Jupyter Notebook和Git版本管理无缝集成
Jupyter Notebook是一个强大的在线交互式编程平台 , 还是一种强大的文档处理平台 。 使用Jupyter Notebook制作教程和其他文档的方式非常方便 , 尤其是在文档编辑、代码处理和执行结果的交叉展现;对图形以及LaTeX编码的格式和公式处理也提供了很好的支持 。 甚至可以用来生成文档 , PPT展现等 。
但是Jupyter Notebook存在不必要的运行时缓存数据在于Git集成时会造成差异干扰 。 本文我们介绍一种通过jq单行脚本快速处理 , 并制作成强大的git clean fileter , 实现从Jupyter Notebook文件中删除不需要的缓存数据来实现Jupyter Notebook和Git的无缝集成 。 文章插图
文章插图
缘起强大的Jupyter Notebook给我们使用带来便利 , 其基于.ipynb的项目保存和导入是个非常好的功能 , 可以让我们重现 , 以及和别人分享操作和界面 。 但是其基于所见即所得的编辑器存在一个一直以来共性的问题:其文档文件往往包含的内容不止是文本 , 因此很难用基于纯文本管理的版本控制工具处理 。 Jupyter 本身的.ipynb格式与纯文本格式的差异也不太大 , ipynb格式只一种自定义的JSON数据结构 , 偶尔还有嵌入的对图像和其他二进制数据base-64编码的blob数据 。 按理来说 , Git之类的VCS处理他们是绰绰有余的 。 但是其中base-64编码的blob数据较长时对其git diff比较变化差异时候就是个问题 。 尤其是需要多人协作的一个变化频繁的项目就是个很棘手的问题 。
当然可以使用手动方法:在提交Notebook之前 , 可以通过手动单击"单元格"->"所有输出"->"清除" 。 然后保存工作 。 这样存档中就不会有单元格的输出(绘图 , 打印等)的非文本记录 。
这样做的一个问题就是 , 下次导入再运行时候需要重新运行所有计算过程 , 比较耗时费力 , 我们需要费心地打开最近重新运行的各个Notebook , 提交之前清除 , 然后保存 。
这样做 , 也不能完全解决"文件差异噪声"的问题 , 因为每个Notebook 还包含一个"元数据"部分 , 比如下面就是个元数据的示例:
{ "metadata": {
"kernelspec": {
"display_name": "Python 2",
"language": "python",
"name": "python2"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 2
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython2",
"version": "2.7.12"
}
如上元数据部分实际上是一块空白模版 。 元数据具有多种可能的用途 , 但对于大多数用户而言 , 它仅包含上述内容 。 它对于检查以前运行的Notebook环境很有用 , 但在将项目运行在Python版本有差异的多用户环境时 , 该数据是不必要的信息 , 而且会对项目文件差异产生干扰 。
解决方案为了解决差异的问题 , 需要额外引入工具 。 实际上有一些Python项目专门处理Jupyter Notebook的内容差异的问题 。
nbdime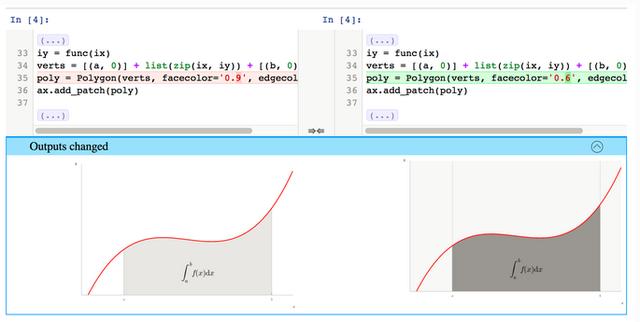 文章插图
文章插图
首先要介绍的是nbdime , 它源于nbdiff项目(已经停止) , 提供对Jupyter Notebook的内容做差异比较和合并的工具 。 nbdime很有潜力成为对初学者友好的通用型Notebook处理工具 , 但截止当前 , 它还只是测试版本 , 而仅仅可用来查看Notebook内容的差异 , 无法用来清除输出信息导致差异噪声的问题 。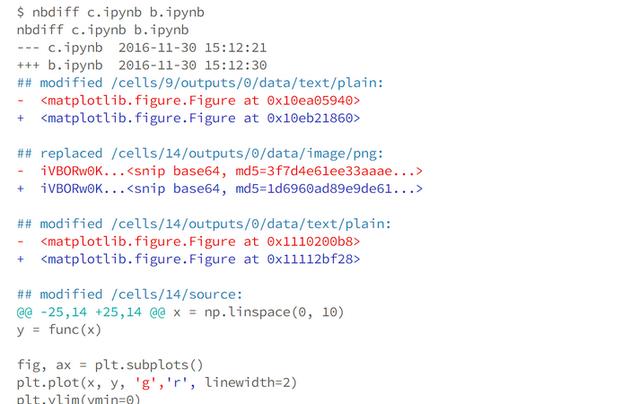 文章插图
文章插图
nbstripout另一个需要提及的工具是nbstripout , 它是一个包含nbformat处理功能的单模块Python脚本 , 并添加了一些用于设置git config的自动选项 。 可以解决上述手工"清除所有输出"的过程 , 使其自动化 。 但是它也无法解决 "元数据"差异噪声干扰的问题 。 手动运行脚本并希望有短暂的延迟是可以接受的 , 但是需要将它集成到git设置中 , 这是nbstripout性能问题就很突出 , 导致在运行git diff时会有无法忍受的延迟 。
JQ幸运的是 , 还有另外的选择 。 由于nbformat只是JSON , 一个可以使用"轻量级且灵活的命令行JSON处理器"jq , (相当于JSON数据的sed) 。 由于jq有其自己的查询/过滤器语言 , 设置方便 , 文档丰富 。 一个jq处理nbformat的示例:
jq --indent 1 \
'(.cells[] | select(has("outputs")) | .outputs) = []
| (.cells[] | select(has("execution_count")) | .execution_count) = null
| .metadata = http://kandian.youth.cn/index/{"language_info": {"name":"python", "pygments_lexer": "ipython3"}}
| .cells[].metadata = http://kandian.youth.cn/index/{}
- 中国|浅谈5G移动通信技术的前世和今生
- 芯片|华米GTS2mini和红米手表哪个好 参数功能配置对比
- 桌面|日常使用的软件及网站分享 篇一:几个动态壁纸软件和静态壁纸网站:助你美化你的桌面
- 二维码|村网通?澳大利亚一州推出疫情追踪二维码 还考虑采用人脸识别和地理定位
- 不到|苹果赚了多少?iPhone12成本不到2500元,华为和小米的利润呢?
- 机器人|网络里面的假消息忽悠了非常多的小喷子和小机器人
- 华为|骁龙870和骁龙855区别都是7nm芯片吗 性能对比评测
- 花15.5亿元与中粮包装握手言和 加多宝离上市又进一步?|15楼财经 | 清远加多宝
- 和谐|人民日报海外版今日聚焦云南西双版纳 看科技如何助力人象和谐
- 内容|浅谈内容行业的一些规律和壁垒,聊聊电商平台孵化小红书难点(外部原因)