从入门到掉坑:Go 内存池/对象池技术介绍(含GroupCache详解)
Go 中怎么实现内存池 , 直接用 map 可以吗?常用库里 GroupCache、BigCache 的内存池又是怎么实现的?有没有坑?对象池又是什么?想看重点的同学 , 可以直接看第 2 节 GroupCache 总结 。
0. 前言: tcmalloc 与 Go以前 C++服务上线 , 遇到性能优化一定会涉及 Google 大名鼎鼎的 tcmalloc 。
相比 glibc , tcmalloc 在多线程下有巨大的优势: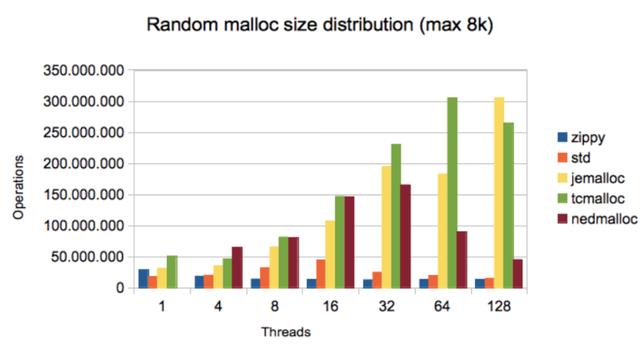 文章插图
文章插图
vs tcmalloc
其中使用的就是内存池技术 。 如果想了解 tcmalloc 的细节 , 盗一张图解 TCMalloc中比较经典的结构图: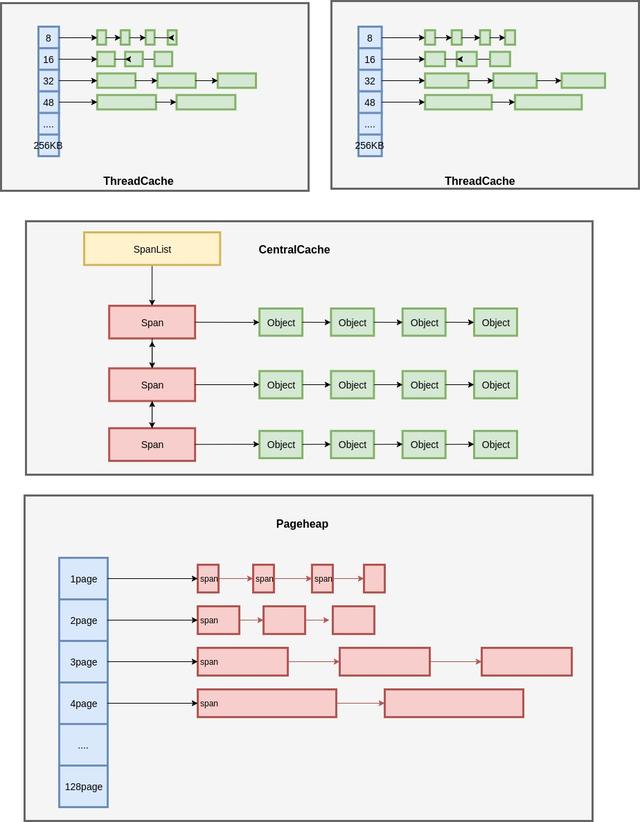 文章插图
文章插图
图解 TCMalloc
作为 Google 的得意之作 , Golang自然也用上了 tcmalloc 的内存池03 技术 。 因此我们普通使用 Golang 时 , 无需关注内存分配的性能问题 。
1. 关于 map 你需要了解的既然 Go 本身内存已经做了 tcmalloc 的管理 , 那实现缓存我们能想到的就是 map 了 , 是吧?(但仔细想想 , map 不需要加锁吗?不加锁用 sync.Map 更好吗)
坑 1: 为什么不用 sync.Map2020-05-09 补充:多位同学也提到了 , bigcache 这个测试并不公平 。 查了下 issues , map+lock 和 sync.Map 的有人做过测试 , 性能确实低一些(单锁的情况)#issuecomment-441737879
但如果是 shards map+lock 和 sync.Map , 在不同的读写比(比如读多写少 , 当超时才更新)时 , 这块就不好判断哪种实现更优了 , 有兴趣的同学可以尝试深挖下(而且 doyenli 也提到 , sync.Map 内部是 append only 的)
用过 map 的同学应该会知道 , map 并不是线程安全的 。 多个协程同步更新 map 时 , 会有概率导致程序 core 掉 。
那我们为什么不用sync.Map?当然不是因为 go 版本太老不支持这种肤浅原因 。
里有张对比数据 , 纯写 map 是比 sync.Map 要快很多 , 读也有一定优势 。 考虑到多数场景下读多写少 , 我们只需对 map 加个读写锁 , 异步写的问题就搞定了(还不损失太多性能) 。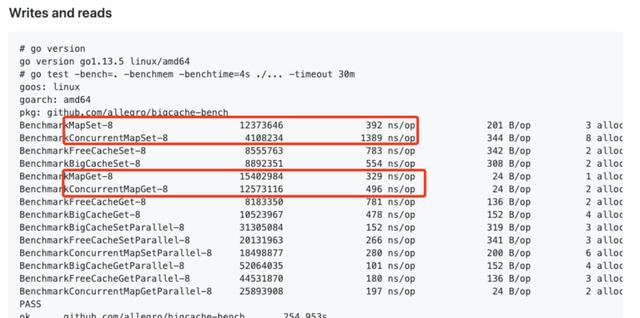 文章插图
文章插图
map vs sync.Map
除了读写锁 , 我们还可以使用 shard map 的分布式锁来继续提高并发(后面 bigcache 部分会介绍) , 所以你看最终的 cache 库里 , 大家都没用 sync.Map , 而是用map+读写锁来实现存储 。
坑 2: 用 map 做内存池就可以了?并不能 。 map 存储 keys 也是有限制的 , 当 map 中 keys 数量超过千万级 , 有可能造成性能瓶颈 。
这个是我在之前业务中实际遇到的情况 , 当时服务里用了 GroupCache 做缓存 , 导致部分线上请求会超时(0.08%左右的超时率) 。 我们先暂时放下这个问题 , 弄清原因再来介绍这里的差异 。
找了下资料 , 发现 2014 年 Go 有个 issue 提到 Large maps cause significant GC pauses 的问题 。 简单来说就是当 map 中存在大量 keys 时 , GC 扫描 map 产生的停顿将不能忽略 。
好消息是 2015 年 Go 开发者已经对 map 中无指针的情况进行了优化: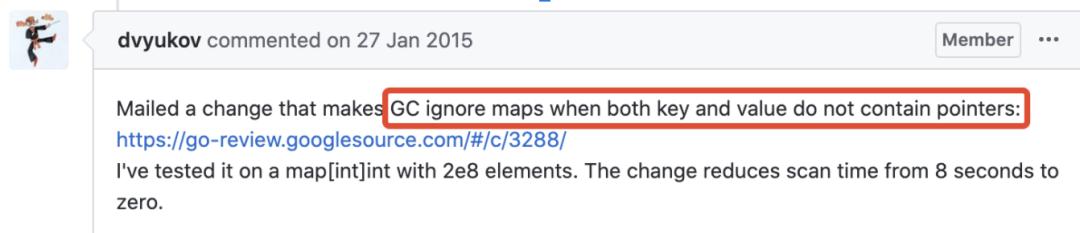 文章插图
文章插图
GC ignore maps with no pointers
我们参考其中的代码 , 写个GC 测试程序验证下:
