Python|四年完成400万行Python代码检查,甚至顺手写了个编译器( 四 )
我们实现了(并在后续 PEP 当中标准化了)新的类型系统 , 旨在为某些惯用的 Python 模式提供更精确的类型 。 其中一个典型例子正是 TypeDict , 其负责提供 JSON 类字典类型 。 字典当中包含一组固定的字符串键 , 各个字符串拥有不同的值类型 。 我们后续还将不断扩展这套类型系统 , 同时考虑改进对 Python 数字堆栈的支持能力 。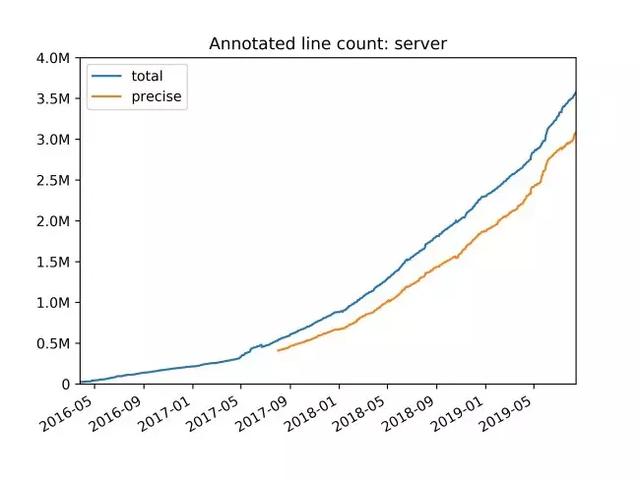 文章插图
文章插图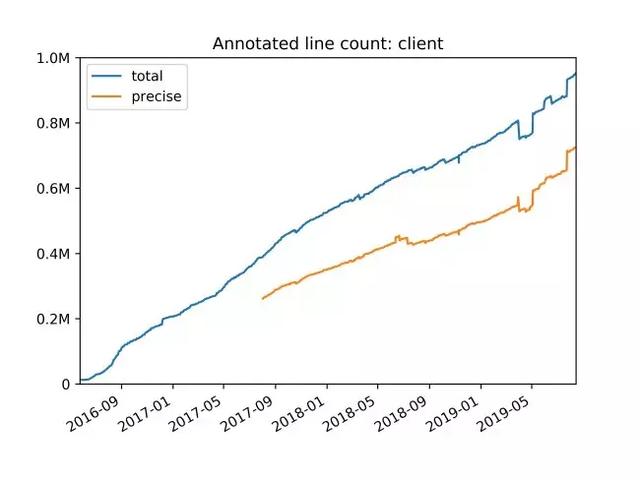 文章插图
文章插图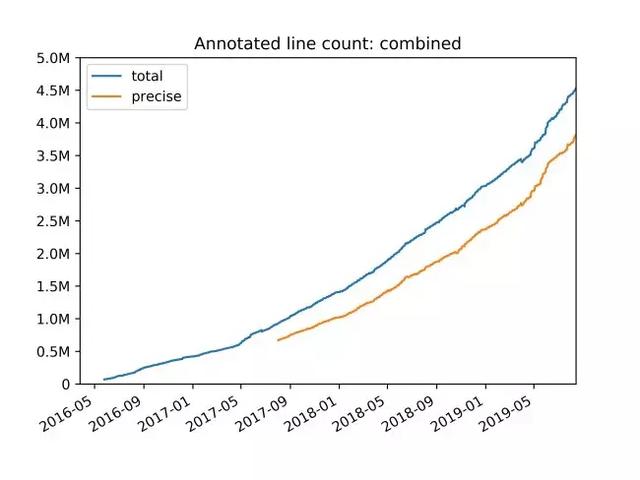 文章插图
文章插图
以下是 Dropbox 在提升注释覆盖率时 , 设定的核心工作要点:
- 严格性 。 逐渐增加了对新代码的严格要求 。 我们先从较为简单的角度入手 , 要求为原有文件补充注释 。 现在 , 我们则要求在继续补充注释的同时 , 在新的 Python 文件中使用类型注释 。
- 覆盖率报告 。 我们每周都会向各团队发送电子邮件报告 , 旨在统计他们的注释覆盖率 , 并提供关于最有必要注释的内容的相关建议 。
- 外展 。 我们与各团队就 mypy 进行交流 , 以帮助他们快速上手这款新工具 。
- 调查 。 我们定期进行用户调查以找到最重要的痛点 , 并竭尽全力解决这些问题(甚至可以发明一种新的语言来加快 mypy 的速度!) 。
- 性能 。 我们通过 mypy 守护程序与 mypyc 改进了 mypy 性能(p75 获得高达 44 倍的性能提升) , 从而减少注释流程中的阻碍 , 并允许用户根据需要扩展类型检查代码库的规模 。
- 编辑器集成 。 我们为 Dropbox 内部流行的各款编辑器提供了 mypy 运行集成 , 具体包括 PyCharm、Vim 以及 VS Code 等 。 这使得注释迭代变得更轻松 , 也提升了大家为遗留代码做注释的热情 。
- 静态分析 。 我们编写了一款利用静态分析来推断函数签名的工具 。 虽然目前它只能处理非常简单的场景 , 但仍然帮助我们快速提升了注释覆盖范围 。
- 第三方库支持 。 我们的不少代码都用到了 SQLAlchemy , 它使用的很多动态 Python 函数无法由 PEP 484 类型进行直接建模 。 为此 , 我们制作了一个 PEP 561 stub 文件包及一款开源 mypy 插件以提供支持 。
 文章插图
文章插图经验总结检查 400 万行代码绝非易事 , 我们在整个过程中遇到不少挑战 , 当然也犯过错误 。 下面 , 我想总结经验教训 , 希望能给大家带来启示 。
