FIBO词汇表|知识图谱改变银行业务模式?基于GraphDB探索FIBO
译者:AI研习社(季一帆)
文章插图
简介
FIBO概况
122个命名空间,表示模块结构;
1542类别
1328概念
535断言
自2017年首次发布FIBO以来,受益于金融业的广泛参与,该标准已取得广大发展,并符合许多现有标准。从一个称为“语义知识库”的Excel工作簿开始,FIBO已经发展成为基于RDF和OWL的复杂本体。在这个过程中,还发展了其他一些意外成果,包括本体工程的实践指南,例如使用传统基于文本的版本控制系统的RDF文本稳定性,通过与对象管理组(OMG)的密切关系实现严格的元数据标准,以及对OWL推理能力的使用。更多细节可见此处。
FIBO的内容多种多样,其中,RDF和OWL本体是包含业务知识的核心实体。这些业务知识可表示为RDF-XML、Turtle、JSON-LD和N-Quads/N-Triples等形式。此外:
【 FIBO词汇表|知识图谱改变银行业务模式?基于GraphDB探索FIBO】FIBO词汇表基于SKOS分类法,用于RDF-XML、Turtle和JSON-LD序列化的分类管理。
FIBO数据字典有.csv和.xlsx格式,包含FIBO中的操作类及其附带属性。
FIBO-DM是一种企业数据模型,可用作SAP PowerDesigner概念和逻辑数据模型。
在本文中,我们重点关注FIBO本体和词汇表。由于它们都使用RDF编码,因此可使用SPARQL和OWL推理进行分析。
两不同层次结构
FIBO词汇表中的所有概念都是由FIBO本体中的实体定义的。因此,这些概念包含有丰富的上下文信息,在应用中使用该词汇表会同时为用户提供这些信息。如,fibo-v-be:DomesticUltimateParent 由实体fibo-be-oac-cctl:DomesticUltimateParent所定义。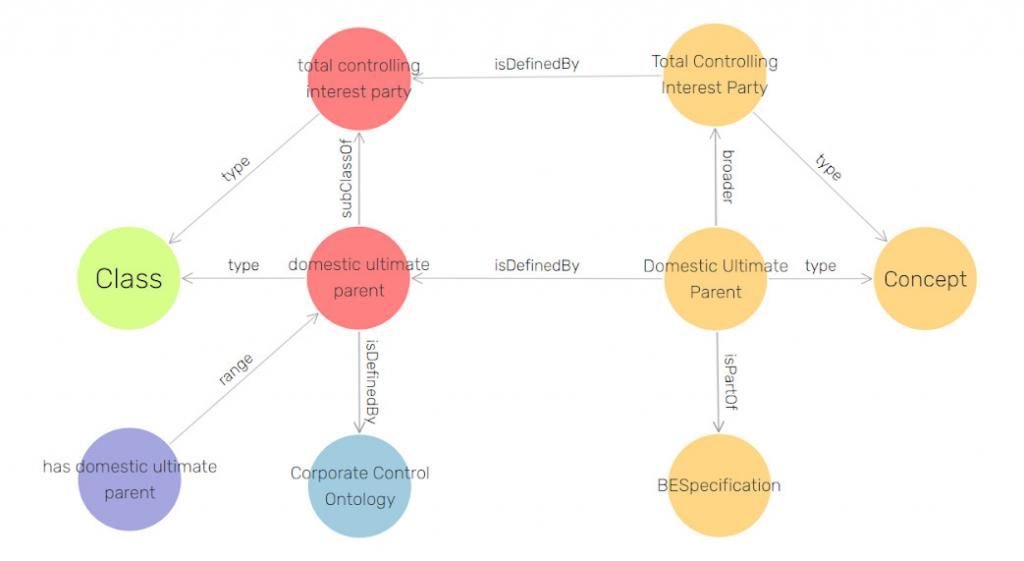
文章插图