package mainimport ("fmt""os""runtime""time")// Results of this program on my machine://// for t in 1 2 3 4 5; do go run maps.go $t; done//// Higher parallelism does help, to some extent://// for t in 1 2 3 4 5; do GOMAXPROCS=8 go run maps.go $t; done//// Output(go 1.14):// With map[int32]*int32, GC took 456.159324ms// With map[int32]int32, GC took 10.644116ms// With map shards ([]map[int32]*int32), GC took 383.296446ms// With map shards ([]map[int32]int32), GC took 1.023655ms// With a plain slice ([]main.t), GC took 172.776μsfunc main() {const N = 5e7 // 5000wif len(os.Args) != 2 {fmt.Printf("usage: %s [1 2 3 4]\n(number selects the test)\n", os.Args[0])return}switch os.Args[1] {case "1":// Big map with a pointer in the valuem := make(map[int32]*int32)for i := 0; i < N; i++ {n := int32(i)m[n] =i < N; i++ {n := int32(i)m[n] = n}runtime.GC()fmt.Printf("With %T, GC took %s\n", m, timeGC())_ = m[0]case "3":// Split the map into 100 shardsshards := make([]map[int32]*int32, 100)for i := range shards {shards[i] = make(map[int32]*int32)}for i := 0; i < N; i++ {n := int32(i)shards[i%100][n] =i < N; i++ {n := int32(i)shards[i%100][n] = n}runtime.GC()fmt.Printf("With map shards (%T), GC took %s\n", shards, timeGC())_ = shards[0][0]case "5":// A slice, just for comparison to show that// merely holding onto millions of int32s is fine// if they're in a slice.type t struct {p, q int32}var s []tfor i := 0; i < N; i++ {n := int32(i)s = append(s, t{n, n})}runtime.GC()fmt.Printf("With a plain slice (%T), GC took %s\n", s, timeGC())_ = s[0]}}func timeGC() time.Duration {start := time.Now()runtime.GC()return time.Since(start)}
- 王文鉴|从工人到千亿掌门人,征服华为三星,只因他36年只坚持做一件事
- 手机|这个超强App,让手机快3倍,流畅到起飞
- 巅峰|realme巅峰之作:120Hz+陶瓷机身+5000mAh 做到了颜值与性能并存
- 现货供应|卢伟冰说到做到!120Hz+一亿像素,狂销30万首销现货供应
- 精英|业务流程图怎么绘制?销售精英的经验之谈
- 打响|拼多多打响双12首枪,iPhone12降到“mini价”,苹果11再见
- 深度|iPhone12到底值得买吗 深度体验一周我发现了这些
- 不到|苹果赚了多少?iPhone12成本不到2500元,华为和小米的利润呢?
- 走向|电商,从货架陈列走向内容驱动
- 星期一|亚马逊:黑五与网络星期一期间 第三方卖家销售额达到48亿美元