王者荣耀五周年,带你入门Python爬虫基础操作
1.概述《王者荣耀》上线至今5个年头了 , 作为这些年国内最热门的手游(没有之一) , 除了带来游戏娱乐之外 , 我们在这五周年之际 , 试着从他们的官网找点乐趣 , 学习一下Python爬虫的一些简单基础操作 。
本篇将主要介绍简单的Python爬虫 , 包括网页分析、数据请求、数据解析和数据保存 , 适用于基本不带反爬的一些网站 , 旨在进行学习交流 , 请勿用作任何商业非法用途 。
网页分析其实就是打开你需要请求数据的网页 , 然后F12看下这个网页源数据长啥样(如果你会web知识会更好处理 , 不过我没系统学过 , 操作多了就熟悉一点);
数据请求我们用人见人爱的requests库 , 关于该库的更详细用法大家可以去查询该链接了解();
数据解析一般视请求的数据格式而定 , 如果请求的数据是html格式 , 我将介绍bs4和xpath两种方式进行解析 , 若请求的数据是json格式 , 我将介绍json和eval两种方式进行解析;
数据保存这里分为两种情况 , 如果是图片类会用到open和write函数方法 , 若是文本类的我会用到pandas的to_excel保存为表单格式 。
2.网页分析我们在概述说提到请求的数据会有html格式或者json格式 , 两种情况下其实对应的真实请求地址是有差异的 , 怎么判断呢 , 作为初学者我的个人经验就是去试试 , 本章节两种尝试方案都会介绍 , 大家在实操中视情况而选吧!
2.1.html页面源数据以下面这张英雄列表页面为例 , 按住“F12” , 然后点一下开发者模式中左上角的那个有鼠标箭头的图标 , 再在左侧选取你需要的数据区域 , 在开发者模式区域就会出现这个数据区域的数据信息 , 比如这里的“详情页地址”、“头像图片地址”和“名称” , 我们需要的也算这些信息 , 所以可以直接请求该链接即可 。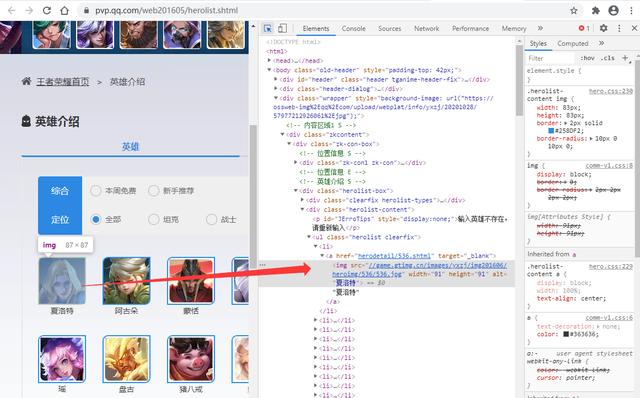 文章插图
文章插图
2.2.json源数据对于局内道具列表数据 , 我们发现上述方案无法获取 , 那么这种情况下我们可以选择开发者模式中的Network——>XHR , 然后刷新页面 , 在name里找啊找 , 一般就能到了某个数据是我们需要的 。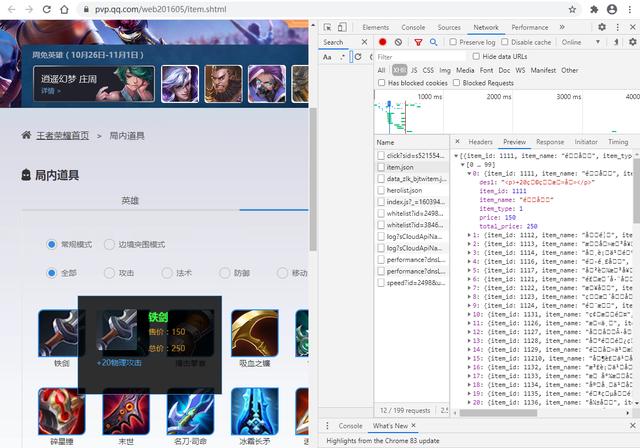 文章插图
文章插图
点Preview发现里面正是我们需要的源数据 , 然后在Headers里可以找到请求到该源数据的真实链接地址 , 这里数据请求方式为get , 我们下一节会介绍 。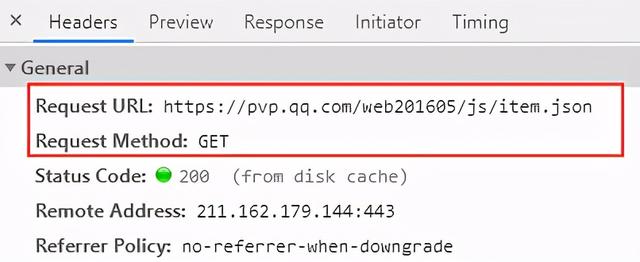 文章插图
文章插图
3.数据请求我们提到这里用 requests 库进行数据请求 , requests 有两种比较常用的请求方式:post和get 。 刚好这里我们用的到就是get一种即可 , 另外请求的时候可带很多参数 , 比如请求头、cookie等等 , 具体大家查概述中链接文档了解吧 。
简单的例子:
import requests#英雄列表页地址url = ''resp = requests.get(url)#设置解码方式(由于请求的数据中文乱码 , 这里进行解码)resp.encoding=resp.apparent_encoding 123456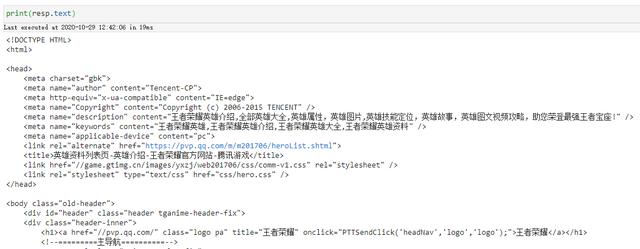 文章插图
文章插图
