浅谈分布式共识算法raft( 二 )
请求投票都是幂等的,会检测状态 。 当收到集群超过一半的节点的RequestVote reply后,此时的follower会成为leader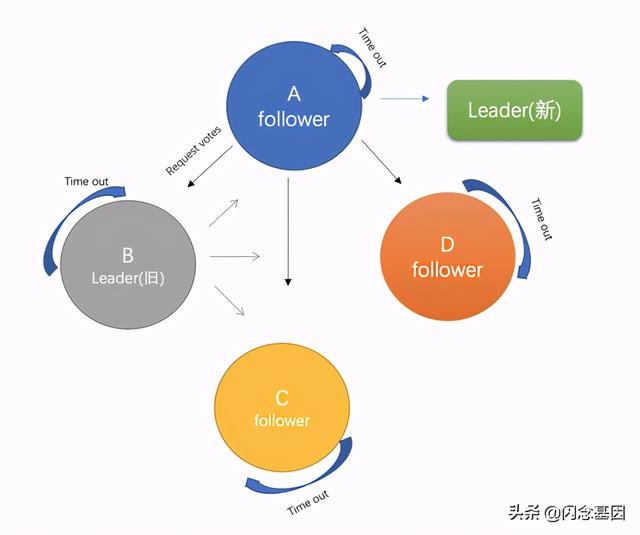 文章插图
文章插图
ps:后期leader恢复正常之后,加入到raft集群,初始化的角色是 follower, 而并非leader 。 因为任何时刻leader只有一个,如果是两个,就会发生"脑裂"问题
情形二:follower宕机follower宕机对整个集群影响不大,最多的影响是leader发出的Append Entries无法被收到,但是leader还会继续一直发送,直到follower恢复正常 。 raft会保证发送AppendEntries request的rpc消息是幂等的 , 如果follower已经接受到了消息 , 但是leader又让它再次接受 , follower会直接忽略
三:raft如何保证集群的一致性3.1:Raft 协议由leader节点负责接收客户端的请求,leader会将请求包装成log entry分发到从节点,所以集群强依赖 Leader 节点的可用性,以确保集群 数据的一致性 。 数据的流向只能从 Leader 节点向 Follower 节点转移 , 这个过程叫做日志复制( Log Replication) :
① 当 Client 向集群 Leader 节点 提交数据 后 ,Leader 节点 接收到的数据 处于 未提交状态( Uncommitted ) 。
② 接着 Leader 节点会并发地向所有 Follower 节点复制数据并等待接收响应ACK
③ leader会等待集群中至少超过一半的节点已接收到数据后 ,Leader 再向 Client 确认数据 已接收 。
④ 一旦向 Client 发出数据接收 Ack 响应后 , 表明此时 数据状态 进入 已提交( Committed ) ,Leader 节点再向 Follower 节点发通知告知该数据状态已提交
⑤ follower开始commit自己的数据,此时raft集群达到主节点和从节点的一致
3.2:在进行一致性复制的过程中,假如出现了异常情况 , raft都是如何处理的呢?1.数据到达 Leader 节点前 , 这个阶段 Leader 挂掉不影响一致性
2.数据到达 Leader 节点 , 但未复制到 Follower 节点 。 这个阶段 Leader 挂掉 , 数据属于 未提交状态 ,Client 不会收到 Ack 会认为 超时失败 可安全发起 重试 。
3.数据到达 Leader 节点 , 成功复制到 Follower 所有节点 , 但 Follower 还未向 Leader 响应接收 。 这个阶段 Leader 挂掉 , 虽然数据在 Follower 节点处于 未提交状态( Uncommitted ) , 但是 保持一致 的 。 重新选出 Leader 后可完成 数据提交 。
4.数据到达 Leader 节点 , 成功复制到 Follower 的部分节点 , 但这部分 Follower 节点还未向 Leader 响应接收 。 这个阶段 Leader 挂掉 , 数据在 Follower 节点处于 未提交状态( Uncommitted )且 不一致 。
Raft 协议要求投票只能投给拥有 最新数据 的节点 。 所以拥有最新数据的节点会被选为 Leader, 然后再 强制同步数据 到其他 Follower, 保证 数据不会丢失并 最终一致 。
5.数据到达 Leader 节点 , 成功复制到 Follower 所有或多数节点 , 数据在 Leader 处于已提交状态 , 但在 Follower 处于未提交状态 。
这个阶段 Leader 挂掉 , 重新选出 新的 Leader 后的处理流程和阶段 3 一样 。
6.数据到达 Leader 节点 , 成功复制到 Follower 所有或多数节点 , 数据在所有节点都处于已提交状态 , 但还未响应 Client 。 这个阶段 Leader 挂掉 , 集群内部数据其实已经是 一致的 ,Client 重复重试基于幂等策略对 一致性无影响 。
四:如何解决脑裂问题当raft在集群中遇见网络分区的时候,集群就会因此而相隔开,在不同的网络分区里会因为无法接收到原来的leader发出的心跳而超时选主,这样就会造成多leader现象,见下图:在网络分区1和网络分区2中 , 出现了两个leaderA和D,假设此时要更新分区2的值,因为分区2无法得到集群中的大多数节点的ACK,会复制失败 。 而网络分区1会成功,因为分区1中的节点更多,leaderA能得到大多数回应
当网络恢复的时候,集群不再是双分区,raft会有如下操作:
①: leaderD发现自己的Term小于LeaderA,会自动下台(step down)成为follower,leaderA保持不变依旧是集群中的主leader角色
②: 分区中的所有节点会回滚roll back自己的数据日志,并匹配新leader的log日志,然后实现同步提交更新自身的值 。 通知旧leaderA也会主动匹配主leader节点的最新值,并加入到follower中
③: 最终集群达到整体一致 , 集群存在唯一leader(节点A)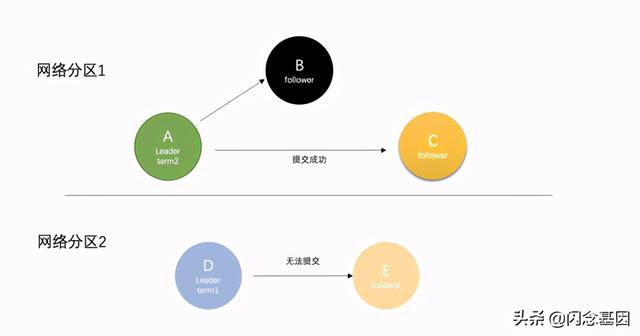 文章插图
文章插图
五:总结本篇博客从整体上讲了下raft的状态角色、如何选举出leader、如何保证一致性、以及如何处理网络分区时的脑裂问题,整理较为粗略 , raft实现起来更为复杂和细致 , 所以这里只是浅谈一下 。 理解raft的主要目的在于分布式环境中,对于集群之间的节点交互、宕机后如何处理如何保证高可用、高一致性有一定的理解 。
- 中国|浅谈5G移动通信技术的前世和今生
- 内容|浅谈内容行业的一些规律和壁垒,聊聊电商平台孵化小红书难点(外部原因)
- 浅谈如何开好一家手机维修店(六):指南舟手机维修培训学校
- 分布式锁的这三种实现90%的人都不知道
- 巨杉亮相 DTCC2019,引领分布式数据库未来发展
- Martian框架发布 3.0.3 版本,Redis分布式锁
- 为什么分布式应用程序需要依赖管理?
- 大规模分布式强化学习基础架构Menger, 大幅提高真实任务的学习效率
- 手机应用篇:浅谈手机内存卡的优劣好坏真假及应用
- 分布式云对智能化战争有何影响