博客|Netflix 技术博客:区分优先级的负载分流,保持服务的稳定可靠
神译局是36氪旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。
编者按:作为一个为会员提供娱乐内容的流媒体服务商,服务的稳定和流畅至关重要。但是,一旦基础设施出现中断,服务可能就会受到巨大影响。就算服务不会完全中断,但因为不断涌入的请求会将少数可用资源压垮,最终服务也会很快变得不可用。如何才能在恢复系统的同时尽量保障服务的不中断?Netflix技术团队在其官方技术博客上分享了他们的实践。原文作者Manuel Correa、Arthur Gonigberg与Daniel West。标题是:Keeping Netflix Reliable Using Prioritized Load Shedding
文章插图
对于全世界的司机来说,堵车应该是最令人沮丧的经历之一了。每一辆车都慢得像蜗牛一样,有时是因为一个小问题,有时候根本就不知道怎么回事。作为Netflix的工程师,对于如何去重新设计我们的流量管理,我们一直在不断地进行评估。如果我们知道每一位旅客的紧迫性,并且可以有选择地引导汽车通过,而不是让所有人都要一起等待的话,会怎样呢?
对于Netflix的工程设计来说,我们的驱动力是在你需要的时候确保Netflix就在那里。不过,直到去年之前,我们的系统还是容易受到所谓的“交通拥堵”的影响。我们有简单粗暴的开/关断路器,但是没有逐步的负载分流手段。在改善我们会员体验的推动下,我们引入了基于优先级的逐步负载分流技术。
下面的动图展示的是,当后端根据优先级对流量进行限制时,访客的行为情况。当优先级较低的请求被限制时,回放体验仍然流畅,访客仍可以观看节目。下面我们就探讨一下我们是怎么做到这一点的。
文章插图
后台在恢复的时候用户体验大部分仍不受影响
失败的发生可能有多种原因,例如:行为异常的客户端会触发重试风暴,后端的服务规模不足,部署不正确,网络出现故障或云提供商出现问题。考虑到这些事件,我们着手使Netflix在以下目标上更具弹性:
有很多原因可能会导致失败,比方说:客户端行为不当引发重试风暴,后台服务伸缩能力不足,部署不当,网络故障,或者云供应商的问题等等。所有这些故障可能会使系统承受意外负载,在过去,这些例子的每一个都曾一度让我们的会员丧失了播放的能力。为了防止此类突发事件的发生,我们开始着手让Netflix更具弹性,我们要考虑实现的目标包括:
- 跨设备类型(移动、浏览器和电视)一致的请求优先排序
- 基于优先级逐步限制请求
- 通过对特定优先级的请求进行混沌测试(Chaos Testing,故意注入故障)来验证假设
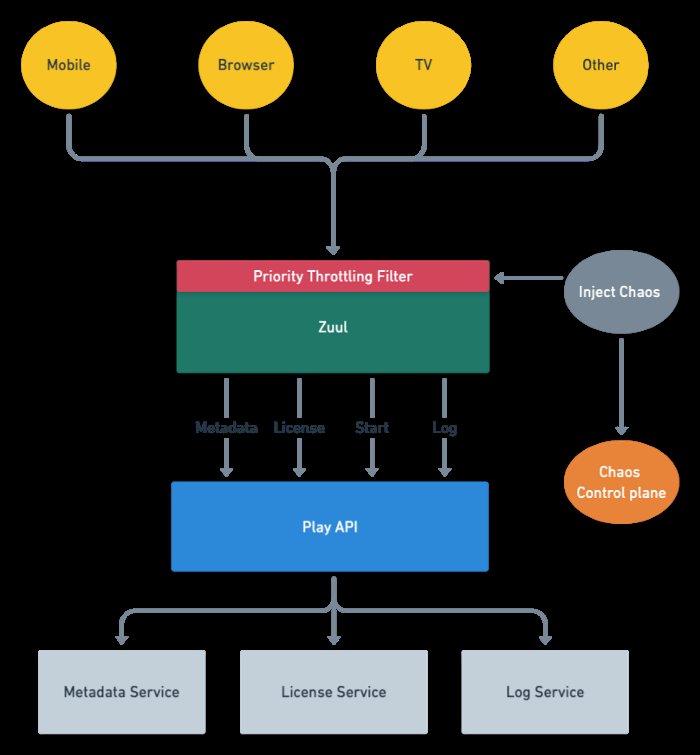
文章插图
具备按优先级限流和混沌测试的高级回放架构
建立请求分类为了对请求的流量进行分类,我们决定聚焦在三个方面:吞吐量,功能性以及关键性。基于这些特征,流量可分为以下几种:
- NON_CRITICAL(非关键):此类流量不会影响播放或者会员体验。此类流量的例子包括日志和后台请求。这种请求往往吞吐量很高,在系统负载来源当中占据了相当大的比例。
- DEGRADED_EXPERIENCE(体验降级):这种流量会影响会员的体验,但不会影响播放的能力。这类一般用于以下功能:停止和暂停标记,播放器的语言选择,观看历史记录等。
- CRITICAL(关键):此类流量会影响播放功能。如果请求失败,会员在点击播放时会看到一条错误消息。
API网关服务(Zuul)会根据请求的属性,将其分为NON_CRITICAL、DEGRADED_EXPERIENCE以及CRITICAL,并根据每个请求的特征,计算其优先级得分(1到100)。计算是请求生命周期的第一步,后续步骤要用到。
大多数情况下,请求工作流程会正常进行,而不会考虑请求优先级。但是,与任何服务一样,有时我们遇到一个后端出现问题或Zuul本身出现问题的情况。当发生这种情况时,具有较高优先级的请求将得到优先处理。优先级较高的请求将得到满足,而优先级较低的请求将不会得到响应。该实现类似于具有动态优先级阈值的优先级队列。这允许Zuul丢弃优先级低于当前阈值的请求。
- 技术|做“视频”绿厂是专业的,这项技术获人民日报评论点赞
- 中国|浅谈5G移动通信技术的前世和今生
- 速度|华为P50Pro或采用很吓人的拍照技术:液体镜头让对焦速度更快
- 视频社会生产力报告|视频社会雏形已成,绿厂或凭这技术抢占先机
- 职工组一等|全国人工智能应用技术技能大赛落幕 青岛四名选手获一等奖
- 中国视频|人日评论点赞!OPPO成视频手机先行者,新技术或下月发布
- 介绍|5分钟介绍各种类型的人工智能技术
- 重庆市工业互联网技术创新战略联盟:构建万物互联智能工厂 助力先进制造发展
- 技术|广东省电线电缆标准化技术委员会(第二届)成立
- UWB|不得不知的汽车连接技术