import requests#局内道具详情页地址url = ''resp = requests.get(url)#设置解码方式(由于请求的数据中文乱码 , 这里进行解码)resp.encoding=resp.apparent_encoding 123456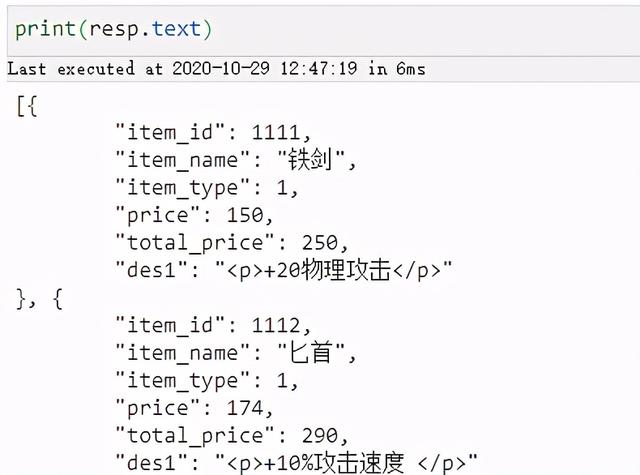 文章插图
文章插图
4.数据解析对于不同的源数据解析方式不同 , html数据解析这里介绍两种比较常用的入门级方式bs4和xpath , 对于json数据其实相对来说更好处理 , 这里介绍两种简单的方式利用json和eval 。
4.1.html数据解析4.1.1.bs4Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库 , 它能够通过你喜欢的转换器实现惯用的文档导航、查找、修改文档的方式 。
更多操作详情大家可以去看()~
看html数据结构 , 我们可以找到想要的数据在ul节点 , 满足class="herolist clearfix"下的全部li节点中 。 对于bs4来说 , 可以用find_all方法去定位 。 (更多解释见代码注释哦)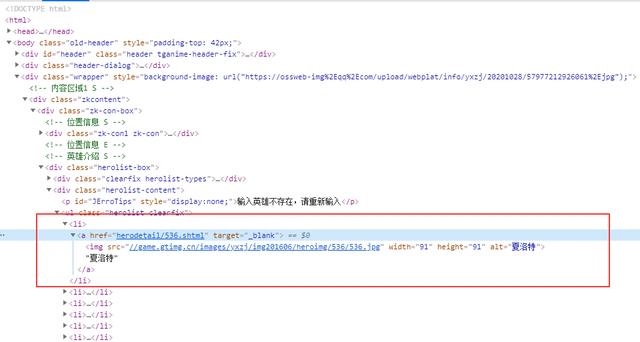 文章插图
文章插图
# bs4 解析from bs4 import BeautifulSoup# 先将请求到的数据转化为BeautifulSoup对象soup = BeautifulSoup(resp.text,'html.parser')# 定位全部的满足 class = "herolist clearfix" , 由于class是关键字所以这里用class_# 返回结果只有1个的列表 , 因此取索引0ul = soup.find_all('ul', class_="herolist clearfix")[0]# 定位 ul 下面全部的 li , li中藏着我们需要的数据信息lis = ul.find_all('li')# 创建一个空表用于存储数据herolists = []# 遍历全部的lifor li in lis: # 创建空字典 , 用于存储 英雄列表信息herolist = {}# get_text() 获取节点下面的文案部分herolist['英雄名称'] = li.get_text()# get() 获取 具体值 , 英雄详情页地址在 li节点的子节点a下面herolist['英雄详情页'] = li.find('a').get('href')herolist['英雄头像'] = li.find('a').find('img').get('src')herolists.append(herolist)123456789101112131415161718192021
- 麒麟|荣耀新款,麒麟810+4800万超清像素,你还在犹豫什么呢?
- 荣耀V30|麒麟990+40W快充,昔日猛将彻底沦为清仓价?网友:太遗憾
- 赵明|与华为“离婚”后粉丝叫啥 新任CEO赵明首发声:做自己荣耀的骑士
- 信新信息技|荣耀逐步“搬家”:官方公众号主体由 “华为终端”变为 “荣耀终端”
- 刷新率|荣耀V40系列坐实,65W快充+120Hz刷新率,但缺失麒麟旗舰芯片?
- 系列|荣耀 V40系列疯狂遭曝光!外观暗示很明显,借鉴了?
- 导航|红米note9pro和荣耀X10这样选最适合!
- 超级快充|从3899到2629元,荣耀顶级旗舰二手价,麒麟990+40W快充!
- 华为|任正非谈华为荣耀“离婚”,卸下荣耀的荣耀,还剩多少荣耀
- 红米K30S|大学生玩王者荣耀的话,红米Note 9足够吗?