FIBO词汇表中的概念由 skos:broader和skos:narrower两种不同层次的谓词进行定义。在上图中,Total Controlling Interest Party 是比 Domestic Ultimate Parent 更为宽泛的概念。在已公布的词汇表中,仅使用了skos:broader。如 SKOS 规范所述,“skos:broader 和 skos:narrower彼此相反。当概念X比概念Y表示更广泛时,意味着Y相对是X是更小、更准确的概念“。因此,从fibo-v-be:TotalControllingInterestParty 到fibo-v-be:DomesticUltimateParent存在skos:narrower的关系。
如果给定词汇表的层次结构和本体的层次结构,那么层次结构之间的关系是什么呢?fibo-be-oac-cctl:DomesticUltimateParent的每一个父类在词汇中都有对应概念吗?这些概念是否表达了skos:broaderTransitive/skos:narrowerTransitive与fibo-v-be:DomesticUltimateParent的层次结构?在本文的其余部分,我们将借助GraphDB解答这些问题。
FIBO导入GraphDB
GraphDB是Ontotext开发的一个可扩展、高性能的三元组数据库,其前身是OWLIM。当前的9.4.1版本支持RDF1.1、SPARQL 1.1和OWL2推理,此外还支持其他许多用于索引、可视化、分析和联合工具。同时,还提供有web访问的API(包括用于终端的SPARQL协议),因此可以结合任何编程语言使用。在下一节会展示该数据库对SPARQL1.1,OWL2推理及其规范属性路径的支持。
首先通过GraphDB创建一个存储库,通过导航窗口Setup -> Repositories > Create Repository 等步骤实现。其中,表单关键字包括:
Repository ID,本例中是FIBO。
Ruleset,本例中选择下拉菜单中的OWL 2-RL (Optimized)。
选中“Use context index”,因为FIBO本体包含反映本体模块结构的命名图。
其余字段使用默认值即可,以下为屏幕截图: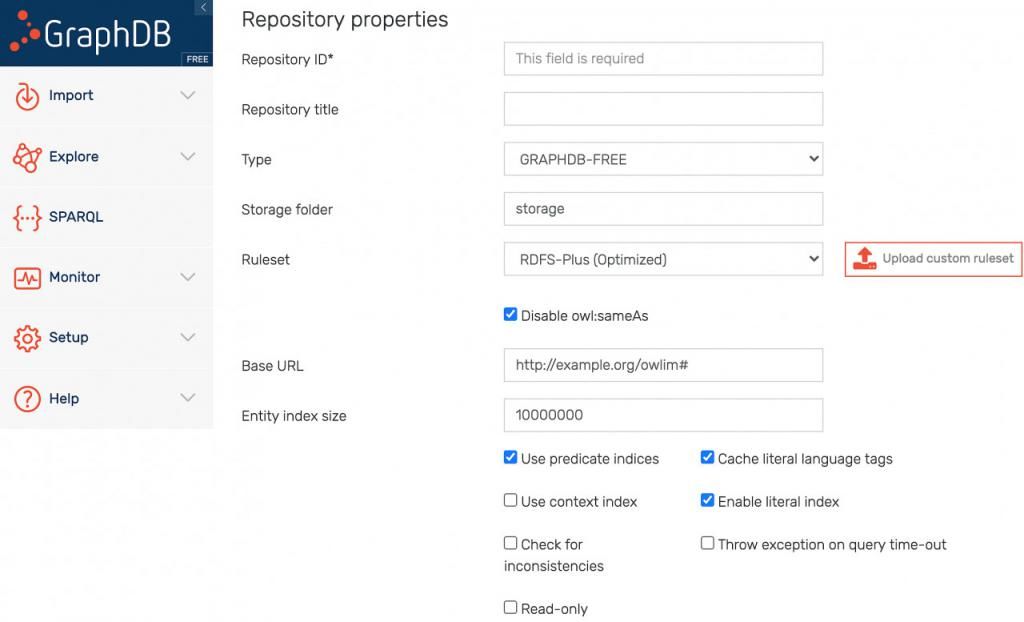
文章插图
接下来导入RDF图,有以下要求:
为了提高效率,最好将FIBO下载到本地磁盘,存储到GraphDB的import目录,而SKOS直接通过internet下载。
