如何生成全局的分布式ID
现在的系统中 , 很多系统都不是单体的了 , 都是以集群的方式部署的 。 系统也是分布式的了 。 我们很多场景都需要生成全局的ID 。 比如我们将数据库进行分库分表后 , 就需要全局的不重复的主键ID 。 比如在一些业务中 , 我们需要给用户生成不重复的编号(这里不是数据库的主键ID) , 如1000 , 1001 , 1002... 。 那么我们如何生成全局的ID呢?
使用Redis的原子性生成我们可以利用Redis单线程的性质去做原子运算 , 能够实现多程安全 。 使用org.redisson的api 。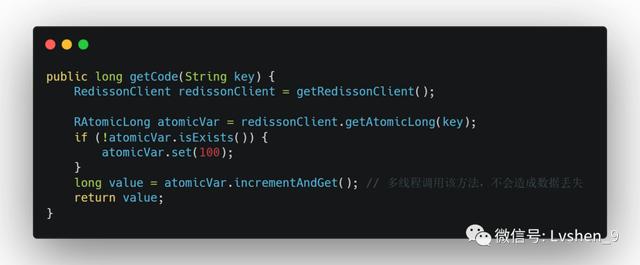 文章插图
文章插图
如上代码 , 我们设置初始值为100 , 每次调用该方法 , 就在该值上加1 。 这样就生成不重复的值了 。
调用代码: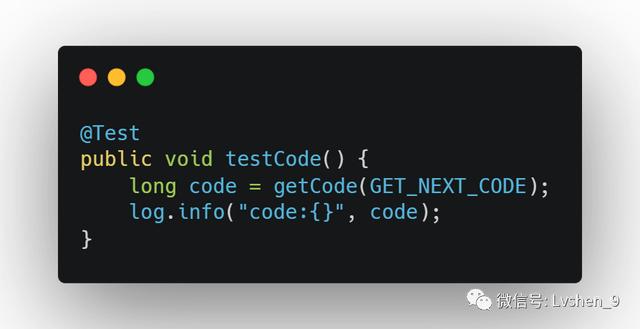 文章插图
文章插图
测试结果:
code:101我们再调用一次:
code:102Redis中的存储如下图: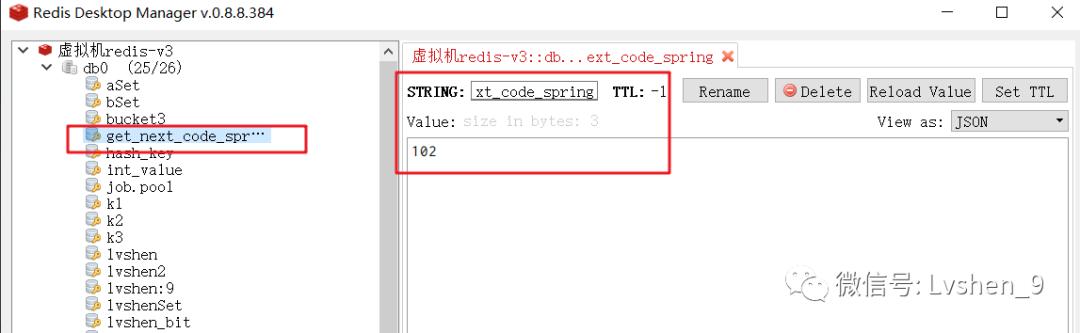 文章插图
文章插图
采用Twitter的SnowFlake 算法生成SnowFlake 算法是Twitter开源的分布式ID生成算法 。 我们可以用来生成主键ID 。 核心主要是通过ip + 端口 + 时间戳来生成 , 所以生成的ID是随系统时间递增的 。
核心算法如下: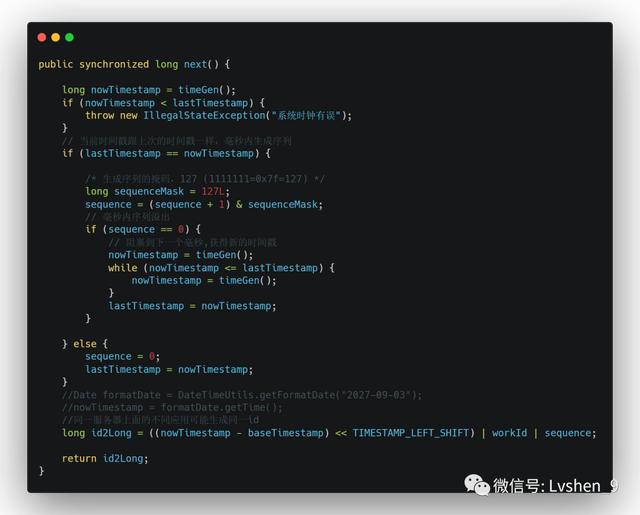 文章插图
文章插图
使用示列: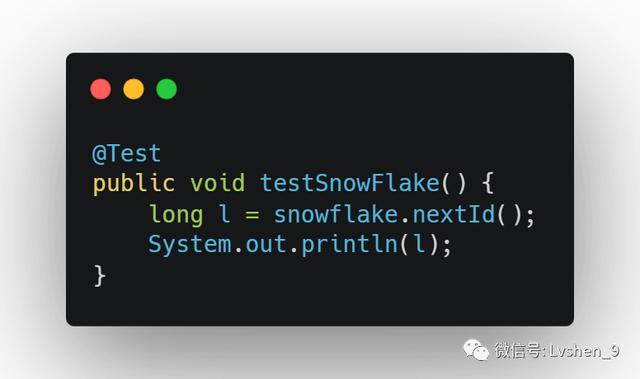 文章插图
文章插图
为了保证生成器唯一 , 我们需要获取生成器的单列对象 。 比如可以使用Spring的IoC容器管理 。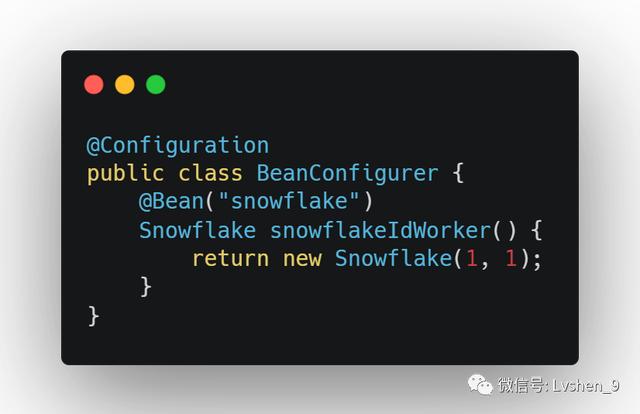 文章插图
文章插图
如上代码 , 我们注册成单列Bean 。 使用的时候直接@Autowired获取单列对象 。
@Autowiredprivate Snowflake snowflake;生成结果:
1320304557686919168这个算法还是比较常用的 。 比如百度开源的uid-generator算法 , 美团的Leaf算法 , 有兴趣的可以去网上了解下 。
使用UUID生成我们可以使用UUID生成全局唯一的ID 。 但是千万不要用于做数据库(如MySQL)的主键ID , 这样会使主键索引的维护更为复杂 。
测试代码如下: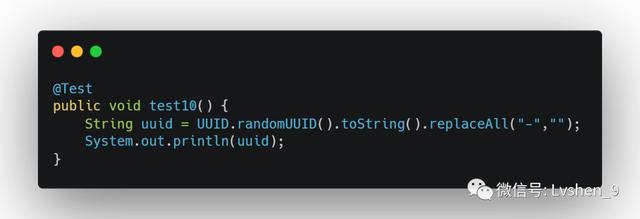 文章插图
文章插图
测试结果:
7509621c028c40378b7a79c8e85d49a7使用数据库生成自增的ID基于数据库的auto_increment自增ID完全可以充当分布式ID , 这个是我们常用的方法 。 先创建一张生成ID的表 , 每次需要生成ID的时候往ID表里面插入一条数据 , 获取其主键ID即可 。 但是这种生成方式在高并发下面并不适用 。 这里不做细讲 。
Tinyid“
Tinyid是滴滴开发的一款分布式ID系统 , Tinyid是在美团(Leaf)的leaf-segment算法基础上升级而来 , 不仅支持了数据库多主节点模式 , 还提供了tinyid-client客户端的接入方式 , 使用起来更加方便 。 但和美团(Leaf)不同的是 , Tinyid只支持号段一种模式不支持雪花模式 。
【如何生成全局的分布式ID】”
有兴趣的可以看看github的源码:
“
Github地址:
”
当然还有很多ID的生成方式 , 其实我觉得Redis和SnowFlake算法生成就已经够用了 。
那么今天的文章就到这里就结束了 。 谢谢阅读!
- 页面|如何简单、快速制作流程图?上班族的画图技巧get
- 培育|跨境电商人才如何培育,长沙有“谱”了
- 抖音小店|抖音进军电商,短视频的商业模式与变现,创业者该如何抓住机遇?
- 计费|5G是如何计费的?
- 车轮旋转|牵引力控制系统是如何工作的?它有什么作用?
- 视频|短视频如何在前3秒吸引用户眼球?
- Vlog|中国Vlog|中国基建如何升级?看5G+智慧工地
- 涡轮|看法米特涡轮流量计如何让你得心应手
- 手机|OPPO手机该如何截屏?四种最简单的方法已汇总!
- 和谐|人民日报海外版今日聚焦云南西双版纳 看科技如何助力人象和谐