文件丢失 。 起步之初 , 我们的 mypy 版本只需处理少量内部文件——或者说 , 从未接触过 build 之外的一切 。 在添加第一条注释时 , 文件被隐式添加到 build 当中 。 如果从 build 外部的模块导入任何内容 , 则会获得 Any 类型的值——而这些值根本就不会被纳入检查范围 。 这导致类型分析精度大打折扣 , 并在迁移早期给我们带来了不少麻烦 。 虽然现在已经解决了 , 而且也算是一种典型做法 , 但在最糟糕的情况下 , 如果两个孤立的类型检查机制被合并起来 , 而这两种机制之间又互不兼容 , 那么我们就必须对注释进行大量更改!回想起来 , 我们应该尽早将基础库模块添加到 mypy build 中 。
注释遗留代码 。 在刚刚开始时 , 我们面对着超过 400 万行的现有 Python 代码 。 很明显 , 对如此规模的代码进行注释是项浩大的工程 。 我们编写了一款名为 PyAnnotate 的工具 , 它能够在运行测试的同时收集类型 , 并根据类型结果插入类型注释——但最终这款工具并没能得到广泛采用 。 理由很简单:收集类型的速度很慢 , 而生成的类型通常也需要大量人为调整 。 我们也考虑过在每一次 build 测试时对一小部分实时网络请求自动运行这款工具 , 但考虑到这两种方式都可能带来较大风险 , 最终只能作罢 。
大多数代码都是由代码所有者手动注释 。 我们提供关于高价值模块与函数的报告 , 以帮助简化注释流程 。 那些在数百个位置使用的库模块 , 自然是注释工作中的优先考量对象;正在被替换的遗留服务同样值得关注 。 此外 , 我们还尝试利用静态分析为遗留代码生成静态注释 。
导入周期 。 导入周期(也就是「tangle」或者说纠结周期)的存在令 mypy 提速变得非常困难 。 我们还需要努力让 mypy 支持来自导入周期的各种习惯 。 我们最近刚刚完成了一个重大项目的重新设计 , 最终解决了大多数导入周期问题 。 这些解决方案实际上源自项目早期研究中使用的 Alore 语言 。 Alore 的语法使得导入周期的处理变得更轻松 。 当然 , 我们也在这种简单的实现中继承了某些限制因素(对 Alore 来说倒不是什么问题) 。 Python 之所以很难搞定导入周期 , 是因为其语句当中可能指代多种事物 。 例如 , 赋值可能实际上定义了一个类型别名 , 而且 mypy 在大部分导入周期处理完成之后一直无法检测到该类型 。 Alore 就不存在这种模糊性 。 总之 , 有些早期设计中不经意做出的决定 , 很可能成为多年之后的痛苦根源!
- 融资|小影科技完成近4亿元C轮融资,已启动上市
- 出海|出海日报丨短视频生产服务商小影科技完成近4亿元 C 轮融资;华为成为俄罗斯在线出售智能手机的第一品牌
- 手机|新鲜评测:让手机变身电脑的显示器见过没?只用4步即可完成!
- 生产|短视频生产服务商“小影科技”完成近4亿元C轮融资
- 网络|大禹网络完成数亿元人民币A轮融资
- 海沧|厦门海沧转动卫浴行业发展引擎 今年前十个月完成工业产值62.3亿元
- 苏宁|苏宁易购旗下云网万店完成 60 亿元 A 轮融资
- 视频剪辑|提供视频剪辑工具,小影科技完成近 4 亿元 C 轮融资
- 融资|酒水外卖平台“酒小二”宣布完成A轮融资
- 运维|全栈智能业务运维服务商云智慧完成 D3 轮 6000 万美元融资