从磁盘导入词汇表需要1秒,导入本体需要1分10秒,通过互联网导入sko需要2秒。之所以速度相差之大,是因为在导入过程中要执行推断操作。词汇表基于开放SKOS,借助生成新三元组的结构元素,词汇表和SKOS的导入训练。而由于在本体构建过程中OWL的复杂性,消耗了较长时间。最终,导入图谱的106187条显式语句生成405493条推断语句,总计511680条语句。需要注意的是,所有推断语句存在于默认图,同时该图还包含命名图中的所有语句。
使用GraphDB Workbench的Explore菜单中的类层次结构图能够获得本体概述,该图将子类表示为嵌套在父类中的圆: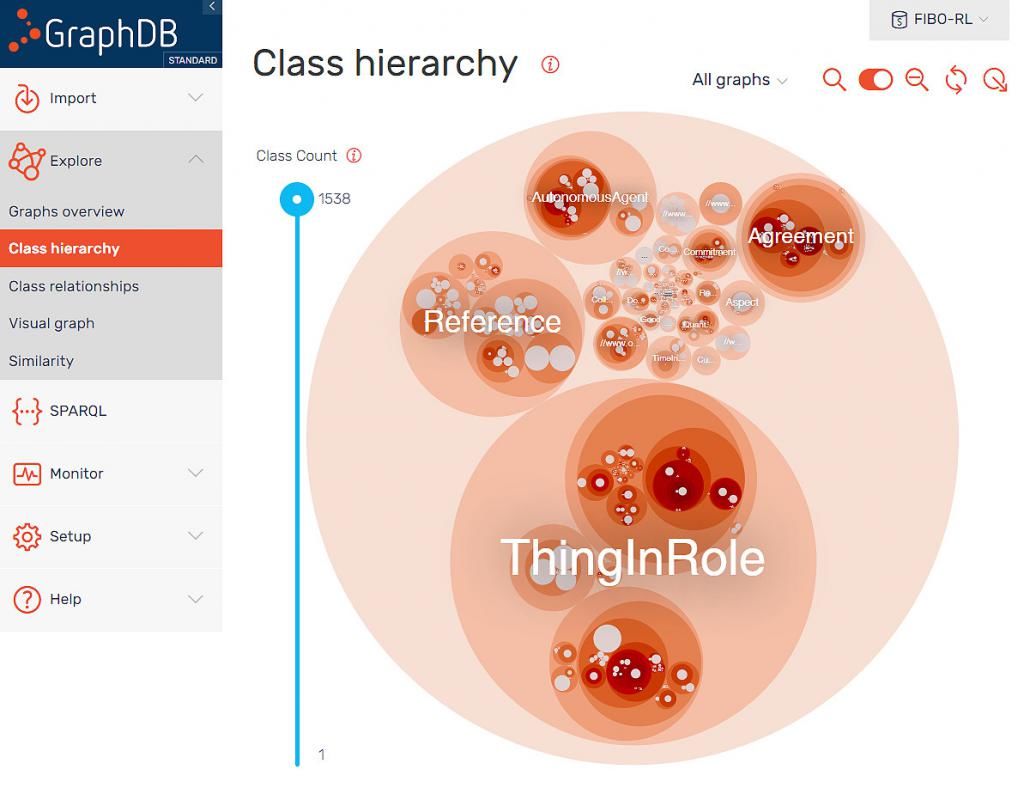
文章插图
GraphDB中的推理
OWL 2支持许多不同的推理机制,GraphDB为其中的一些程序语言配置文件提供支持。在GraphDB中,存储相关的语言配置文件由规则集合确定。无论是通过SPARQL插入数据还是直接导入图谱,只要将三元组添加到知识库中,就会调用专门的规则引擎——reasoner。除非不进行推理操作,否则任何规则集都通过额外的隐式三元组实现并存储,而不是显式插入的三元组。GraphDB的特殊指出在于,提交SPARQL DELETE操作后,将回收无效的推断语句。此外,存储内容和选定规则集决定了新建三元组的属性。例如,如果两个谓词的定义表明它们是相反的,那么当其中一个谓词出现在一个三元组时,将创建一个相应逆属性的三元组。
- 快递|国家邮政局:推动邮政快递行业由劳动密集型向知识密集型发展
- 手机|原来微信一键就能拼接长图,朋友圈可发送几十张照片,涨知识了
- 双行合一|关于Word我们要了解的知识(12)
- 经济总量|美国经济总量世界第一,究竟是靠哪些产业支撑的呢?看完长知识了
- 电脑知识|北大青鸟:零基础学电脑从哪里入手
- 打击|莫让知识产权侵权“打击”了家电行业的创新积极性
- 为什么手机大厂们都喜欢搞子品牌?看完算长知识了
- 今天才发现,微信长按2秒,还有6个隐藏功能,涨知识了
- 学习大数据需要具备哪些基础知识,以及应该重视哪些环节
- 又爆新作!阿里甩出架构师进阶必备神仙笔记,底层知识全梳理