Python批量爬取代理ip,并自动插入到Excel表格
思路:以“”网址为例 , 使用requests访问 , 通过xpath解析相关标签数据 , 将数据以列表的形式提取出来组成新的列表 , 然后再插入表格 。 然后再通过每页跳转时URL的变化规律进行URL重组后 , 进行循环访问爬取 。
推荐安装xpath插件 , 直接将相关标签的数据xpath路径复制即可查看变化 , 如下图: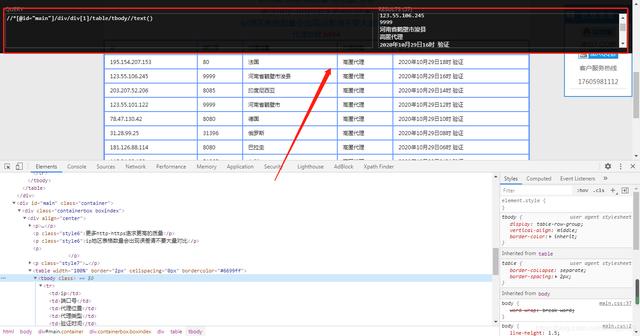 文章插图
文章插图
附上完整代码:
import requestsfrom lxml import etreeimport pandas as pdimport json#需要爬取的网址#base_url = ""#定义存放所有页面URL的列表all_urls = []#以10页为例 , 根据规律拼写每页的URL , 变化的只是数字 , 所以使用format函数来实现数字传参for i in range(1,11):create_url = '{}.html'.format(i)all_urls.append(create_url)#此处可以打印all_url查看是否成功#print(all_urls)#定义函数 , 通过xpath获取数据def get_result(data): #定义存放每一个ip列表all_xpath = []for i in range(1,12):#得到每个ip列表的 , 并追加到all_xpath列表中base_xpath = '//*[@id="main"]/div/div[1]/table//tr[{}]//text()'.format(i)#print(base_xpath)all_xpath.append(base_xpath)results = []# for循环使用enumerate , enumerate()函数将可遍历的数据对象(如:列表、元组、字典)组合为一个“索引序列” , 同时列出数据与下标for index, item inenumerate(all_xpath):res = data.xpath(item)if index == 0 or not res:continueelse:results.append(res)# print(results)return results# 每页循环爬取数据results = []for url in all_urls:response = requests.get(url)#print(url)text = response.content# print(text)data = http://kandian.youth.cn/index/etree.HTML(text)res = get_result(data)results.append(res)# 将获取的每页数据合并在一起results = sum(results, [])# 插入数据 , 并定义表格列名file = pd.DataFrame(data=results, columns=['ip', '端口号', '代理位置', '代理类型', '验证时间'])# 保存表格到本地路径 , 并命名文件名file.to_csv('全世界ip代理.csv',index=False, header=True, encoding='utf-8-sig')结果图如下: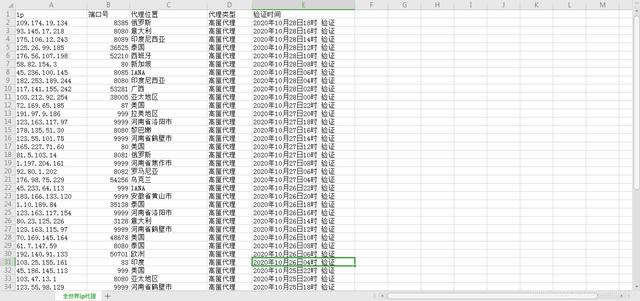 文章插图
文章插图
再也不用担心被封IP了!
【Python批量爬取代理ip,并自动插入到Excel表格】完整代码获后台私信小编01即可
- 合并|Andre Cronje主导批量「合并」DeFi项目,是好事情吗?
- 告诉|阿里大佬告诉你如何一分钟利用Python在家告别会员看电影
- Python源码阅读-基础1
- Python调用时使用*和**
- 如何基于Python实现自动化控制鼠标和键盘操作
- 解决多版本的python冲突问题
- 学习python第二弹
- Python中文速查表-Pandas 基础
- 零基础小白Python入门必看:通俗易懂,搞定深浅拷贝
- Python 使用摄像头监测心率!这么强吗?