并发类的覆盖驱动测试代码生成( 三 )
搜索空间表示为一棵有根 , 有向 , 可能是无限的树 T , 其根节点是实例化对象 SOUT 的调用序列 α 。实例化包括进行构造函数调用和其他必要的方法调用 , 以设置非原始参数 。边缘代表方法调用 。 树中的每个节点代表一个调用序列 , 该调用序列对应于沿着从根到节点的路径的方法调用的有序序列 。 图 4 显示了搜索空间中代表图 1 中激励示例的四个序列 δA , δB , δC 和 δD 的部分 。
扩展序列(节点)的候选方法(CM)是 P 中的那些方法 , 使得它们具有至少一个 CUT 类型的参数 p , 可以将其绑定到共享对象 SOUT(请参阅第 2.1 节) 。 AutoConTest 通过参数值的不同组合来系统地探索节点的可能扩展 。 由 Randoop 在每次迭代中伪确定性地(使用相同的随机种子)构造原始和非原始参数值的池 。 AutoConTest 在迭代中使用不同的随机种子来实现多样性 。 结果 , 每个节点的出站边缘在每次迭代时都是相同的 , 此属性对于我们的树遍历至关重要 。
一个关键的挑战是如何有效构建可能的呼叫序列的搜索空间并比较其覆盖范围的改善 。但是 , 即使将调用序列的长度限制为给定值 , 也不可能完全构建这样的搜索空间 。为了应对这一挑战 , AutoConTest 部署了覆盖范围驱动的搜索遍历 , 该遍历可在将节点扩展到其子级之前进行预测 , 如果这些子级可以具有代表最佳调用序列 β 的后代 。 如果没有 , 这些孩子将被跳过 。通过对程序状态和每个拜访调用序列所达到的覆盖范围进行推理来进行预测 。
调用序列 δ= 的每次执行都会引发一系列状态转换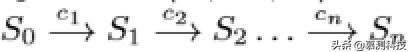 文章插图
文章插图
。 令 Si-1 表示在调用 ci 之前 ci 的参数状态 , 而 Si 表示之后的状态 。 我们假设给定状态为 Si-1 , 方法调用 ci 的顺序执行是确定的 。 在这种假设下 , 如果方法调用 cn + 1 附加在两个不同的调用的末尾 , 则会触发相同的方法调用跟踪达到相同状态 Sn 的序列 。 因此 , 如果我们已经探索了到达相同状态并具有更好覆盖范围的另一个呼叫序列的可能扩展 , 那么探索一个呼叫序列的可能扩展是多余的 。
定义 5.呼叫序列 δ 是冗余当且仅当 ?δ?∈Q , 使得 S(δ)= S(δ?)∧(?M(δ)??M(δ?)∨(?M(δ)= ? M(δ?)∧|δ? |≤|δ|)) 。
定理 1.无需探求代表冗余呼叫序列的节点的未探索后代即可获得最佳解 β 。 文章插图
文章插图
图 5 调用顺序生成算法
现在 , 我们描述调用序列生成算法(图 5)和搜索空间修剪策略(图 6) 。
我们选择使用深度优先搜索(DFS)遍历树 。 由于覆盖范围倾向于随序列长度的增加而增加 , 因此 DFS 策略可能比广度优先搜索(BFS)更快地找到更高的覆盖范围序列 。
可能存在一些可以连续扩展以提供新的非冗余序列的序列 。因此 , 如果没有明确定义的停止标准 , 该算法很容易耗尽所有可用的测试时间预算 。 一种可能的解决方案是在序列长度上施加上限 。这种方法的问题在于 , 没有一种实用的方法为给定的 CUT 选择最佳界限 。 相反 , 该算法采用基于饱和度的停止准则 。 令 δ′表示通过方法的 δ 的扩展调用序列 。 如果 δ'的最新 k 个扩展均未显示出覆盖率改善 , 则该算法将停止扩展 δ' , 但使用另一种未决方法继续扩展 δ 。如果算法在未找到可改善顺序覆盖范围的序列 β 的情况下终止 , 则会以增加的饱和度 k 重新启动 。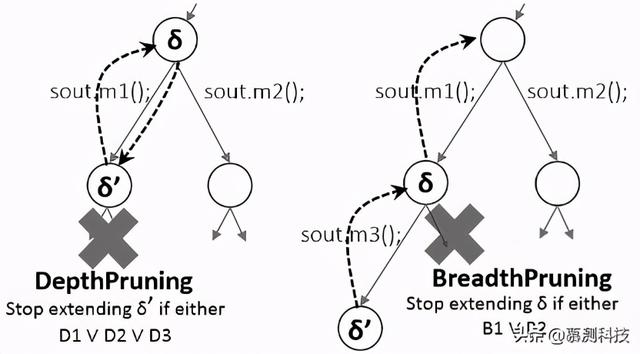 文章插图
文章插图
图 6 搜索修剪策略
收集运行时数据 。执行每个新探索的序列以收集以下信息 。
- δ.excp , 一个二进制值 , 如果执行 δ 引发捕获或未捕获的异常 , 则为真; 否则为假 。
- ?M(δ) , 通过执行被测程序的仪器版本来计算 。
- S(δ) , 执行 δ 之后对象 SOUT 的状态 。它是通过以深层复制语义序列化 SOUT 来获得的 。
广度修剪 。 该算法停止节点的“广度”访问 , 即 , 如果满足以下任一条件 , 则可以避免使用任何待处理方法扩展 δ 。 B1:| ?M(δ')|> | ?M(δ)| ∧S(δ')= S(δ) 。 B2:δ 是多余的 。 此检查类似于 D3 。
- 智能手机市场|华为再拿第一!27%的份额领跑全行业,苹果8%排在第四名!
- 会员|美容院使用会员管理软件给顾客更好的消费体验!
- 行业|现在行业内客服托管费用是怎么算的
- 人民币|天猫国际新增“服务大类”,知舟集团提醒入驻这些类目的要注意
- 国外|坐拥77件专利,打破国外的垄断,造出中国最先进的家电芯片
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 面临|“熟悉的陌生人”不该被边缘化
- 中国|浅谈5G移动通信技术的前世和今生
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面