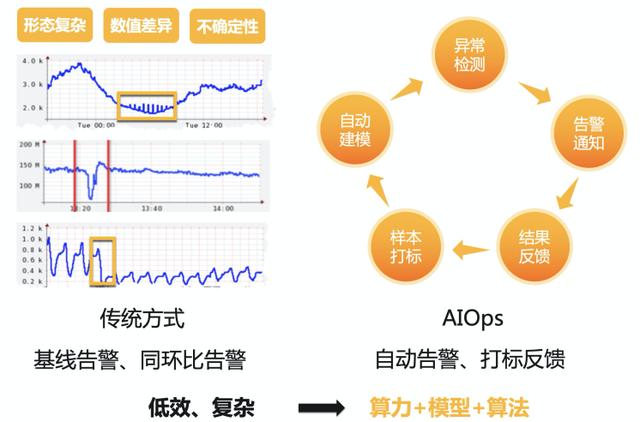
文章插图智能巡检【再升级-Kubernetes Ingress监控进入智能时代】在时序监控场景中 , 用户往往先确定监控对象 , 并通过其历史数据 , 结合业务经验 , 得到不同组的阈值参数 , 通过各种手段(同比、环比、连续触发几次等)进行监控 , 往往一个监控对象要设计4~5条监控规则 , 并配置不同的参数 。 还有更大的问题 , 各个参数阈值无法快速的复用到不同的类似观测对象中 , 当观测对象的规模达到数千 , 甚至上万后 , 传统的配置效率底下 , 无法满足在大规则时序指标数据下的监控需求 。 流式算法具有天然的优势可以解决上面的问题 , 用户只需要发起一个机器学习服务 , 模型自动拉取数据 , 实时训练 , 实时反馈(通俗地说:“来一个点 , 学习一个点 , 检测一个点”) , 在极大的降低成本的同时 , 实现对每一条线的单独建模 , 单独分析 , 单独模型参数保存 , 实现时序异常检测的“千线千面” 。
 文章插图
文章插图智能HPA
 文章插图
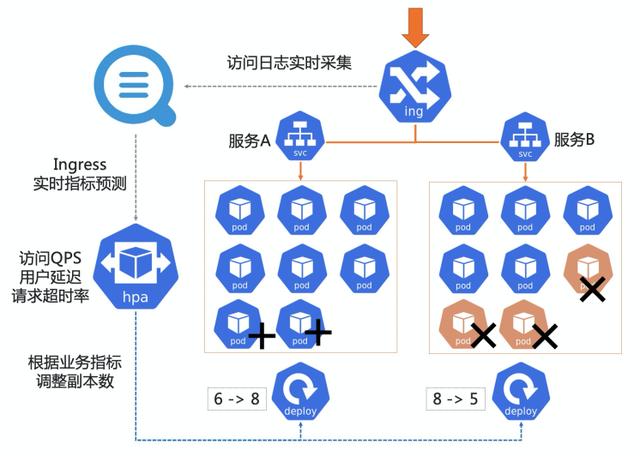
文章插图基于业务访问量的HPAHPA(Horizontal Pod Autoscaler)是Kubernetes提供的一个标准组件 , 用于POD的横向自动扩缩容 , 例如:当Pod CPU、内存等指标上升到一定程度时会自动扩容 , 当这些指标下去后会自动缩容 。 这样能够保证在用户体验不变的情况下集群整体的资源使用都能处于一个较低的位置 。 默认的HPA只能针对集群的一些标准指标(CPU、内存、网络等)进行扩容 , 这种扩容方式相对静态 , 而且反应不出业务的情况 。 因此我们对HPA进行了一些扩展 , 支持按照Ingress访问QPS进行扩容 。 即可以设置某个Service下的Pod限定能够处理的QPS , 当QPS上升到一定高度时会自动扩容一些Pod/节点 , 当QPS下降时会自动缩容一些Pod/节点 。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 体验|闭上眼睛点外卖是什么感觉?时隔一年再次体验,进步令人欣慰
- 逛逛|淘宝内容化再升级:“买家秀”变身“逛逛”试图冲破算法局限
- 再次|华为Mate40Pro干瞪眼?P50再次曝光,这次是真香!
- 打响|拼多多打响双12首枪,iPhone12降到“mini价”,苹果11再见
- 拍照|iPhone12还没捂热13就曝光了,屏幕、信号、拍照均有升级!
- 开发自|不妥协不追随 Member’s Mark升级背后的“山姆哲学”
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 品牌|为求差异化 山姆升级自有品牌Member’s Mark
- 升级|国内知名商贸市场迭代争议多,理念升级更重要