63种机器学习算法
数据科学和分析正在改变业务 。它已渗透到财务 , 市场营销 , 运营 , 人力资源 , 设计等各个部门 。 对于B学校学生来说 , 掌握分析技能并精通机器学习和统计学正变得越来越重要 。数据被称为新黄金 。未来一段时间内发展最快的公司将是最能充分利用其收集的数据的公司 。就像通过数据的力量一样 , 企业可以进行有针对性的营销 , 从而改变他们转换销售和满足需求的方式 。
但是有一个问题 , 机器学习是复杂的 , 对于刚进入该领域的人来说 , 这是第一次在B学校中学习它 , 似乎很难将这些概念与繁忙的日程一起掌握 。以前没有编码经验的B-school学生 , 机器学习很困难 , 一个人会迷失在监督学习与无监督学习的所有不同算法和分支中 。它们背后的数学很难理解并且学习曲线陡峭 。对于开始 , python或R本身似乎是一个波涛汹涌的大海 , 需要一些专门的实践 。但是 , 对于业务经理而言 , 掌握这些知识至关重要 。新一代的MBA正在学习它 , 而较老的一代应该学习它 。
我的博客系列旨在以简单易懂的方式解释这些算法 , 以便具有python基本知识的人可以实现它们 , 并从他们的生活和业务中受益 。
因此 , 我决定放弃数学 , 直接研究该算法的工作原理 , 为什么与众不同以及为什么作为商人我应该为它们而烦恼 。在本文中 , 我将解释大约11个机器学习分支 , 并简要介绍每个分支 。在接下来的文章中 , 我们将研究每个节点的详细说明 , 它们之间的差异以及每个节点的用例 。
什么是机器学习?机器学习是计算机科学的一个子领域 , 它使"计算机无需明确编程即可学习 。 " ?亚瑟·塞缪尔
就是Netflix告诉您接下来要看这部电影 , Spotify会在不触摸手机的情况下播放出色的歌曲 , 它是手机的键盘 , 这就是他们预测明年销量的方式 。机器学习最简单的形式是从数据中学习 , 然后将其预测或分成有意义的部分 , 以更容易使用的方式理解它 。
您的计算机可以使用在数学和统计上起作用的算法来执行所需的功能 , 从数据中学习 。算法找到并应用模式到数据 , 他们试图在应用某种模式的同时最大程度地减少预测准确性的损失 , 然后它们将可以从数据中学到的最佳模式反馈给我们 。
如果您告诉您的算法每个数据点意味着什么 , 那么它叫做监督学习算法 , 而如果您不给出任何标签 , 则算法会尝试自行查找模式 , 这被称为无监督机器学习 。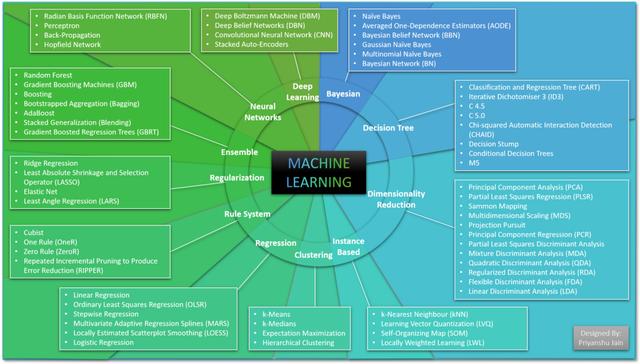 文章插图
文章插图
> 63 Machine Learning Algorithms
11个分支基于基础的数学模型 , 机器学习算法可以分为11个分支:
· 贝叶斯(Bayesian)-贝叶斯机器学习模型基于贝叶斯定理(Bayes theorem) , 它只不过是在知道发生其他事情的情况下计算发生某件事的概率 , 例如 Yuvraj(板球运动员)知道他今天吃了咖喱饭的概率达到了六分之六 。我们使用机器学习在数据上应用贝叶斯统计 , 并且在这些算法中我们假设自变量存在一定的独立性 。这些模型从对数据的某种信念开始 , 然后这些模型根据数据更新该信念 。就像我在使用Naive Bayes分类器的Twitter项目中所做的那样 , 贝叶斯统计在分类中有多种应用 。同样 , 在业务中 , 根据其他营销策略的数据点和历史参数来计算某些营销计划成功的概率 。
· 决策树-顾名思义 , 决策树用于使用树进行决策 。它使用估计和概率来计算可能的结果 。树的结构具有根节点 , 该根节点分为内部节点 , 然后叶子 。这些节点上是数据分类变量 。我们的模型从标记的数据中学习 , 并找到最佳的变量来分割我们的数据 , 以最大程度地减少分类错误 。它可以为我们提供分类数据 , 甚至可以根据从训练数据中获得的知识为我们的数据点预测价值 。决策树用于期权定价 , 市场营销和业务计划的财务中 , 以找到最佳方案或各种可能性对业务的整体影响 。
· 降维—想象一下 , 您拥有的数据具有1000个功能 , 或者您进行了包含25个问题的调查 , 现在很难理解哪个问题在回答什么 。这就是降维算法系列的用武之地 。顾名思义 , 它们可以帮助我们减少数据的维数 , 从而减少模型的过度拟合并减少训练集的高方差 , 以便我们可以对测试集做出更好的预测 。在市场研究调查中 , 通常将问题归类为主题 , 然后可以很容易地理解它们 。
· 基于实例-这种受监督的机器学习算法在将当前实例与存储在内存中的先前训练过的实例进行比较之后 , 执行操作 。该算法称为基于实例的算法 , 因为它使用的是使用训练数据创建的实例 。k最近邻居就是这样一个例子 , 其中邻居的新位置始终根据我们想要的数据点邻居数来更新 , 并且使用邻居的先前实例及其存储在内存中的位置来完成 。网站向我们推荐使用这些基于实例的算法以及更多疯狂算法的新产品或电影 。
- 机器人|网络里面的假消息忽悠了非常多的小喷子和小机器人
- 跑腿|机器人“小北”上岗 让办事群众少跑腿
- 计算机学科|机器视觉系统是什么
- 机器人|外骨骼康复训练机器人助力下肢运动功能障碍患者康复训练
- 教学|机器人教学的目标方案
- 体验|VR\/AR体验、3D打印、机器人“对决”……松江这所中学人工智能创新实验室真的赞
- 输送|新时达:“用于机器人码垛的输送系统”获发明专利
- 操作|[LIVE On]黄敏贤和郑多彬充满心碎的下午:机器操作每次都不能通过测试
- 用于|用于半监督学习的图随机神经网络
- 顶级|内地高校凭磁性球体机器人首获机器人顶级会议最佳论文奖